 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinning Complex Networked Systems: Data-Driven Calibration of the mABCD Synthetic Graph Generator
Feb 02, 2026The increasing availability of relational data has contributed to a growing reliance on network-based representations of complex systems. Over time, these models have evolved to capture more nuanced properties, such as the heterogeneity of relationships, leading to the concept of multilayer networks. However, the analysis and evaluation of methods for these structures is often hindered by the limited availability of large-scale empirical data. As a result, graph generators are commonly used as a workaround, albeit at the cost of introducing systematic biases. In this paper, we address the inverse-generator problem by inferring the configuration parameters of a multilayer network generator, mABCD, from a real-world system. Our goal is to identify parameter settings that enable the generator to produce synthetic networks that act as digital twins of the original structure. We propose a method for estimating matching configurations and for quantifying the associated error. Our results demonstrate that this task is non-trivial, as strong interdependencies between configuration parameters weaken independent estimation and instead favour a joint-prediction approach.
A Multi-purposed Unsupervised Framework for Comparing Embeddings of Undirected and Directed Graphs
Nov 30, 2021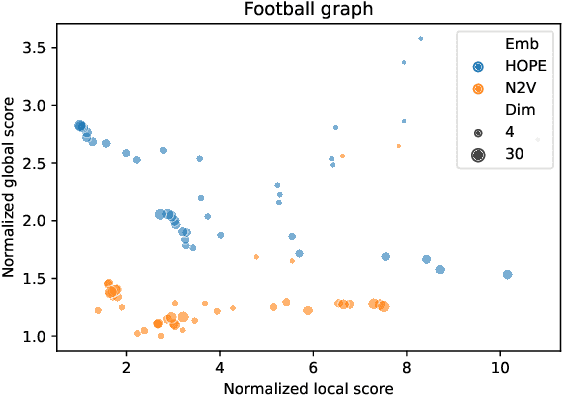
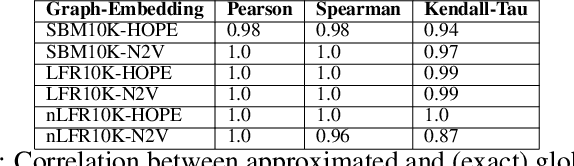

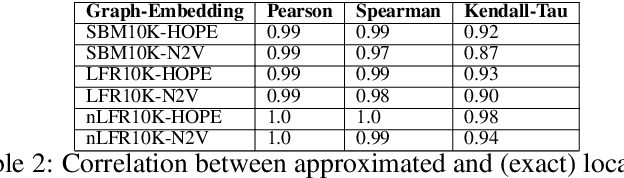
Graph embedding is a transformation of nodes of a network into a set of vectors. A good embedding should capture the underlying graph topology and structure, node-to-node relationship, and other relevant information about the graph, its subgraphs, and nodes themselves. If these objectives are achieved, an embedding is a meaningful, understandable, and often compressed representation of a network. Unfortunately, selecting the best embedding is a challenging task and very often requires domain experts. In this paper, we extend the framework for evaluating graph embeddings that was recently introduced by the authors. Now, the framework assigns two scores, local and global, to each embedding that measure the quality of an evaluated embedding for tasks that require good representation of local and, respectively, global properties of the network. The best embedding, if needed, can be selected in an unsupervised way, or the framework can identify a few embeddings that are worth further investigation. The framework is flexible, scalable, and can deal with undirected/directed, weighted/unweighted graphs.
Evaluating Node Embeddings of Complex Networks
Feb 16, 2021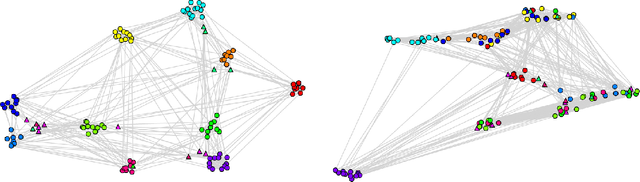
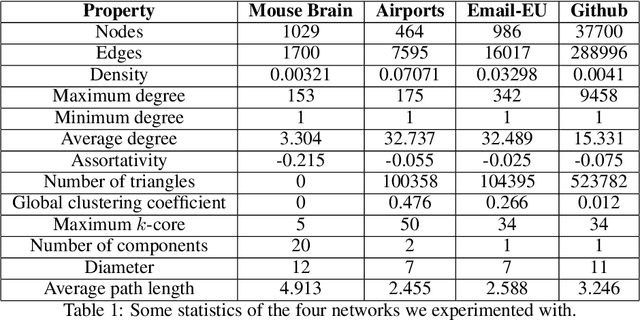
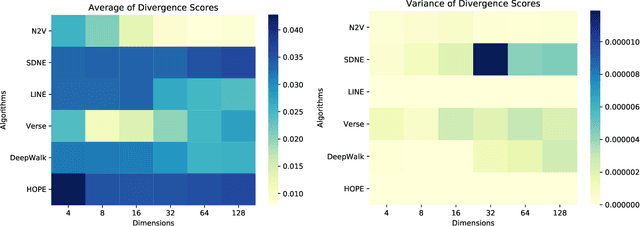
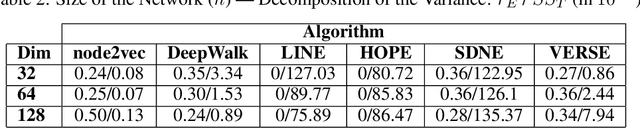
Graph embedding is a transformation of nodes of a graph into a set of vectors. A~good embedding should capture the graph topology, node-to-node relationship, and other relevant information about the graph, its subgraphs, and nodes. If these objectives are achieved, an embedding is a meaningful, understandable, compressed representations of a network that can be used for other machine learning tools such as node classification, community detection, or link prediction. The main challenge is that one needs to make sure that embeddings describe the properties of the graphs well. As a result, selecting the best embedding is a challenging task and very often requires domain experts. In this paper, we do a series of extensive experiments with selected graph embedding algorithms, both on real-world networks as well as artificially generated ones. Based on those experiments we formulate two general conclusions. First, if one needs to pick one embedding algorithm before running the experiments, then node2vec is the best choice as it performed best in our tests. Having said that, there is no single winner in all tests and, additionally, most embedding algorithms have hyperparameters that should be tuned and are randomized. Therefore, our main recommendation for practitioners is, if possible, to generate several embeddings for a problem at hand and then use a general framework that provides a tool for an unsupervised graph embedding comparison. This framework (introduced recently in the literature and easily available on GitHub repository) assigns the divergence score to embeddings to help distinguish good ones from bad ones.