 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagarela - A Portuguese speech dataset from podcasts
Mar 16, 2026Despite significant advances in speech processing, Portuguese remains under-resourced due to the scarcity of public, large-scale, and high-quality datasets. To address this gap, we present a new dataset, named TAGARELA, composed of over 8,972 hours of podcast audio, specifically curated for training automatic speech recognition (ASR) and text-to-speech (TTS) models. Notably, its scale rivals English's GigaSpeech (10kh), enabling state-of-the-art Portuguese models. To ensure data quality, the corpus was subjected to an audio pre-processing pipeline and subsequently transcribed using a mixed strategy: we applied ASR models that were previously trained on high-fidelity transcriptions generated by proprietary APIs, ensuring a high level of initial accuracy. Finally, to validate the effectiveness of this new resource, we present ASR and TTS models trained exclusively on our dataset and evaluate their performance, demonstrating its potential to drive the development of more robust and natural speech technologies for Portuguese. The dataset is released publicly, available at https://freds0.github.io/TAGARELA/, to foster the development of robust speech technologies.
MedPT: A Massive Medical Question Answering Dataset for Brazilian-Portuguese Speakers
Nov 14, 2025While large language models (LLMs) show transformative potential in healthcare, their development remains focused on high-resource languages, creating a critical barrier for others as simple translation fails to capture unique clinical and cultural nuances, such as endemic diseases. To address this, we introduce MedPT, the first large-scale, real-world corpus for Brazilian Portuguese, comprising 384,095 authentic question-answer pairs from patient-doctor interactions. The dataset underwent a meticulous multi-stage curation protocol, using a hybrid quantitative-qualitative analysis to filter noise and contextually enrich thousands of ambiguous queries. We further augmented the corpus via LLM-driven annotation, classifying questions into seven semantic types to capture user intent. Our analysis reveals its thematic breadth (3,200 topics) and unique linguistic properties, like the natural asymmetry in patient-doctor communication. To validate its utility, we benchmark a medical specialty routing task: fine-tuning a 1.7B parameter model achieves an outstanding 94\% F1-score on a 20-class setup. Furthermore, our qualitative error analysis shows misclassifications are not random but reflect genuine clinical ambiguities (e.g., between comorbid conditions), proving the dataset's deep semantic richness. We publicly release MedPT to foster the development of more equitable, accurate, and culturally-aware medical technologies for the Portuguese-speaking world.
FreeSVC: Towards Zero-shot Multilingual Singing Voice Conversion
Jan 09, 2025This work presents FreeSVC, a promising multilingual singing voice conversion approach that leverages an enhanced VITS model with Speaker-invariant Clustering (SPIN) for better content representation and the State-of-the-Art (SOTA) speaker encoder ECAPA2. FreeSVC incorporates trainable language embeddings to handle multiple languages and employs an advanced speaker encoder to disentangle speaker characteristics from linguistic content. Designed for zero-shot learning, FreeSVC enables cross-lingual singing voice conversion without extensive language-specific training. We demonstrate that a multilingual content extractor is crucial for optimal cross-language conversion. Our source code and models are publicly available.
No Saved Kaleidosope: an 100% Jitted Neural Network Coding Language with Pythonic Syntax
Sep 17, 2024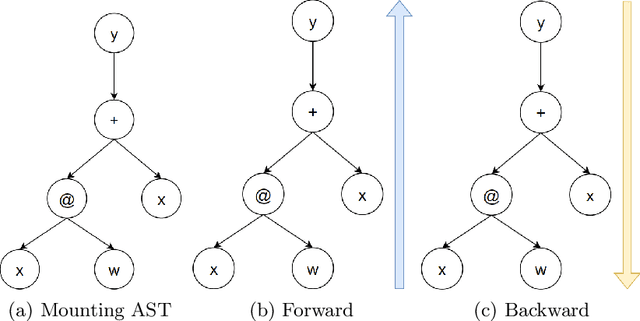

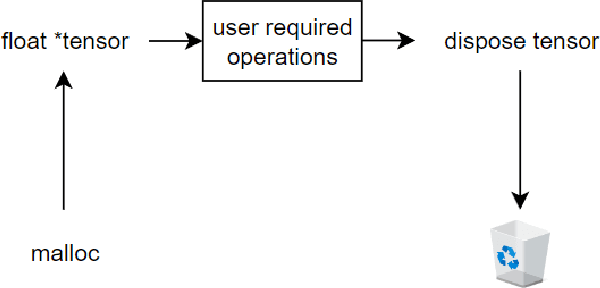
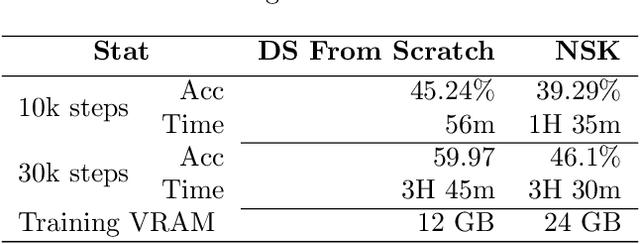
We developed a jitted compiler for training Artificial Neural Networks using C++, LLVM and Cuda. It features object-oriented characteristics, strong typing, parallel workers for data pre-processing, pythonic syntax for expressions, PyTorch like model declaration and Automatic Differentiation. We implement the mechanisms of cache and pooling in order to manage VRAM, cuBLAS for high performance matrix multiplication and cuDNN for convolutional layers. Our experiments with Residual Convolutional Neural Networks on ImageNet, we reach similar speed but degraded performance. Also, the GRU network experiments show similar accuracy, but our compiler have degraded speed in that task. However, our compiler demonstrates promising results at the CIFAR-10 benchmark, in which we reach the same performance and about the same speed as PyTorch. We make the code publicly available at: https://github.com/NoSavedDATA/NoSavedKaleidoscope
Araguaia Medical Vision Lab at ISIC 2017 Skin Lesion Classification Challenge
Mar 02, 2017This paper describes the participation of Araguaia Medical Vision Lab at the International Skin Imaging Collaboration 2017 Skin Lesion Challenge. We describe the use of deep convolutional neural networks in attempt to classify images of Melanoma and Seborrheic Keratosis lesions. With use of finetuned GoogleNet and AlexNet we attained results of 0.950 and 0.846 AUC on Seborrheic Keratosis and Melanoma respectively.