 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinning Complex Networked Systems: Data-Driven Calibration of the mABCD Synthetic Graph Generator
Feb 02, 2026The increasing availability of relational data has contributed to a growing reliance on network-based representations of complex systems. Over time, these models have evolved to capture more nuanced properties, such as the heterogeneity of relationships, leading to the concept of multilayer networks. However, the analysis and evaluation of methods for these structures is often hindered by the limited availability of large-scale empirical data. As a result, graph generators are commonly used as a workaround, albeit at the cost of introducing systematic biases. In this paper, we address the inverse-generator problem by inferring the configuration parameters of a multilayer network generator, mABCD, from a real-world system. Our goal is to identify parameter settings that enable the generator to produce synthetic networks that act as digital twins of the original structure. We propose a method for estimating matching configurations and for quantifying the associated error. Our results demonstrate that this task is non-trivial, as strong interdependencies between configuration parameters weaken independent estimation and instead favour a joint-prediction approach.
Identifying Super Spreaders in Multilayer Networks
May 27, 2025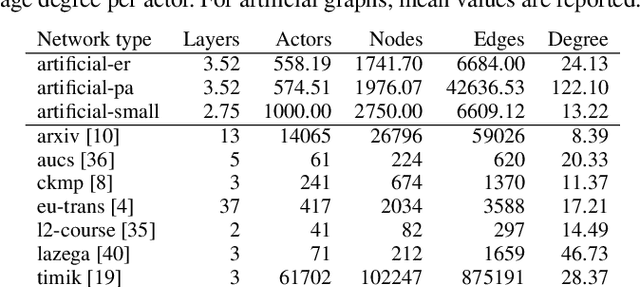
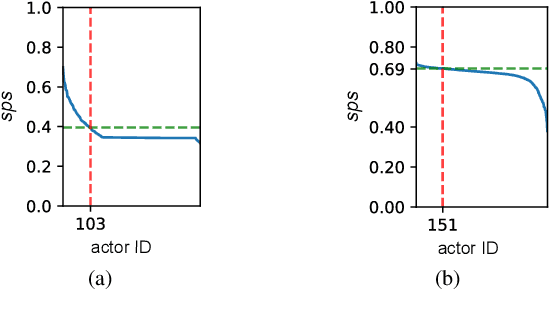

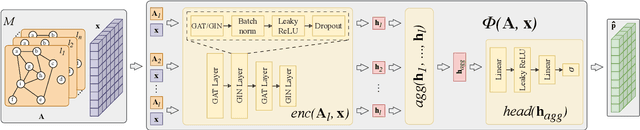
Identifying super-spreaders can be framed as a subtask of the influence maximisation problem. It seeks to pinpoint agents within a network that, if selected as single diffusion seeds, disseminate information most effectively. Multilayer networks, a specific class of heterogeneous graphs, can capture diverse types of interactions (e.g., physical-virtual or professional-social), and thus offer a more accurate representation of complex relational structures. In this work, we introduce a novel approach to identifying super-spreaders in such networks by leveraging graph neural networks. To this end, we construct a dataset by simulating information diffusion across hundreds of networks - to the best of our knowledge, the first of its kind tailored specifically to multilayer networks. We further formulate the task as a variation of the ranking prediction problem based on a four-dimensional vector that quantifies each agent's spreading potential: (i) the number of activations; (ii) the duration of the diffusion process; (iii) the peak number of activations; and (iv) the simulation step at which this peak occurs. Our model, TopSpreadersNetwork, comprises a relationship-agnostic encoder and a custom aggregation layer. This design enables generalisation to previously unseen data and adapts to varying graph sizes. In an extensive evaluation, we compare our model against classic centrality-based heuristics and competitive deep learning methods. The results, obtained across a broad spectrum of real-world and synthetic multilayer networks, demonstrate that TopSpreadersNetwork achieves superior performance in identifying high-impact nodes, while also offering improved interpretability through its structured output.
Improved DeepFake Detection Using Whisper Features
Jun 02, 2023



With a recent influx of voice generation methods, the threat introduced by audio DeepFake (DF) is ever-increasing. Several different detection methods have been presented as a countermeasure. Many methods are based on so-called front-ends, which, by transforming the raw audio, emphasize features crucial for assessing the genuineness of the audio sample. Our contribution contains investigating the influence of the state-of-the-art Whisper automatic speech recognition model as a DF detection front-end. We compare various combinations of Whisper and well-established front-ends by training 3 detection models (LCNN, SpecRNet, and MesoNet) on a widely used ASVspoof 2021 DF dataset and later evaluating them on the DF In-The-Wild dataset. We show that using Whisper-based features improves the detection for each model and outperforms recent results on the In-The-Wild dataset by reducing Equal Error Rate by 21%.