 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Generic Transformer: Deconstructing a Strong Baseline for Time Series Foundation Models
Feb 06, 2026The recent surge in Time Series Foundation Models has rapidly advanced the field, yet the heterogeneous training setups across studies make it difficult to attribute improvements to architectural innovations versus data engineering. In this work, we investigate the potential of a standard patch Transformer, demonstrating that this generic architecture achieves state-of-the-art zero-shot forecasting performance using a straightforward training protocol. We conduct a comprehensive ablation study that covers model scaling, data composition, and training techniques to isolate the essential ingredients for high performance. Our findings identify the key drivers of performance, while confirming that the generic architecture itself demonstrates excellent scalability. By strictly controlling these variables, we provide comprehensive empirical results on model scaling across multiple dimensions. We release our open-source model and detailed findings to establish a transparent, reproducible baseline for future research.
Tiny Time Mixers : Fast Pre-trained Models for Enhanced Zero/Few-Shot Forecasting of Multivariate Time Series
Jan 17, 2024Large pre-trained models for zero/few-shot learning excel in language and vision domains but encounter challenges in multivariate time series (TS) due to the diverse nature and scarcity of publicly available pre-training data. Consequently, there has been a recent surge in utilizing pre-trained large language models (LLMs) with token adaptations for TS forecasting. These approaches employ cross-domain transfer learning and surprisingly yield impressive results. However, these models are typically very slow and large (~billion parameters) and do not consider cross-channel correlations. To address this, we present Tiny Time Mixers (TTM), a significantly small model based on the lightweight TSMixer architecture. TTM marks the first success in developing fast and tiny general pre-trained models (<1M parameters), exclusively trained on public TS datasets, with effective transfer learning capabilities for forecasting. To tackle the complexity of pre-training on multiple datasets with varied temporal resolutions, we introduce several novel enhancements such as adaptive patching, dataset augmentation via downsampling, and resolution prefix tuning. Moreover, we employ a multi-level modeling strategy to effectively model channel correlations and infuse exogenous signals during fine-tuning, a crucial capability lacking in existing benchmarks. TTM shows significant accuracy gains (12-38\%) over popular benchmarks in few/zero-shot forecasting. It also drastically reduces the compute needs as compared to LLM-TS methods, with a 14X cut in learnable parameters, 106X less total parameters, and substantial reductions in fine-tuning (65X) and inference time (54X). In fact, TTM's zero-shot often surpasses the few-shot results in many popular benchmarks, highlighting the efficacy of our approach. Code and pre-trained models will be open-sourced.
Interpretable Clustering via Multi-Polytope Machines
Dec 10, 2021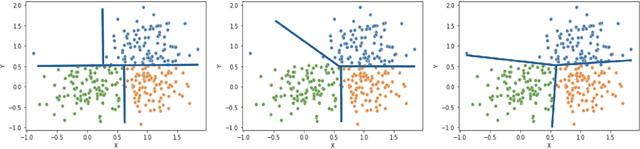
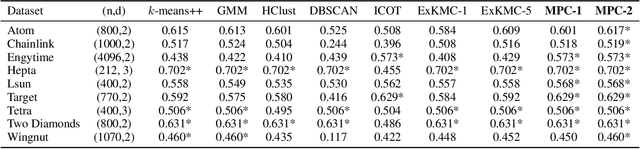


Clustering is a popular unsupervised learning tool often used to discover groups within a larger population such as customer segments, or patient subtypes. However, despite its use as a tool for subgroup discovery and description - few state-of-the-art algorithms provide any rationale or description behind the clusters found. We propose a novel approach for interpretable clustering that both clusters data points and constructs polytopes around the discovered clusters to explain them. Our framework allows for additional constraints on the polytopes - including ensuring that the hyperplanes constructing the polytope are axis-parallel or sparse with integer coefficients. We formulate the problem of constructing clusters via polytopes as a Mixed-Integer Non-Linear Program (MINLP). To solve our formulation we propose a two phase approach where we first initialize clusters and polytopes using alternating minimization, and then use coordinate descent to boost clustering performance. We benchmark our approach on a suite of synthetic and real world clustering problems, where our algorithm outperforms state of the art interpretable and non-interpretable clustering algorithms.