 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Word Embedding Methods Stable and Should We Care About It?
Apr 17, 2021
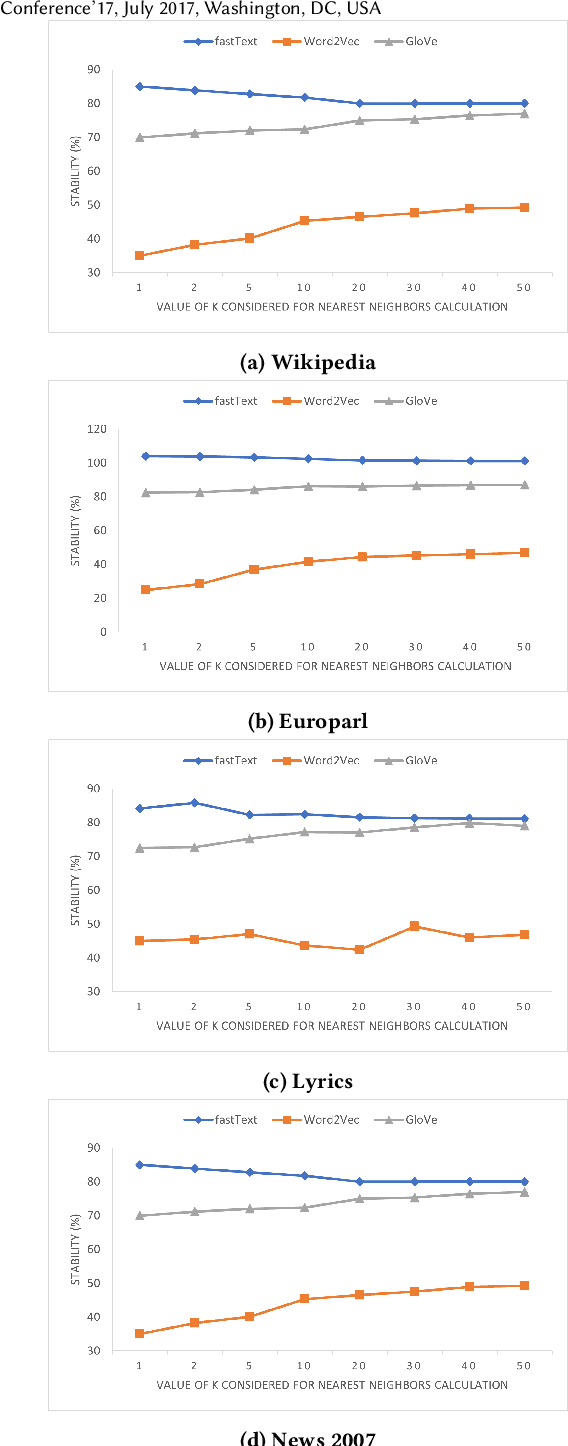
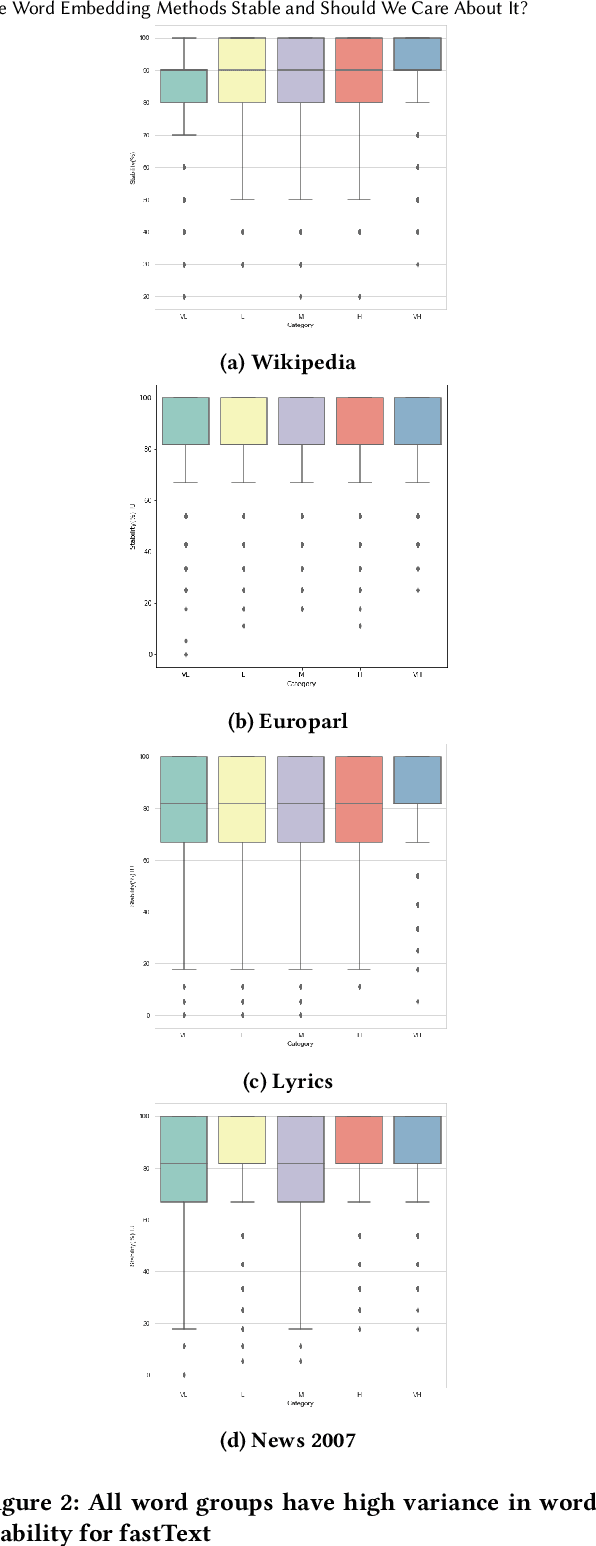
A representation learning method is considered stable if it consistently generates similar representation of the given data across multiple runs. Word Embedding Methods (WEMs) are a class of representation learning methods that generate dense vector representation for each word in the given text data. The central idea of this paper is to explore the stability measurement of WEMs using intrinsic evaluation based on word similarity. We experiment with three popular WEMs: Word2Vec, GloVe, and fastText. For stability measurement, we investigate the effect of five parameters involved in training these models. We perform experiments using four real-world datasets from different domains: Wikipedia, News, Song lyrics, and European parliament proceedings. We also observe the effect of WEM stability on three downstream tasks: Clustering, POS tagging, and Fairness evaluation. Our experiments indicate that amongst the three WEMs, fastText is the most stable, followed by GloVe and Word2Vec.
Decoding the Style and Bias of Song Lyrics
Jul 17, 2019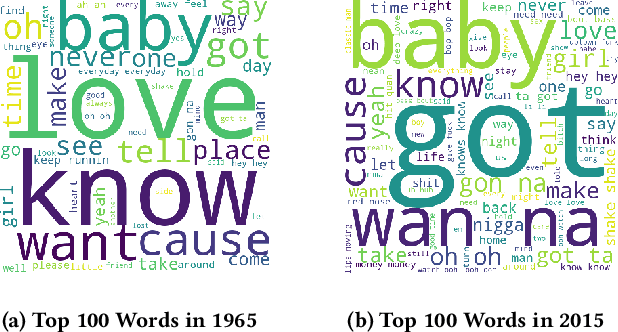
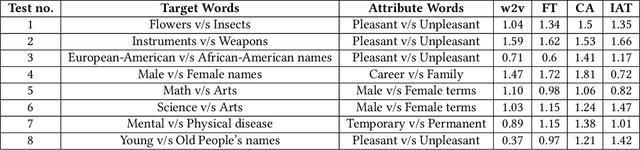
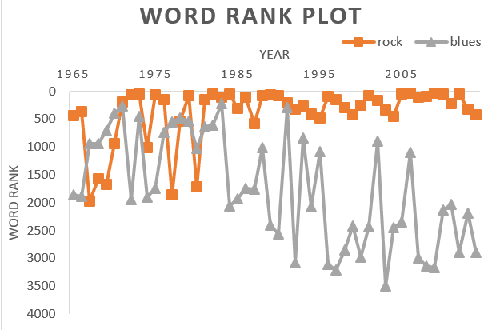
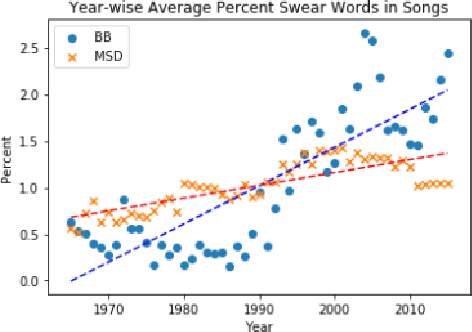
The central idea of this paper is to gain a deeper understanding of song lyrics computationally. We focus on two aspects: style and biases of song lyrics. All prior works to understand these two aspects are limited to manual analysis of a small corpus of song lyrics. In contrast, we analyzed more than half a million songs spread over five decades. We characterize the lyrics style in terms of vocabulary, length, repetitiveness, speed, and readability. We have observed that the style of popular songs significantly differs from other songs. We have used distributed representation methods and WEAT test to measure various gender and racial biases in the song lyrics. We have observed that biases in song lyrics correlate with prior results on human subjects. This correlation indicates that song lyrics reflect the biases that exist in society. Increasing consumption of music and the effect of lyrics on human emotions makes this analysis important.