 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAND: Hierarchical Attention Network for Multi-Scale Handwritten Document Recognition and Layout Analysis
Dec 25, 2024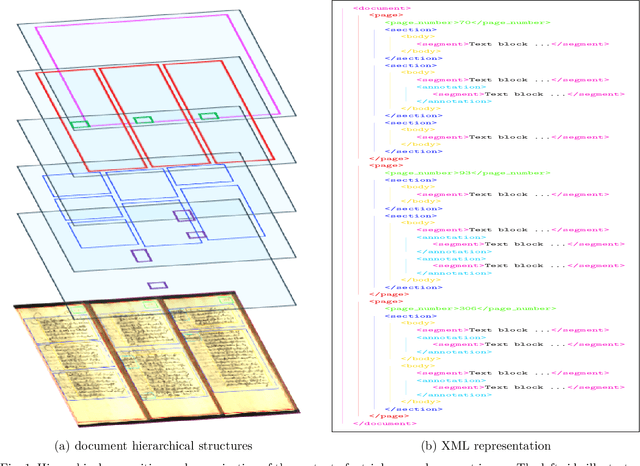

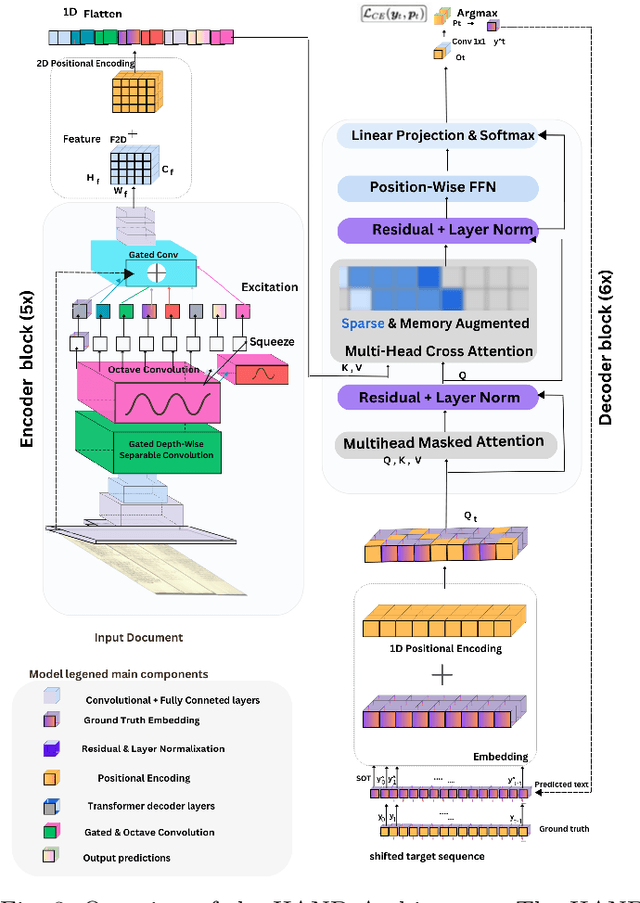

Handwritten document recognition (HDR) is one of the most challenging tasks in the field of computer vision, due to the various writing styles and complex layouts inherent in handwritten texts. Traditionally, this problem has been approached as two separate tasks, handwritten text recognition and layout analysis, and struggled to integrate the two processes effectively. This paper introduces HAND (Hierarchical Attention Network for Multi-Scale Document), a novel end-to-end and segmentation-free architecture for simultaneous text recognition and layout analysis tasks. Our model's key components include an advanced convolutional encoder integrating Gated Depth-wise Separable and Octave Convolutions for robust feature extraction, a Multi-Scale Adaptive Processing (MSAP) framework that dynamically adjusts to document complexity and a hierarchical attention decoder with memory-augmented and sparse attention mechanisms. These components enable our model to scale effectively from single-line to triple-column pages while maintaining computational efficiency. Additionally, HAND adopts curriculum learning across five complexity levels. To improve the recognition accuracy of complex ancient manuscripts, we fine-tune and integrate a Domain-Adaptive Pre-trained mT5 model for post-processing refinement. Extensive evaluations on the READ 2016 dataset demonstrate the superior performance of HAND, achieving up to 59.8% reduction in CER for line-level recognition and 31.2% for page-level recognition compared to state-of-the-art methods. The model also maintains a compact size of 5.60M parameters while establishing new benchmarks in both text recognition and layout analysis. Source code and pre-trained models are available at : https://github.com/MHHamdan/HAND.
HTR-JAND: Handwritten Text Recognition with Joint Attention Network and Knowledge Distillation
Dec 24, 2024
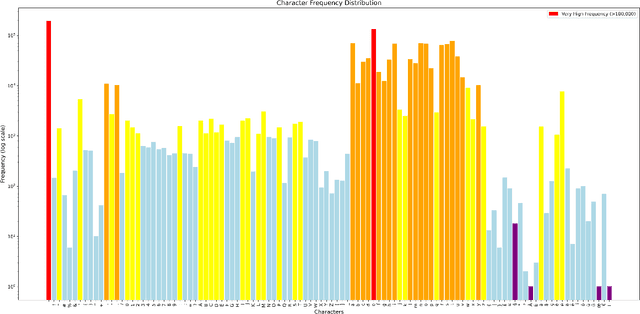
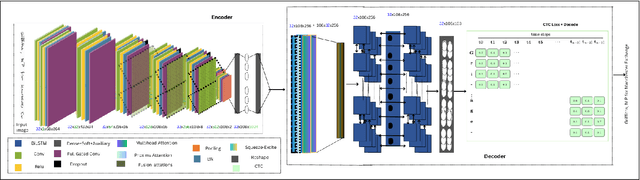
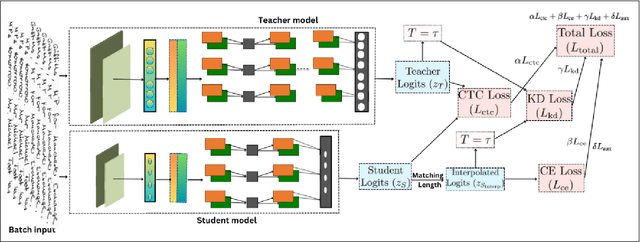
Despite significant advances in deep learning, current Handwritten Text Recognition (HTR) systems struggle with the inherent complexity of historical documents, including diverse writing styles, degraded text quality, and computational efficiency requirements across multiple languages and time periods. This paper introduces HTR-JAND (HTR-JAND: Handwritten Text Recognition with Joint Attention Network and Knowledge Distillation), an efficient HTR framework that combines advanced feature extraction with knowledge distillation. Our architecture incorporates three key components: (1) a CNN architecture integrating FullGatedConv2d layers with Squeeze-and-Excitation blocks for adaptive feature extraction, (2) a Combined Attention mechanism fusing Multi-Head Self-Attention with Proxima Attention for robust sequence modeling, and (3) a Knowledge Distillation framework enabling efficient model compression while preserving accuracy through curriculum-based training. The HTR-JAND framework implements a multi-stage training approach combining curriculum learning, synthetic data generation, and multi-task learning for cross-dataset knowledge transfer. We enhance recognition accuracy through context-aware T5 post-processing, particularly effective for historical documents. Comprehensive evaluations demonstrate HTR-JAND's effectiveness, achieving state-of-the-art Character Error Rates (CER) of 1.23\%, 1.02\%, and 2.02\% on IAM, RIMES, and Bentham datasets respectively. Our Student model achieves a 48\% parameter reduction (0.75M versus 1.5M parameters) while maintaining competitive performance through efficient knowledge transfer. Source code and pre-trained models are available at \href{https://github.com/DocumentRecognitionModels/HTR-JAND}{Github}.