 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Super Spreaders in Multilayer Networks
May 27, 2025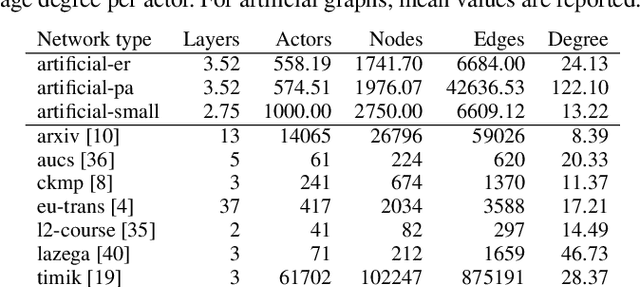
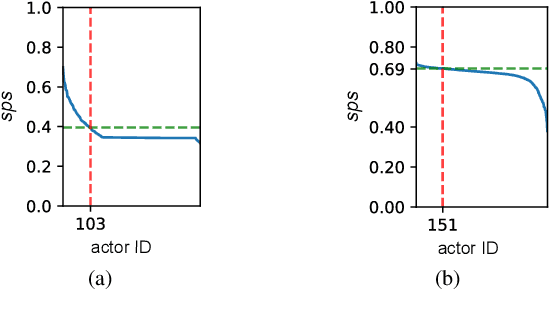

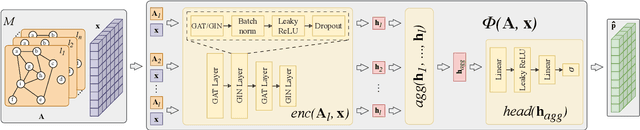
Identifying super-spreaders can be framed as a subtask of the influence maximisation problem. It seeks to pinpoint agents within a network that, if selected as single diffusion seeds, disseminate information most effectively. Multilayer networks, a specific class of heterogeneous graphs, can capture diverse types of interactions (e.g., physical-virtual or professional-social), and thus offer a more accurate representation of complex relational structures. In this work, we introduce a novel approach to identifying super-spreaders in such networks by leveraging graph neural networks. To this end, we construct a dataset by simulating information diffusion across hundreds of networks - to the best of our knowledge, the first of its kind tailored specifically to multilayer networks. We further formulate the task as a variation of the ranking prediction problem based on a four-dimensional vector that quantifies each agent's spreading potential: (i) the number of activations; (ii) the duration of the diffusion process; (iii) the peak number of activations; and (iv) the simulation step at which this peak occurs. Our model, TopSpreadersNetwork, comprises a relationship-agnostic encoder and a custom aggregation layer. This design enables generalisation to previously unseen data and adapts to varying graph sizes. In an extensive evaluation, we compare our model against classic centrality-based heuristics and competitive deep learning methods. The results, obtained across a broad spectrum of real-world and synthetic multilayer networks, demonstrate that TopSpreadersNetwork achieves superior performance in identifying high-impact nodes, while also offering improved interpretability through its structured output.
Identifying Key Nodes for the Influence Spread using a Machine Learning Approach
Dec 02, 2024The identification of key nodes in complex networks is an important topic in many network science areas. It is vital to a variety of real-world applications, including viral marketing, epidemic spreading and influence maximization. In recent years, machine learning algorithms have proven to outperform the conventional, centrality-based methods in accuracy and consistency, but this approach still requires further refinement. What information about the influencers can be extracted from the network? How can we precisely obtain the labels required for training? Can these models generalize well? In this paper, we answer these questions by presenting an enhanced machine learning-based framework for the influence spread problem. We focus on identifying key nodes for the Independent Cascade model, which is a popular reference method. Our main contribution is an improved process of obtaining the labels required for training by introducing 'Smart Bins' and proving their advantage over known methods. Next, we show that our methodology allows ML models to not only predict the influence of a given node, but to also determine other characteristics of the spreading process-which is another novelty to the relevant literature. Finally, we extensively test our framework and its ability to generalize beyond complex networks of different types and sizes, gaining important insight into the properties of these methods.
Snapshot Spectral Clustering -- a costless approach to deep clustering ensembles generation
Jul 17, 2023



Despite tremendous advancements in Artificial Intelligence, learning from large sets of data in an unsupervised manner remains a significant challenge. Classical clustering algorithms often fail to discover complex dependencies in large datasets, especially considering sparse, high-dimensional spaces. However, deep learning techniques proved to be successful when dealing with large quantities of data, efficiently reducing their dimensionality without losing track of underlying information. Several interesting advancements have already been made to combine deep learning and clustering. Still, the idea of enhancing the clustering results by combining multiple views of the data generated by deep neural networks appears to be insufficiently explored yet. This paper aims to investigate this direction and bridge the gap between deep neural networks, clustering techniques and ensemble learning methods. To achieve this goal, we propose a novel deep clustering ensemble method - Snapshot Spectral Clustering, designed to maximize the gain from combining multiple data views while minimizing the computational costs of creating the ensemble. Comparative analysis and experiments described in this paper prove the proposed concept, while the conducted hyperparameter study provides a valuable intuition to follow when selecting proper values.