 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagarela - A Portuguese speech dataset from podcasts
Mar 16, 2026Despite significant advances in speech processing, Portuguese remains under-resourced due to the scarcity of public, large-scale, and high-quality datasets. To address this gap, we present a new dataset, named TAGARELA, composed of over 8,972 hours of podcast audio, specifically curated for training automatic speech recognition (ASR) and text-to-speech (TTS) models. Notably, its scale rivals English's GigaSpeech (10kh), enabling state-of-the-art Portuguese models. To ensure data quality, the corpus was subjected to an audio pre-processing pipeline and subsequently transcribed using a mixed strategy: we applied ASR models that were previously trained on high-fidelity transcriptions generated by proprietary APIs, ensuring a high level of initial accuracy. Finally, to validate the effectiveness of this new resource, we present ASR and TTS models trained exclusively on our dataset and evaluate their performance, demonstrating its potential to drive the development of more robust and natural speech technologies for Portuguese. The dataset is released publicly, available at https://freds0.github.io/TAGARELA/, to foster the development of robust speech technologies.
FreeSVC: Towards Zero-shot Multilingual Singing Voice Conversion
Jan 09, 2025This work presents FreeSVC, a promising multilingual singing voice conversion approach that leverages an enhanced VITS model with Speaker-invariant Clustering (SPIN) for better content representation and the State-of-the-Art (SOTA) speaker encoder ECAPA2. FreeSVC incorporates trainable language embeddings to handle multiple languages and employs an advanced speaker encoder to disentangle speaker characteristics from linguistic content. Designed for zero-shot learning, FreeSVC enables cross-lingual singing voice conversion without extensive language-specific training. We demonstrate that a multilingual content extractor is crucial for optimal cross-language conversion. Our source code and models are publicly available.
Domain Specific Wav2vec 2.0 Fine-tuning For The SE&R 2022 Challenge
Jul 29, 2022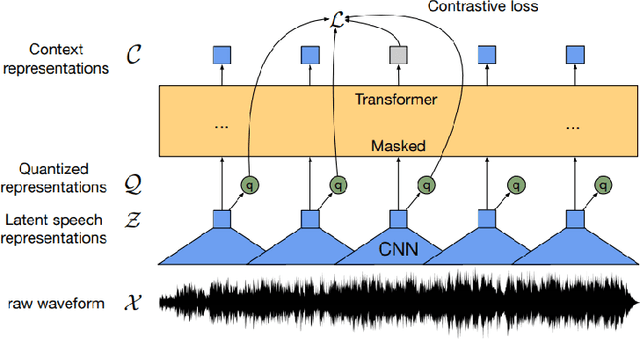

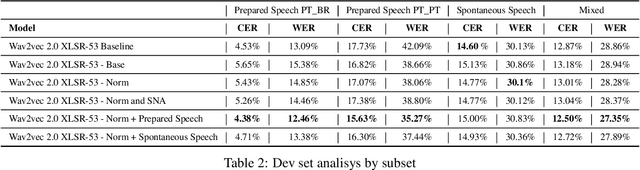

This paper presents our efforts to build a robust ASR model for the shared task Automatic Speech Recognition for spontaneous and prepared speech & Speech Emotion Recognition in Portuguese (SE&R 2022). The goal of the challenge is to advance the ASR research for the Portuguese language, considering prepared and spontaneous speech in different dialects. Our method consist on fine-tuning an ASR model in a domain-specific approach, applying gain normalization and selective noise insertion. The proposed method improved over the strong baseline provided on the test set in 3 of the 4 tracks available