 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCML-TTS A Multilingual Dataset for Speech Synthesis in Low-Resource Languages
Jun 16, 2023In this paper, we present CML-TTS, a recursive acronym for CML-Multi-Lingual-TTS, a new Text-to-Speech (TTS) dataset developed at the Center of Excellence in Artificial Intelligence (CEIA) of the Federal University of Goias (UFG). CML-TTS is based on Multilingual LibriSpeech (MLS) and adapted for training TTS models, consisting of audiobooks in seven languages: Dutch, French, German, Italian, Portuguese, Polish, and Spanish. Additionally, we provide the YourTTS model, a multi-lingual TTS model, trained using 3,176.13 hours from CML-TTS and also with 245.07 hours from LibriTTS, in English. Our purpose in creating this dataset is to open up new research possibilities in the TTS area for multi-lingual models. The dataset is publicly available under the CC-BY 4.0 license1.
Evaluation of Speech Representations for MOS prediction
Jun 16, 2023



In this paper, we evaluate feature extraction models for predicting speech quality. We also propose a model architecture to compare embeddings of supervised learning and self-supervised learning models with embeddings of speaker verification models to predict the metric MOS. Our experiments were performed on the VCC2018 dataset and a Brazilian-Portuguese dataset called BRSpeechMOS, which was created for this work. The results show that the Whisper model is appropriate in all scenarios: with both the VCC2018 and BRSpeech- MOS datasets. Among the supervised and self-supervised learning models using BRSpeechMOS, Whisper-Small achieved the best linear correlation of 0.6980, and the speaker verification model, SpeakerNet, had linear correlation of 0.6963. Using VCC2018, the best supervised and self-supervised learning model, Whisper-Large, achieved linear correlation of 0.7274, and the best model speaker verification, TitaNet, achieved a linear correlation of 0.6933. Although the results of the speaker verification models are slightly lower, the SpeakerNet model has only 5M parameters, making it suitable for real-time applications, and the TitaNet model produces an embedding of size 192, the smallest among all the evaluated models. The experiment results are reproducible with publicly available source-code1 .
Improving Irregularly Sampled Time Series Learning with Dense Descriptors of Time
Mar 20, 2020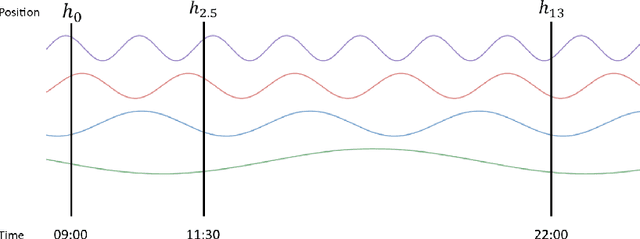

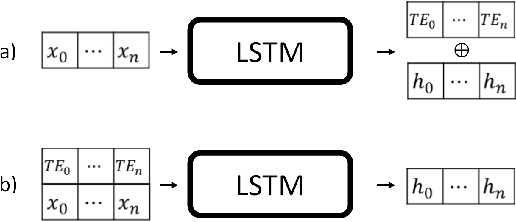
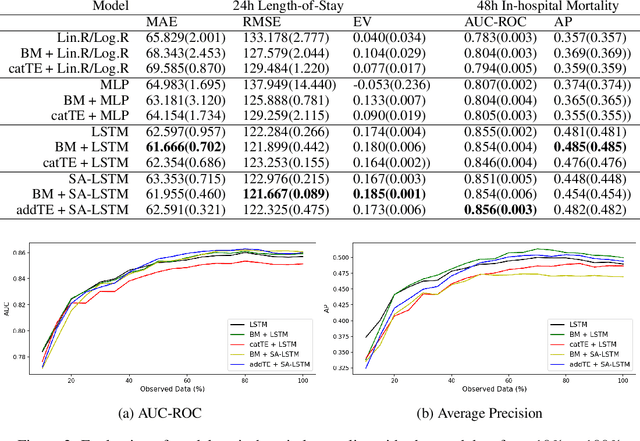
Supervised learning with irregularly sampled time series have been a challenge to Machine Learning methods due to the obstacle of dealing with irregular time intervals. Some papers introduced recently recurrent neural network models that deals with irregularity, but most of them rely on complex mechanisms to achieve a better performance. This work propose a novel method to represent timestamps (hours or dates) as dense vectors using sinusoidal functions, called Time Embeddings. As a data input method it and can be applied to most machine learning models. The method was evaluated with two predictive tasks from MIMIC III, a dataset of irregularly sampled time series of electronic health records. Our tests showed an improvement to LSTM-based and classical machine learning models, specially with very irregular data.
Predicting Diabetes Disease Evolution Using Financial Records and Recurrent Neural Networks
Nov 23, 2018
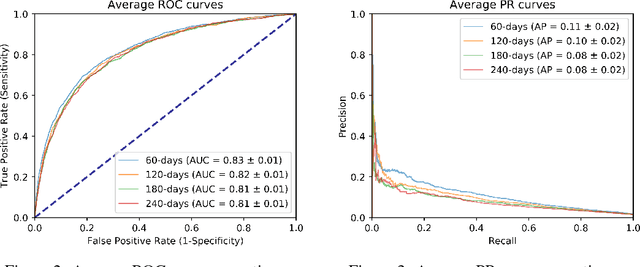
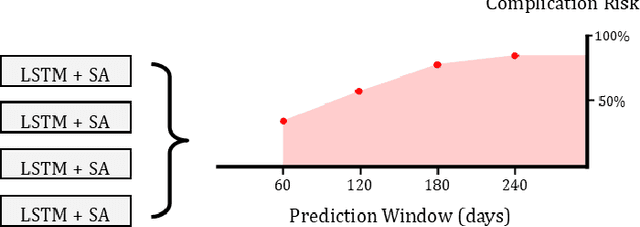
Managing patients with chronic diseases is a major and growing healthcare challenge in several countries. A chronic condition, such as diabetes, is an illness that lasts a long time and does not go away, and often leads to the patient's health gradually getting worse. While recent works involve raw electronic health record (EHR) from hospitals, this work uses only financial records from health plan providers to predict diabetes disease evolution with a self-attentive recurrent neural network. The use of financial data is due to the possibility of being an interface to international standards, as the records standard encodes medical procedures. The main goal was to assess high risk diabetics, so we predict records related to diabetes acute complications such as amputations and debridements, revascularization and hemodialysis. Our work succeeds to anticipate complications between 60 to 240 days with an area under ROC curve ranging from 0.81 to 0.94. In this paper we describe the first half of a work-in-progress developed within a health plan provider with ROC curve ranging from 0.81 to 0.83. This assessment will give healthcare providers the chance to intervene earlier and head off hospitalizations. We are aiming to deliver personalized predictions and personalized recommendations to individual patients, with the goal of improving outcomes and reducing costs