 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPOCH: Jointly Estimating the 3D Pose of Cameras and Humans
Jun 28, 2024Monocular Human Pose Estimation (HPE) aims at determining the 3D positions of human joints from a single 2D image captured by a camera. However, a single 2D point in the image may correspond to multiple points in 3D space. Typically, the uniqueness of the 2D-3D relationship is approximated using an orthographic or weak-perspective camera model. In this study, instead of relying on approximations, we advocate for utilizing the full perspective camera model. This involves estimating camera parameters and establishing a precise, unambiguous 2D-3D relationship. To do so, we introduce the EPOCH framework, comprising two main components: the pose lifter network (LiftNet) and the pose regressor network (RegNet). LiftNet utilizes the full perspective camera model to precisely estimate the 3D pose in an unsupervised manner. It takes a 2D pose and camera parameters as inputs and produces the corresponding 3D pose estimation. These inputs are obtained from RegNet, which starts from a single image and provides estimates for the 2D pose and camera parameters. RegNet utilizes only 2D pose data as weak supervision. Internally, RegNet predicts a 3D pose, which is then projected to 2D using the estimated camera parameters. This process enables RegNet to establish the unambiguous 2D-3D relationship. Our experiments show that modeling the lifting as an unsupervised task with a camera in-the-loop results in better generalization to unseen data. We obtain state-of-the-art results for the 3D HPE on the Human3.6M and MPI-INF-3DHP datasets. Our code is available at: [Github link upon acceptance, see supplementary materials].
Deep convolutional neural networks for pedestrian detection
Mar 07, 2016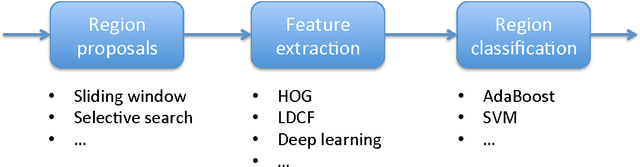


Pedestrian detection is a popular research topic due to its paramount importance for a number of applications, especially in the fields of automotive, surveillance and robotics. Despite the significant improvements, pedestrian detection is still an open challenge that calls for more and more accurate algorithms. In the last few years, deep learning and in particular convolutional neural networks emerged as the state of the art in terms of accuracy for a number of computer vision tasks such as image classification, object detection and segmentation, often outperforming the previous gold standards by a large margin. In this paper, we propose a pedestrian detection system based on deep learning, adapting a general-purpose convolutional network to the task at hand. By thoroughly analyzing and optimizing each step of the detection pipeline we propose an architecture that outperforms traditional methods, achieving a task accuracy close to that of state-of-the-art approaches, while requiring a low computational time. Finally, we tested the system on an NVIDIA Jetson TK1, a 192-core platform that is envisioned to be a forerunner computational brain of future self-driving cars.