 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Secure and Trustworthy Network Architecture for Federated Learning Healthcare Applications
Apr 17, 2024



Federated Learning (FL) has emerged as a promising approach for privacy-preserving machine learning, particularly in sensitive domains such as healthcare. In this context, the TRUSTroke project aims to leverage FL to assist clinicians in ischemic stroke prediction. This paper provides an overview of the TRUSTroke FL network infrastructure. The proposed architecture adopts a client-server model with a central Parameter Server (PS). We introduce a Docker-based design for the client nodes, offering a flexible solution for implementing FL processes in clinical settings. The impact of different communication protocols (HTTP or MQTT) on FL network operation is analyzed, with MQTT selected for its suitability in FL scenarios. A control plane to support the main operations required by FL processes is also proposed. The paper concludes with an analysis of security aspects of the FL architecture, addressing potential threats and proposing mitigation strategies to increase the trustworthiness level.
$π$-ROAD: a Learn-as-You-Go Framework for On-Demand Emergency Slices in V2X Scenarios
Dec 11, 2020
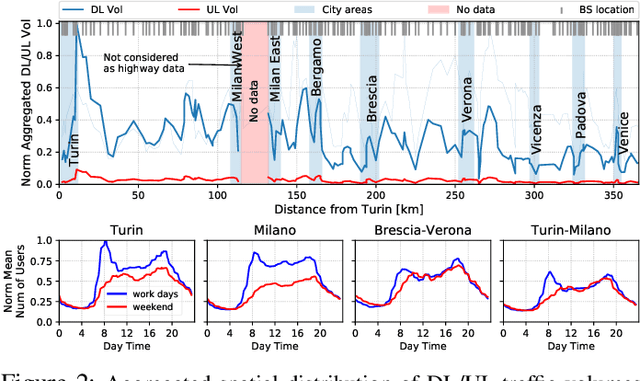
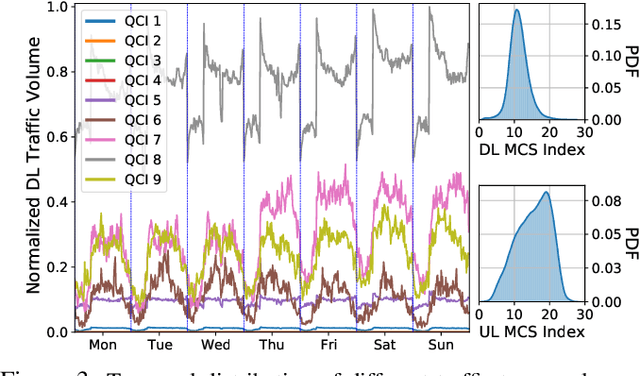
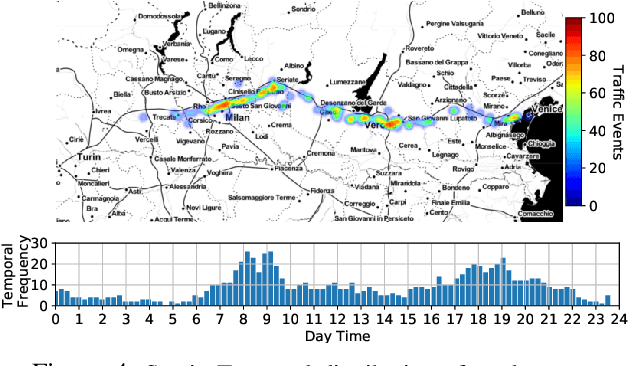
Vehicle-to-everything (V2X) is expected to become one of the main drivers of 5G business in the near future. Dedicated \emph{network slices} are envisioned to satisfy the stringent requirements of advanced V2X services, such as autonomous driving, aimed at drastically reducing road casualties. However, as V2X services become more mission-critical, new solutions need to be devised to guarantee their successful service delivery even in exceptional situations, e.g. road accidents, congestion, etc. In this context, we propose $\pi$-ROAD, a \emph{deep learning} framework to automatically learn regular mobile traffic patterns along roads, detect non-recurring events and classify them by severity level. $\pi$-ROAD enables operators to \emph{proactively} instantiate dedicated \emph{Emergency Network Slices (ENS)} as needed while re-dimensioning the existing slices according to their service criticality level. Our framework is validated by means of real mobile network traces collected within $400~km$ of a highway in Europe and augmented with publicly available information on related road events. Our results show that $\pi$-ROAD successfully detects and classifies non-recurring road events and reduces up to $30\%$ the impact of ENS on already running services.
Fast keypoint detection in video sequences
Mar 24, 2015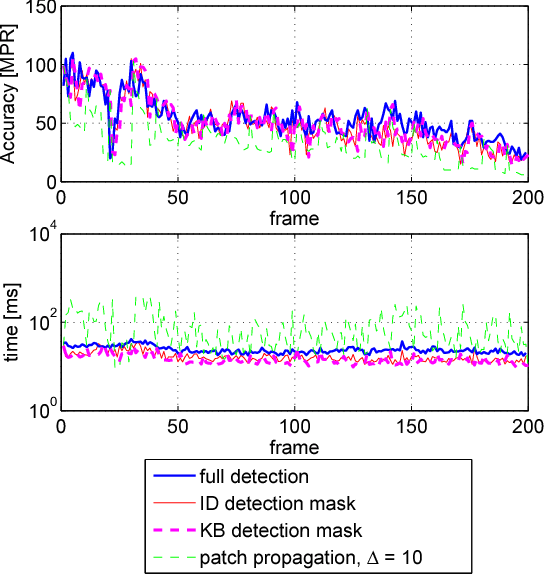
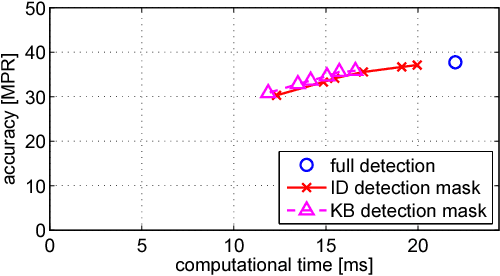
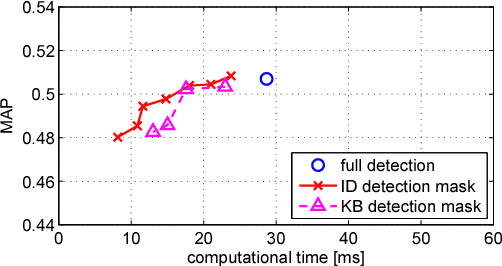
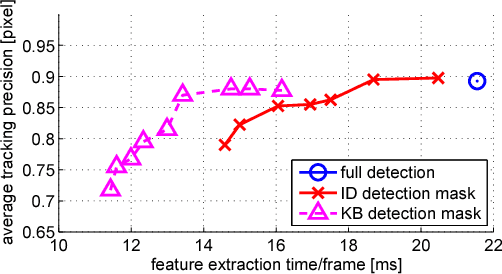
A number of computer vision tasks exploit a succinct representation of the visual content in the form of sets of local features. Given an input image, feature extraction algorithms identify a set of keypoints and assign to each of them a description vector, based on the characteristics of the visual content surrounding the interest point. Several tasks might require local features to be extracted from a video sequence, on a frame-by-frame basis. Although temporal downsampling has been proven to be an effective solution for mobile augmented reality and visual search, high temporal resolution is a key requirement for time-critical applications such as object tracking, event recognition, pedestrian detection, surveillance. In recent years, more and more computationally efficient visual feature detectors and decriptors have been proposed. Nonetheless, such approaches are tailored to still images. In this paper we propose a fast keypoint detection algorithm for video sequences, that exploits the temporal coherence of the sequence of keypoints. According to the proposed method, each frame is preprocessed so as to identify the parts of the input frame for which keypoint detection and description need to be performed. Our experiments show that it is possible to achieve a reduction in computational time of up to 40%, without significantly affecting the task accuracy.
Hybrid coding of visual content and local image features
Feb 27, 2015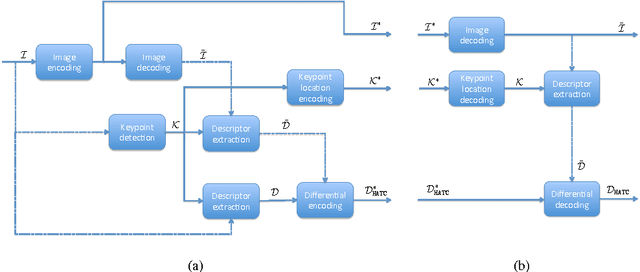
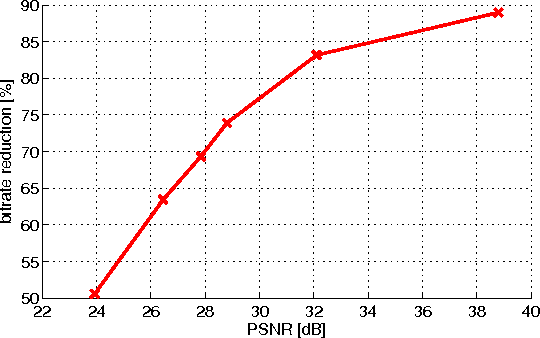
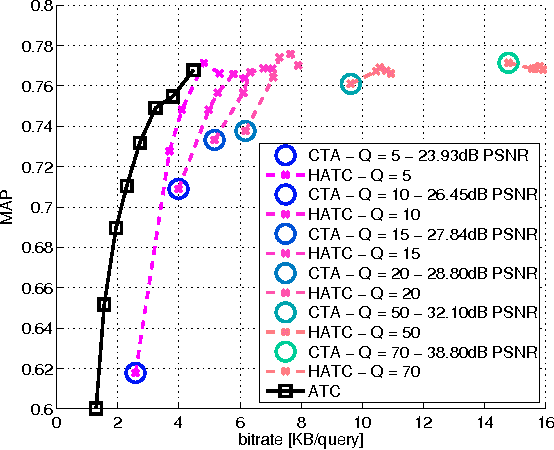
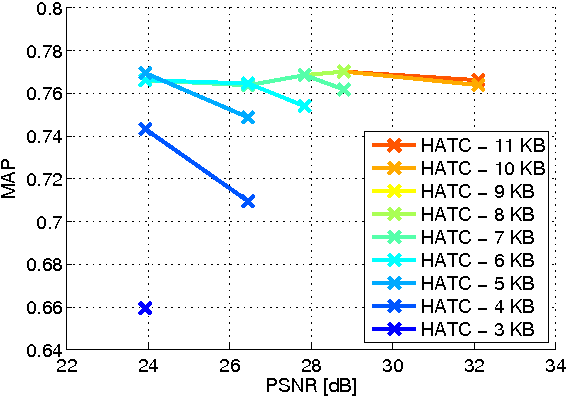
Distributed visual analysis applications, such as mobile visual search or Visual Sensor Networks (VSNs) require the transmission of visual content on a bandwidth-limited network, from a peripheral node to a processing unit. Traditionally, a Compress-Then-Analyze approach has been pursued, in which sensing nodes acquire and encode the pixel-level representation of the visual content, that is subsequently transmitted to a sink node in order to be processed. This approach might not represent the most effective solution, since several analysis applications leverage a compact representation of the content, thus resulting in an inefficient usage of network resources. Furthermore, coding artifacts might significantly impact the accuracy of the visual task at hand. To tackle such limitations, an orthogonal approach named Analyze-Then-Compress has been proposed. According to such a paradigm, sensing nodes are responsible for the extraction of visual features, that are encoded and transmitted to a sink node for further processing. In spite of improved task efficiency, such paradigm implies the central processing node not being able to reconstruct a pixel-level representation of the visual content. In this paper we propose an effective compromise between the two paradigms, namely Hybrid-Analyze-Then-Compress (HATC) that aims at jointly encoding visual content and local image features. Furthermore, we show how a target tradeoff between image quality and task accuracy might be achieved by accurately allocating the bitrate to either visual content or local features.
Coding local and global binary visual features extracted from video sequences
Feb 26, 2015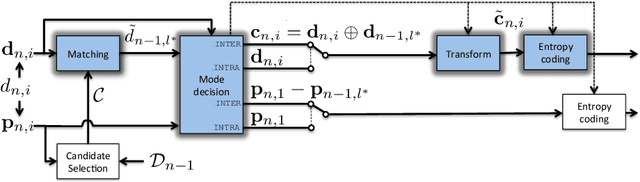

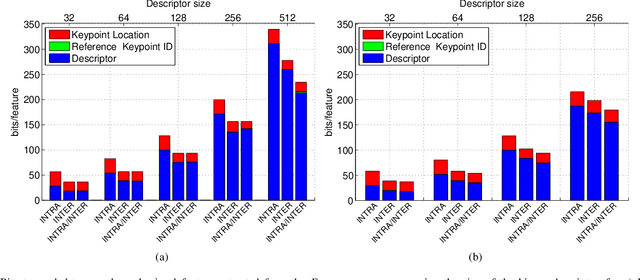
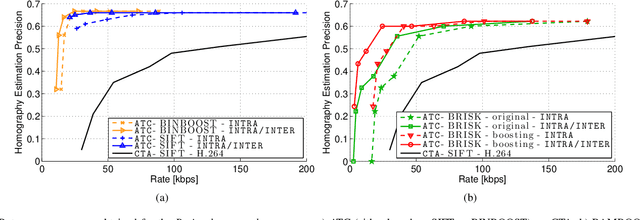
Binary local features represent an effective alternative to real-valued descriptors, leading to comparable results for many visual analysis tasks, while being characterized by significantly lower computational complexity and memory requirements. When dealing with large collections, a more compact representation based on global features is often preferred, which can be obtained from local features by means of, e.g., the Bag-of-Visual-Word (BoVW) model. Several applications, including for example visual sensor networks and mobile augmented reality, require visual features to be transmitted over a bandwidth-limited network, thus calling for coding techniques that aim at reducing the required bit budget, while attaining a target level of efficiency. In this paper we investigate a coding scheme tailored to both local and global binary features, which aims at exploiting both spatial and temporal redundancy by means of intra- and inter-frame coding. In this respect, the proposed coding scheme can be conveniently adopted to support the Analyze-Then-Compress (ATC) paradigm. That is, visual features are extracted from the acquired content, encoded at remote nodes, and finally transmitted to a central controller that performs visual analysis. This is in contrast with the traditional approach, in which visual content is acquired at a node, compressed and then sent to a central unit for further processing, according to the Compress-Then-Analyze (CTA) paradigm. In this paper we experimentally compare ATC and CTA by means of rate-efficiency curves in the context of two different visual analysis tasks: homography estimation and content-based retrieval. Our results show that the novel ATC paradigm based on the proposed coding primitives can be competitive with CTA, especially in bandwidth limited scenarios.