 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Node Embeddings of Complex Networks
Feb 16, 2021
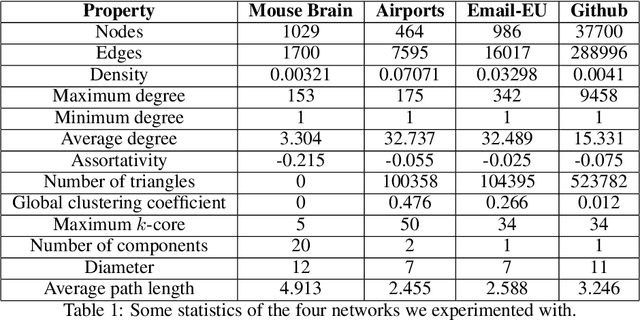
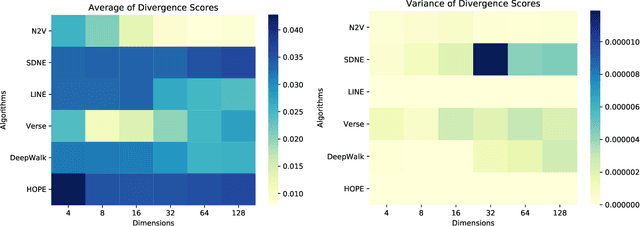
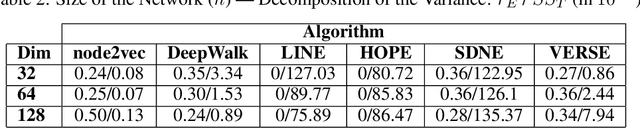
Graph embedding is a transformation of nodes of a graph into a set of vectors. A~good embedding should capture the graph topology, node-to-node relationship, and other relevant information about the graph, its subgraphs, and nodes. If these objectives are achieved, an embedding is a meaningful, understandable, compressed representations of a network that can be used for other machine learning tools such as node classification, community detection, or link prediction. The main challenge is that one needs to make sure that embeddings describe the properties of the graphs well. As a result, selecting the best embedding is a challenging task and very often requires domain experts. In this paper, we do a series of extensive experiments with selected graph embedding algorithms, both on real-world networks as well as artificially generated ones. Based on those experiments we formulate two general conclusions. First, if one needs to pick one embedding algorithm before running the experiments, then node2vec is the best choice as it performed best in our tests. Having said that, there is no single winner in all tests and, additionally, most embedding algorithms have hyperparameters that should be tuned and are randomized. Therefore, our main recommendation for practitioners is, if possible, to generate several embeddings for a problem at hand and then use a general framework that provides a tool for an unsupervised graph embedding comparison. This framework (introduced recently in the literature and easily available on GitHub repository) assigns the divergence score to embeddings to help distinguish good ones from bad ones.