 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Adapter to Improve the Performance of Compressed Deep Learning Models
Feb 16, 2026Compressed Deep Learning (DL) models are essential for deployment in resource-constrained environments. But their performance often lags behind their large-scale counterparts. To bridge this gap, we propose Alignment Adapter (AlAd): a lightweight, sliding-window-based adapter. It aligns the token-level embeddings of a compressed model with those of the original large model. AlAd preserves local contextual semantics, enables flexible alignment across differing dimensionalities or architectures, and is entirely agnostic to the underlying compression method. AlAd can be deployed in two ways: as a plug-and-play module over a frozen compressed model, or by jointly fine-tuning AlAd with the compressed model for further performance gains. Through experiments on BERT-family models across three token-level NLP tasks, we demonstrate that AlAd significantly boosts the performance of compressed models with only marginal overhead in size and latency.
Application Specific Compression of Deep Learning Models
Sep 09, 2024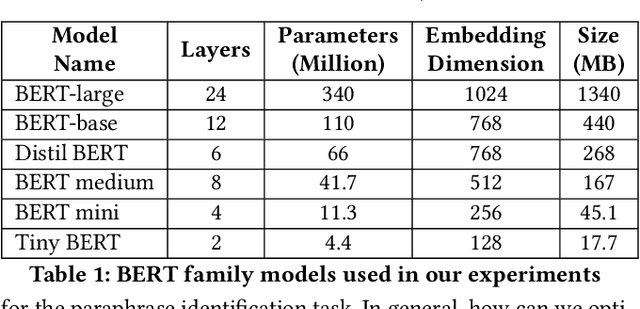
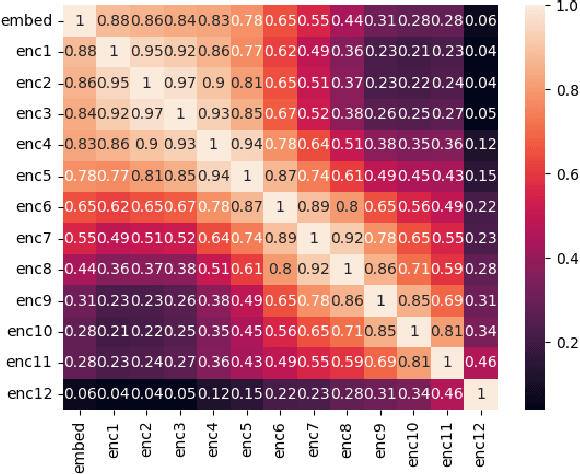
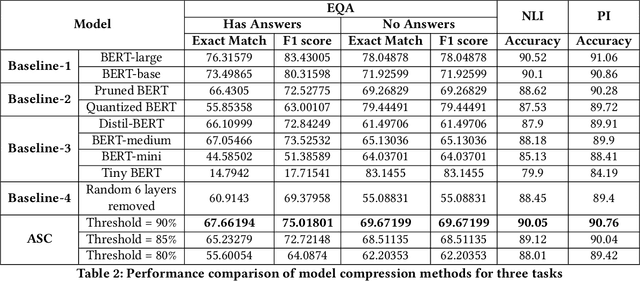
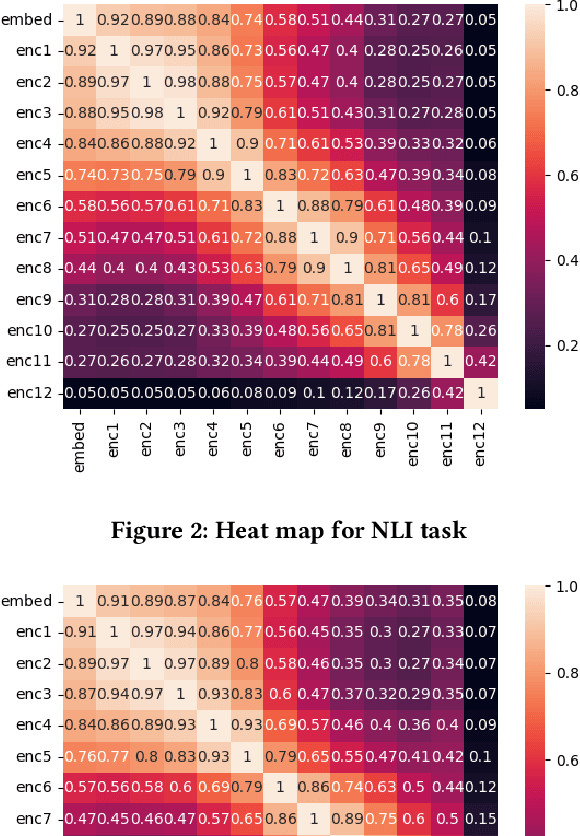
Large Deep Learning models are compressed and deployed for specific applications. However, current Deep Learning model compression methods do not utilize the information about the target application. As a result, the compressed models are application agnostic. Our goal is to customize the model compression process to create a compressed model that will perform better for the target application. Our method, Application Specific Compression (ASC), identifies and prunes components of the large Deep Learning model that are redundant specifically for the given target application. The intuition of our work is to prune the parts of the network that do not contribute significantly to updating the data representation for the given application. We have experimented with the BERT family of models for three applications: Extractive QA, Natural Language Inference, and Paraphrase Identification. We observe that customized compressed models created using ASC method perform better than existing model compression methods and off-the-shelf compressed models.
Compressed models are NOT miniature versions of large models
Jul 18, 2024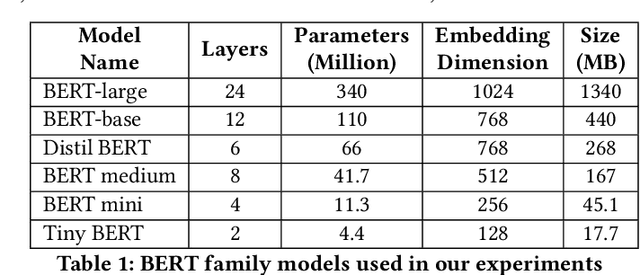
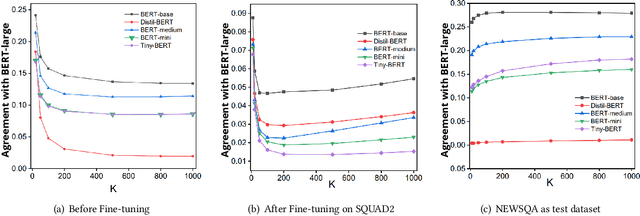
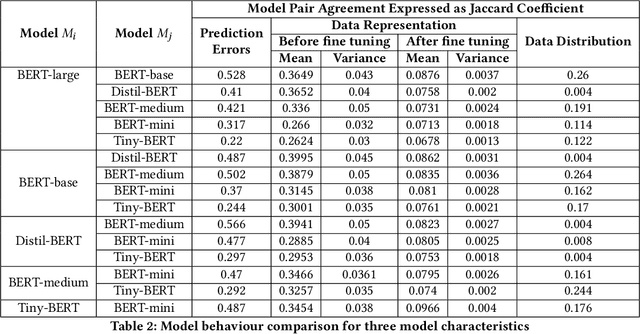
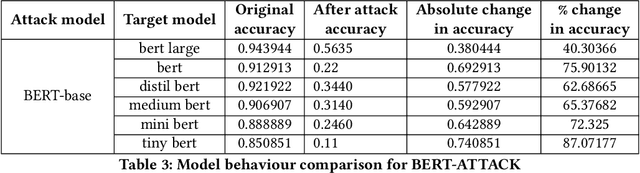
Large neural models are often compressed before deployment. Model compression is necessary for many practical reasons, such as inference latency, memory footprint, and energy consumption. Compressed models are assumed to be miniature versions of corresponding large neural models. However, we question this belief in our work. We compare compressed models with corresponding large neural models using four model characteristics: prediction errors, data representation, data distribution, and vulnerability to adversarial attack. We perform experiments using the BERT-large model and its five compressed versions. For all four model characteristics, compressed models significantly differ from the BERT-large model. Even among compressed models, they differ from each other on all four model characteristics. Apart from the expected loss in model performance, there are major side effects of using compressed models to replace large neural models.
Effect of dimensionality change on the bias of word embeddings
Dec 28, 2023Word embedding methods (WEMs) are extensively used for representing text data. The dimensionality of these embeddings varies across various tasks and implementations. The effect of dimensionality change on the accuracy of the downstream task is a well-explored question. However, how the dimensionality change affects the bias of word embeddings needs to be investigated. Using the English Wikipedia corpus, we study this effect for two static (Word2Vec and fastText) and two context-sensitive (ElMo and BERT) WEMs. We have two observations. First, there is a significant variation in the bias of word embeddings with the dimensionality change. Second, there is no uniformity in how the dimensionality change affects the bias of word embeddings. These factors should be considered while selecting the dimensionality of word embeddings.