 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Monocular 3D Keypoint Discovery from Multi-View Diffusion Priors
Jul 16, 2025This paper introduces KeyDiff3D, a framework for unsupervised monocular 3D keypoints estimation that accurately predicts 3D keypoints from a single image. While previous methods rely on manual annotations or calibrated multi-view images, both of which are expensive to collect, our method enables monocular 3D keypoints estimation using only a collection of single-view images. To achieve this, we leverage powerful geometric priors embedded in a pretrained multi-view diffusion model. In our framework, this model generates multi-view images from a single image, serving as a supervision signal to provide 3D geometric cues to our model. We also use the diffusion model as a powerful 2D multi-view feature extractor and construct 3D feature volumes from its intermediate representations. This transforms implicit 3D priors learned by the diffusion model into explicit 3D features. Beyond accurate keypoints estimation, we further introduce a pipeline that enables manipulation of 3D objects generated by the diffusion model. Experimental results on diverse aspects and datasets, including Human3.6M, Stanford Dogs, and several in-the-wild and out-of-domain datasets, highlight the effectiveness of our method in terms of accuracy, generalization, and its ability to enable manipulation of 3D objects generated by the diffusion model from a single image.
Representing 3D Shapes With 64 Latent Vectors for 3D Diffusion Models
Mar 11, 2025Constructing a compressed latent space through a variational autoencoder (VAE) is the key for efficient 3D diffusion models. This paper introduces COD-VAE, a VAE that encodes 3D shapes into a COmpact set of 1D latent vectors without sacrificing quality. COD-VAE introduces a two-stage autoencoder scheme to improve compression and decoding efficiency. First, our encoder block progressively compresses point clouds into compact latent vectors via intermediate point patches. Second, our triplane-based decoder reconstructs dense triplanes from latent vectors instead of directly decoding neural fields, significantly reducing computational overhead of neural fields decoding. Finally, we propose uncertainty-guided token pruning, which allocates resources adaptively by skipping computations in simpler regions and improves the decoder efficiency. Experimental results demonstrate that COD-VAE achieves 16x compression compared to the baseline while maintaining quality. This enables 20.8x speedup in generation, highlighting that a large number of latent vectors is not a prerequisite for high-quality reconstruction and generation.
Hierarchically Structured Neural Bones for Reconstructing Animatable Objects from Casual Videos
Aug 01, 2024



We propose a new framework for creating and easily manipulating 3D models of arbitrary objects using casually captured videos. Our core ingredient is a novel hierarchy deformation model, which captures motions of objects with a tree-structured bones. Our hierarchy system decomposes motions based on the granularity and reveals the correlations between parts without exploiting any prior structural knowledge. We further propose to regularize the bones to be positioned at the basis of motions, centers of parts, sufficiently covering related surfaces of the part. This is achieved by our bone occupancy function, which identifies whether a given 3D point is placed within the bone. Coupling the proposed components, our framework offers several clear advantages: (1) users can obtain animatable 3D models of the arbitrary objects in improved quality from their casual videos, (2) users can manipulate 3D models in an intuitive manner with minimal costs, and (3) users can interactively add or delete control points as necessary. The experimental results demonstrate the efficacy of our framework on diverse instances, in reconstruction quality, interpretability and easier manipulation. Our code is available at https://github.com/subin6/HSNB.
Cross-Identity Motion Transfer for Arbitrary Objects through Pose-Attentive Video Reassembling
Jul 17, 2020
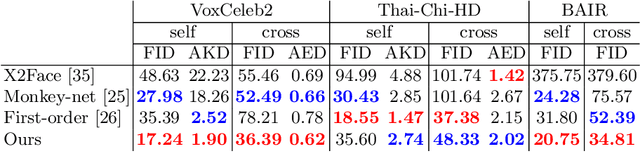
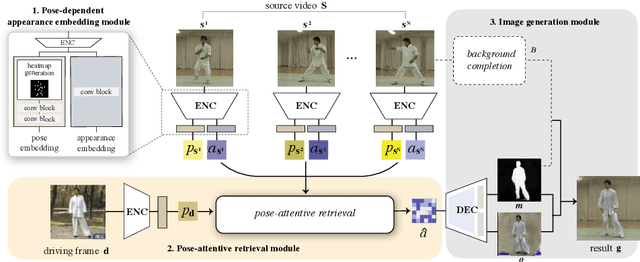
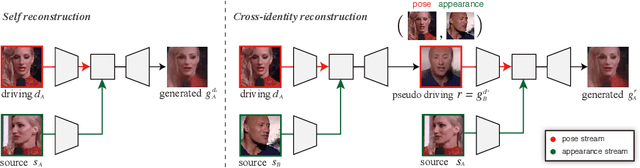
We propose an attention-based networks for transferring motions between arbitrary objects. Given a source image(s) and a driving video, our networks animate the subject in the source images according to the motion in the driving video. In our attention mechanism, dense similarities between the learned keypoints in the source and the driving images are computed in order to retrieve the appearance information from the source images. Taking a different approach from the well-studied warping based models, our attention-based model has several advantages. By reassembling non-locally searched pieces from the source contents, our approach can produce more realistic outputs. Furthermore, our system can make use of multiple observations of the source appearance (e.g. front and sides of faces) to make the results more accurate. To reduce the training-testing discrepancy of the self-supervised learning, a novel cross-identity training scheme is additionally introduced. With the training scheme, our networks is trained to transfer motions between different subjects, as in the real testing scenario. Experimental results validate that our method produces visually pleasing results in various object domains, showing better performances compared to previous works.