 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Steps Toward Camera Model Identification with Convolutional Neural Networks
Sep 26, 2017


Detecting the camera model used to shoot a picture enables to solve a wide series of forensic problems, from copyright infringement to ownership attribution. For this reason, the forensic community has developed a set of camera model identification algorithms that exploit characteristic traces left on acquired images by the processing pipelines specific of each camera model. In this paper, we investigate a novel approach to solve camera model identification problem. Specifically, we propose a data-driven algorithm based on convolutional neural networks, which learns features characterizing each camera model directly from the acquired pictures. Results on a well-known dataset of 18 camera models show that: (i) the proposed method outperforms up-to-date state-of-the-art algorithms on classification of 64x64 color image patches; (ii) features learned by the proposed network generalize to camera models never used for training.
Reduced Memory Region Based Deep Convolutional Neural Network Detection
Sep 08, 2016
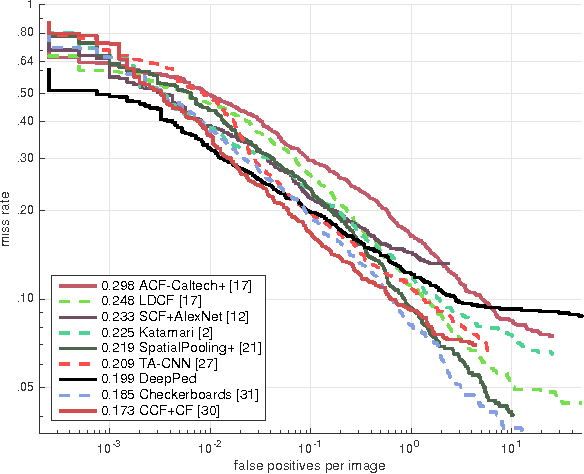
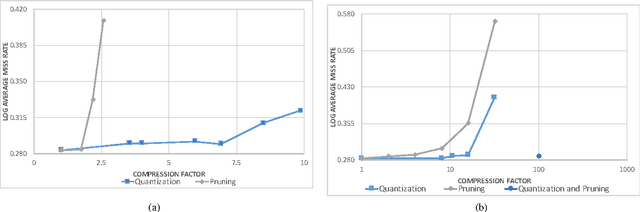
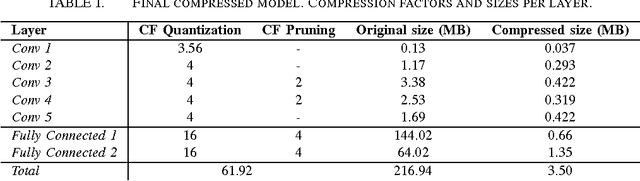
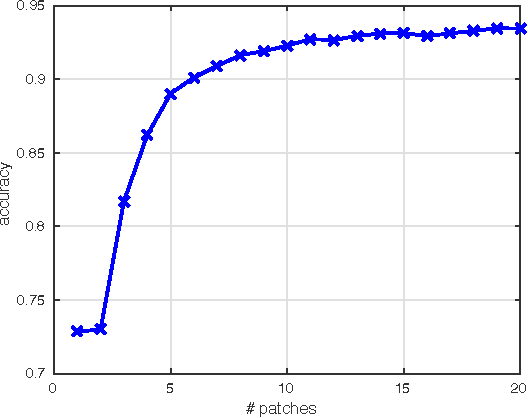
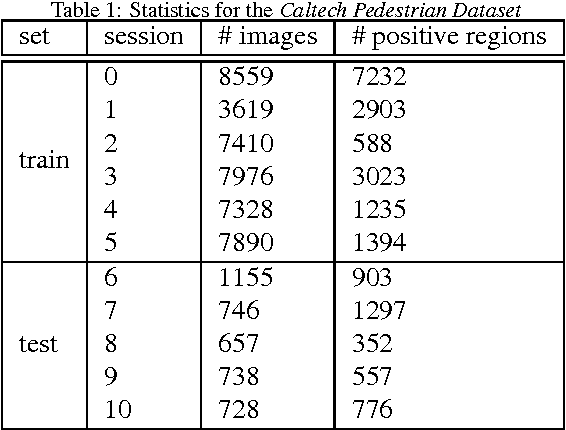
Accurate pedestrian detection has a primary role in automotive safety: for example, by issuing warnings to the driver or acting actively on car's brakes, it helps decreasing the probability of injuries and human fatalities. In order to achieve very high accuracy, recent pedestrian detectors have been based on Convolutional Neural Networks (CNN). Unfortunately, such approaches require vast amounts of computational power and memory, preventing efficient implementations on embedded systems. This work proposes a CNN-based detector, adapting a general-purpose convolutional network to the task at hand. By thoroughly analyzing and optimizing each step of the detection pipeline, we develop an architecture that outperforms methods based on traditional image features and achieves an accuracy close to the state-of-the-art while having low computational complexity. Furthermore, the model is compressed in order to fit the tight constrains of low power devices with a limited amount of embedded memory available. This paper makes two main contributions: (1) it proves that a region based deep neural network can be finely tuned to achieve adequate accuracy for pedestrian detection (2) it achieves a very low memory usage without reducing detection accuracy on the Caltech Pedestrian dataset.
* IEEE 2016 ICCE-Berlin
Deep convolutional neural networks for pedestrian detection
Mar 07, 2016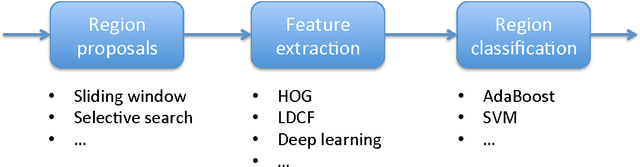


Pedestrian detection is a popular research topic due to its paramount importance for a number of applications, especially in the fields of automotive, surveillance and robotics. Despite the significant improvements, pedestrian detection is still an open challenge that calls for more and more accurate algorithms. In the last few years, deep learning and in particular convolutional neural networks emerged as the state of the art in terms of accuracy for a number of computer vision tasks such as image classification, object detection and segmentation, often outperforming the previous gold standards by a large margin. In this paper, we propose a pedestrian detection system based on deep learning, adapting a general-purpose convolutional network to the task at hand. By thoroughly analyzing and optimizing each step of the detection pipeline we propose an architecture that outperforms traditional methods, achieving a task accuracy close to that of state-of-the-art approaches, while requiring a low computational time. Finally, we tested the system on an NVIDIA Jetson TK1, a 192-core platform that is envisioned to be a forerunner computational brain of future self-driving cars.
Fast keypoint detection in video sequences
Mar 24, 2015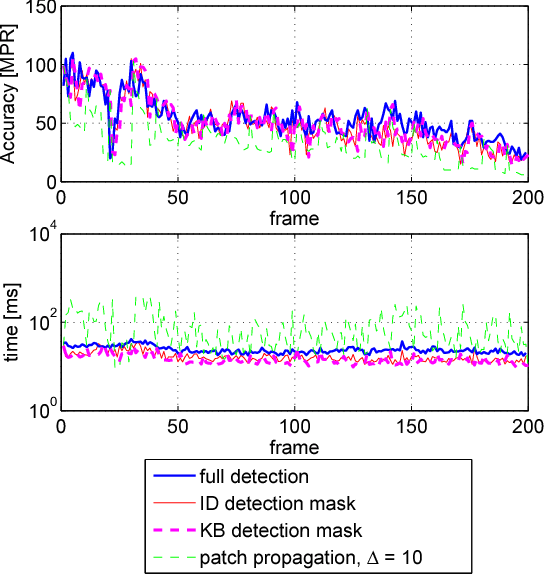
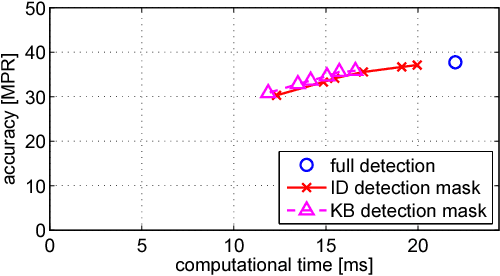
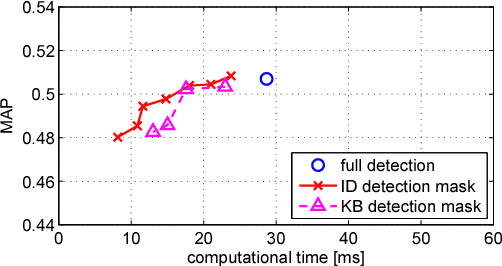
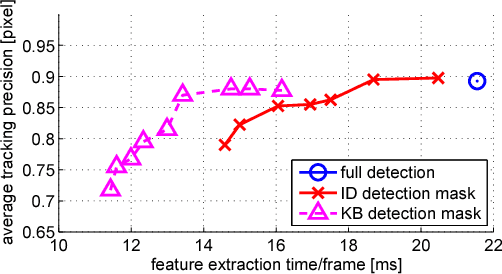
A number of computer vision tasks exploit a succinct representation of the visual content in the form of sets of local features. Given an input image, feature extraction algorithms identify a set of keypoints and assign to each of them a description vector, based on the characteristics of the visual content surrounding the interest point. Several tasks might require local features to be extracted from a video sequence, on a frame-by-frame basis. Although temporal downsampling has been proven to be an effective solution for mobile augmented reality and visual search, high temporal resolution is a key requirement for time-critical applications such as object tracking, event recognition, pedestrian detection, surveillance. In recent years, more and more computationally efficient visual feature detectors and decriptors have been proposed. Nonetheless, such approaches are tailored to still images. In this paper we propose a fast keypoint detection algorithm for video sequences, that exploits the temporal coherence of the sequence of keypoints. According to the proposed method, each frame is preprocessed so as to identify the parts of the input frame for which keypoint detection and description need to be performed. Our experiments show that it is possible to achieve a reduction in computational time of up to 40%, without significantly affecting the task accuracy.
Hybrid coding of visual content and local image features
Feb 27, 2015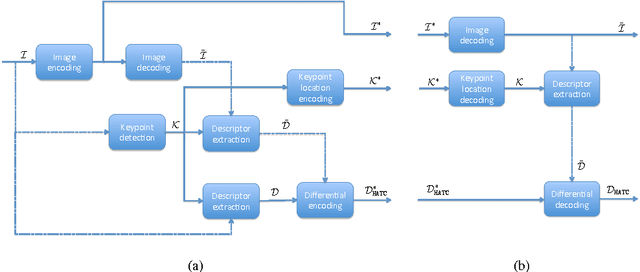
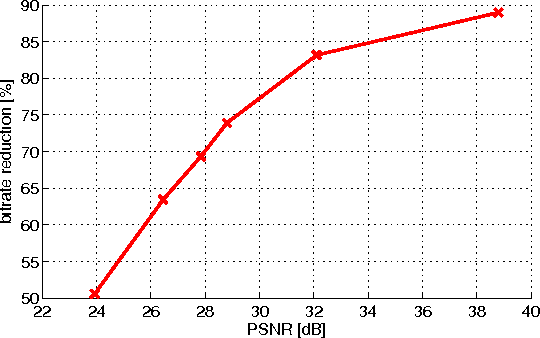
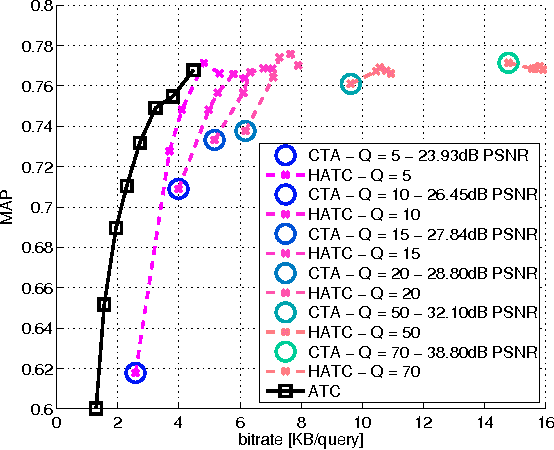
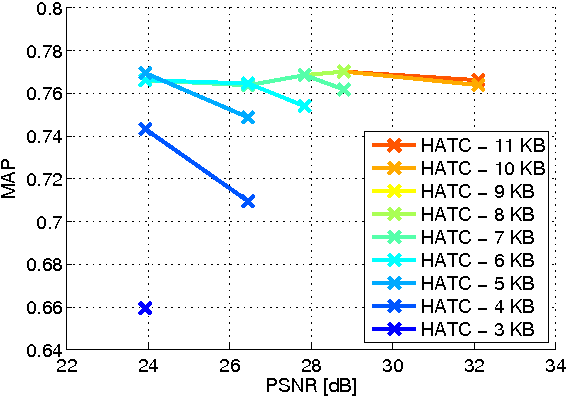
Distributed visual analysis applications, such as mobile visual search or Visual Sensor Networks (VSNs) require the transmission of visual content on a bandwidth-limited network, from a peripheral node to a processing unit. Traditionally, a Compress-Then-Analyze approach has been pursued, in which sensing nodes acquire and encode the pixel-level representation of the visual content, that is subsequently transmitted to a sink node in order to be processed. This approach might not represent the most effective solution, since several analysis applications leverage a compact representation of the content, thus resulting in an inefficient usage of network resources. Furthermore, coding artifacts might significantly impact the accuracy of the visual task at hand. To tackle such limitations, an orthogonal approach named Analyze-Then-Compress has been proposed. According to such a paradigm, sensing nodes are responsible for the extraction of visual features, that are encoded and transmitted to a sink node for further processing. In spite of improved task efficiency, such paradigm implies the central processing node not being able to reconstruct a pixel-level representation of the visual content. In this paper we propose an effective compromise between the two paradigms, namely Hybrid-Analyze-Then-Compress (HATC) that aims at jointly encoding visual content and local image features. Furthermore, we show how a target tradeoff between image quality and task accuracy might be achieved by accurately allocating the bitrate to either visual content or local features.
Coding local and global binary visual features extracted from video sequences
Feb 26, 2015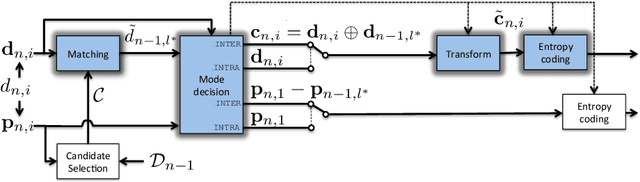

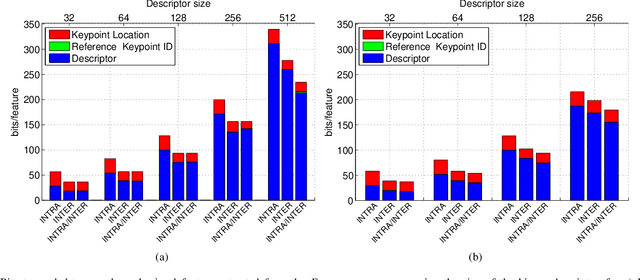
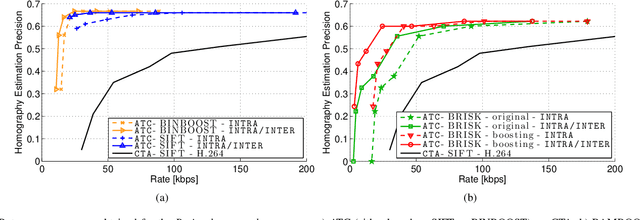
Binary local features represent an effective alternative to real-valued descriptors, leading to comparable results for many visual analysis tasks, while being characterized by significantly lower computational complexity and memory requirements. When dealing with large collections, a more compact representation based on global features is often preferred, which can be obtained from local features by means of, e.g., the Bag-of-Visual-Word (BoVW) model. Several applications, including for example visual sensor networks and mobile augmented reality, require visual features to be transmitted over a bandwidth-limited network, thus calling for coding techniques that aim at reducing the required bit budget, while attaining a target level of efficiency. In this paper we investigate a coding scheme tailored to both local and global binary features, which aims at exploiting both spatial and temporal redundancy by means of intra- and inter-frame coding. In this respect, the proposed coding scheme can be conveniently adopted to support the Analyze-Then-Compress (ATC) paradigm. That is, visual features are extracted from the acquired content, encoded at remote nodes, and finally transmitted to a central controller that performs visual analysis. This is in contrast with the traditional approach, in which visual content is acquired at a node, compressed and then sent to a central unit for further processing, according to the Compress-Then-Analyze (CTA) paradigm. In this paper we experimentally compare ATC and CTA by means of rate-efficiency curves in the context of two different visual analysis tasks: homography estimation and content-based retrieval. Our results show that the novel ATC paradigm based on the proposed coding primitives can be competitive with CTA, especially in bandwidth limited scenarios.