 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeSVC: Towards Zero-shot Multilingual Singing Voice Conversion
Jan 09, 2025This work presents FreeSVC, a promising multilingual singing voice conversion approach that leverages an enhanced VITS model with Speaker-invariant Clustering (SPIN) for better content representation and the State-of-the-Art (SOTA) speaker encoder ECAPA2. FreeSVC incorporates trainable language embeddings to handle multiple languages and employs an advanced speaker encoder to disentangle speaker characteristics from linguistic content. Designed for zero-shot learning, FreeSVC enables cross-lingual singing voice conversion without extensive language-specific training. We demonstrate that a multilingual content extractor is crucial for optimal cross-language conversion. Our source code and models are publicly available.
No Saved Kaleidosope: an 100% Jitted Neural Network Coding Language with Pythonic Syntax
Sep 17, 2024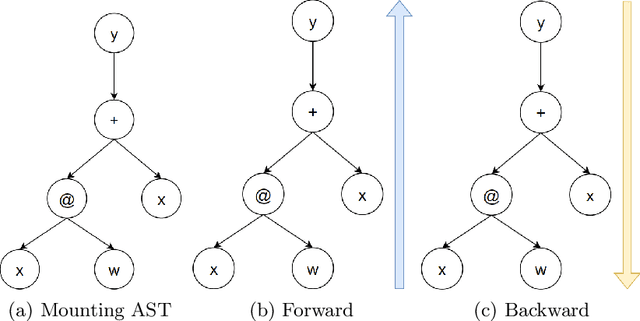

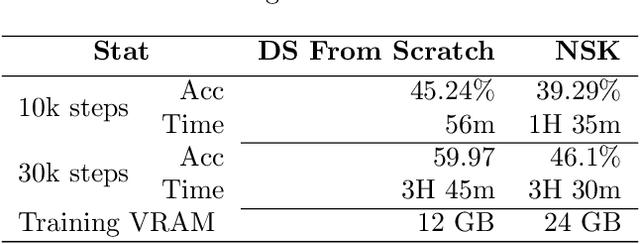
We developed a jitted compiler for training Artificial Neural Networks using C++, LLVM and Cuda. It features object-oriented characteristics, strong typing, parallel workers for data pre-processing, pythonic syntax for expressions, PyTorch like model declaration and Automatic Differentiation. We implement the mechanisms of cache and pooling in order to manage VRAM, cuBLAS for high performance matrix multiplication and cuDNN for convolutional layers. Our experiments with Residual Convolutional Neural Networks on ImageNet, we reach similar speed but degraded performance. Also, the GRU network experiments show similar accuracy, but our compiler have degraded speed in that task. However, our compiler demonstrates promising results at the CIFAR-10 benchmark, in which we reach the same performance and about the same speed as PyTorch. We make the code publicly available at: https://github.com/NoSavedDATA/NoSavedKaleidoscope