 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPOCH: Jointly Estimating the 3D Pose of Cameras and Humans
Jun 28, 2024Monocular Human Pose Estimation (HPE) aims at determining the 3D positions of human joints from a single 2D image captured by a camera. However, a single 2D point in the image may correspond to multiple points in 3D space. Typically, the uniqueness of the 2D-3D relationship is approximated using an orthographic or weak-perspective camera model. In this study, instead of relying on approximations, we advocate for utilizing the full perspective camera model. This involves estimating camera parameters and establishing a precise, unambiguous 2D-3D relationship. To do so, we introduce the EPOCH framework, comprising two main components: the pose lifter network (LiftNet) and the pose regressor network (RegNet). LiftNet utilizes the full perspective camera model to precisely estimate the 3D pose in an unsupervised manner. It takes a 2D pose and camera parameters as inputs and produces the corresponding 3D pose estimation. These inputs are obtained from RegNet, which starts from a single image and provides estimates for the 2D pose and camera parameters. RegNet utilizes only 2D pose data as weak supervision. Internally, RegNet predicts a 3D pose, which is then projected to 2D using the estimated camera parameters. This process enables RegNet to establish the unambiguous 2D-3D relationship. Our experiments show that modeling the lifting as an unsupervised task with a camera in-the-loop results in better generalization to unseen data. We obtain state-of-the-art results for the 3D HPE on the Human3.6M and MPI-INF-3DHP datasets. Our code is available at: [Github link upon acceptance, see supplementary materials].
A Unified Simulation Framework for Visual and Behavioral Fidelity in Crowd Analysis
Dec 05, 2023


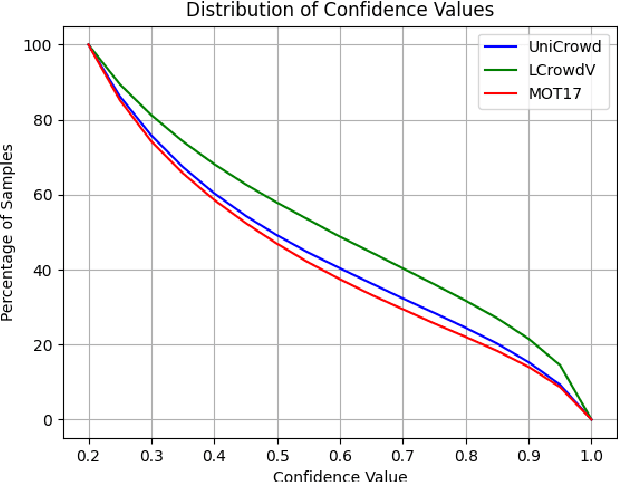
Simulation is a powerful tool to easily generate annotated data, and a highly desirable feature, especially in those domains where learning models need large training datasets. Machine learning and deep learning solutions, have proven to be extremely data-hungry and sometimes, the available real-world data are not sufficient to effectively model the given task. Despite the initial skepticism of a portion of the scientific community, the potential of simulation has been largely confirmed in many application areas, and the recent developments in terms of rendering and virtualization engines, have shown a good ability also in representing complex scenes. This includes environmental factors, such as weather conditions and surface reflectance, as well as human-related events, like human actions and behaviors. We present a human crowd simulator, called UniCrowd, and its associated validation pipeline. We show how the simulator can generate annotated data, suitable for computer vision tasks, in particular for detection and segmentation, as well as the related applications, as crowd counting, human pose estimation, trajectory analysis and prediction, and anomaly detection.
Interpretable part-whole hierarchies and conceptual-semantic relationships in neural networks
Mar 07, 2022
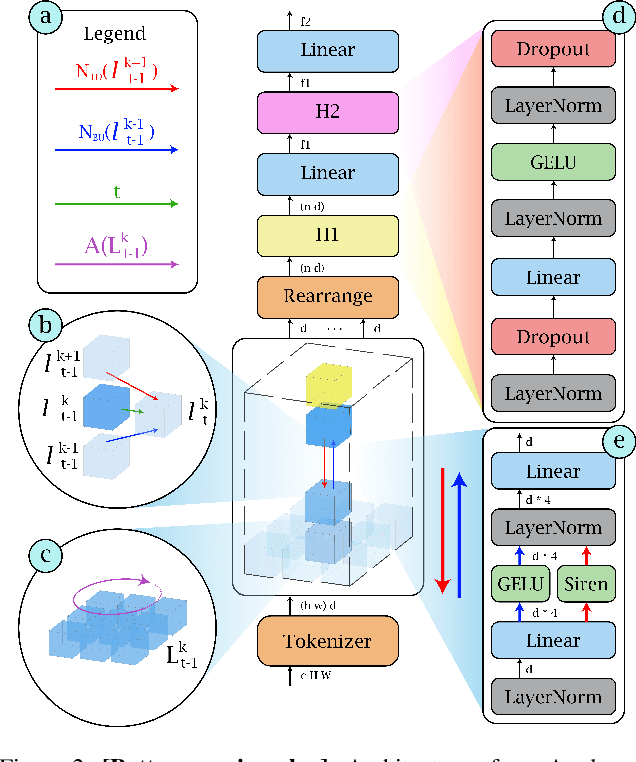
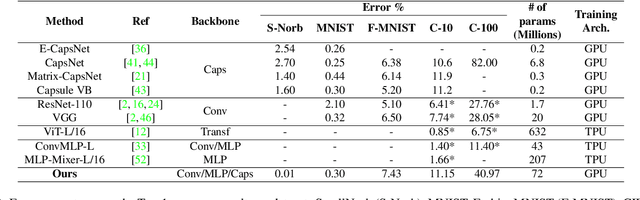
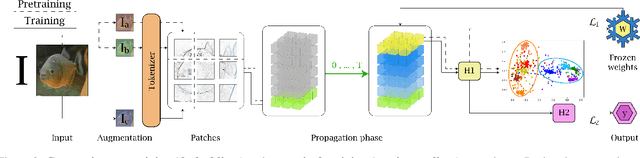
Deep neural networks achieve outstanding results in a large variety of tasks, often outperforming human experts. However, a known limitation of current neural architectures is the poor accessibility to understand and interpret the network response to a given input. This is directly related to the huge number of variables and the associated non-linearities of neural models, which are often used as black boxes. When it comes to critical applications as autonomous driving, security and safety, medicine and health, the lack of interpretability of the network behavior tends to induce skepticism and limited trustworthiness, despite the accurate performance of such systems in the given task. Furthermore, a single metric, such as the classification accuracy, provides a non-exhaustive evaluation of most real-world scenarios. In this paper, we want to make a step forward towards interpretability in neural networks, providing new tools to interpret their behavior. We present Agglomerator, a framework capable of providing a representation of part-whole hierarchies from visual cues and organizing the input distribution matching the conceptual-semantic hierarchical structure between classes. We evaluate our method on common datasets, such as SmallNORB, MNIST, FashionMNIST, CIFAR-10, and CIFAR-100, providing a more interpretable model than other state-of-the-art approaches.
DECA: Deep viewpoint-Equivariant human pose estimation using Capsule Autoencoders
Aug 19, 2021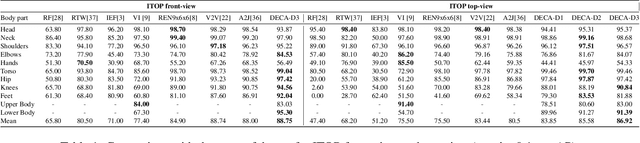
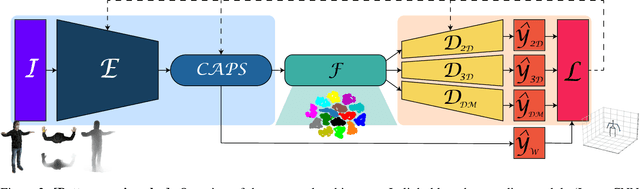
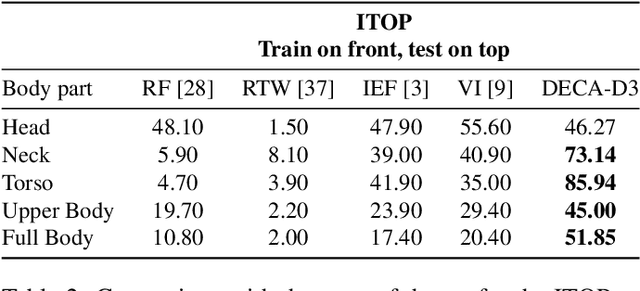
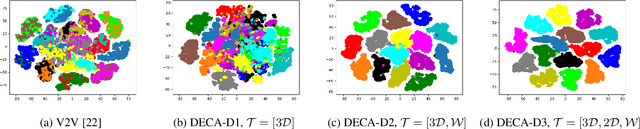
Human Pose Estimation (HPE) aims at retrieving the 3D position of human joints from images or videos. We show that current 3D HPE methods suffer a lack of viewpoint equivariance, namely they tend to fail or perform poorly when dealing with viewpoints unseen at training time. Deep learning methods often rely on either scale-invariant, translation-invariant, or rotation-invariant operations, such as max-pooling. However, the adoption of such procedures does not necessarily improve viewpoint generalization, rather leading to more data-dependent methods. To tackle this issue, we propose a novel capsule autoencoder network with fast Variational Bayes capsule routing, named DECA. By modeling each joint as a capsule entity, combined with the routing algorithm, our approach can preserve the joints' hierarchical and geometrical structure in the feature space, independently from the viewpoint. By achieving viewpoint equivariance, we drastically reduce the network data dependency at training time, resulting in an improved ability to generalize for unseen viewpoints. In the experimental validation, we outperform other methods on depth images from both seen and unseen viewpoints, both top-view, and front-view. In the RGB domain, the same network gives state-of-the-art results on the challenging viewpoint transfer task, also establishing a new framework for top-view HPE. The code can be found at https://github.com/mmlab-cv/DECA.