 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-wise Autoencoders Measure Classification Difficulty And Detect Label Mistakes
Dec 03, 2024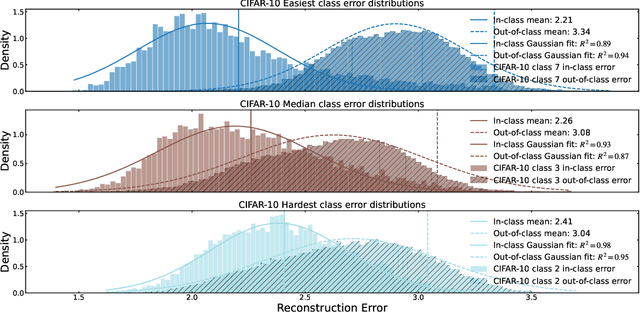

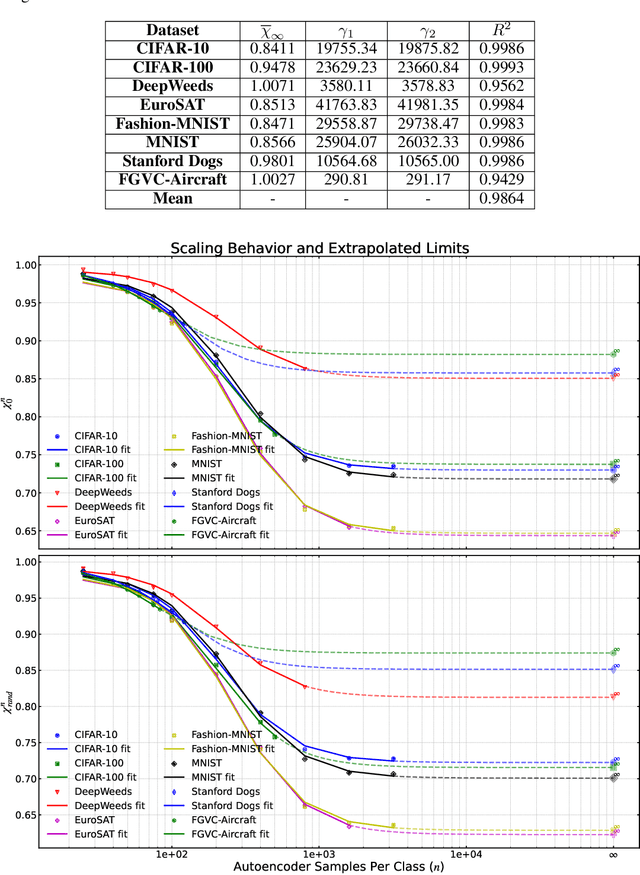
We introduce a new framework for analyzing classification datasets based on the ratios of reconstruction errors between autoencoders trained on individual classes. This analysis framework enables efficient characterization of datasets on the sample, class, and entire dataset levels. We define reconstruction error ratios (RERs) that probe classification difficulty and allow its decomposition into (1) finite sample size and (2) Bayes error and decision-boundary complexity. Through systematic study across 19 popular visual datasets, we find that our RER-based dataset difficulty probe strongly correlates with error rate for state-of-the-art (SOTA) classification models. By interpreting sample-level classification difficulty as a label mistakenness score, we further find that RERs achieve SOTA performance on mislabel detection tasks on hard datasets under symmetric and asymmetric label noise. Our code is publicly available at https://github.com/voxel51/reconstruction-error-ratios.
Zero-Shot Coreset Selection: Efficient Pruning for Unlabeled Data
Nov 22, 2024

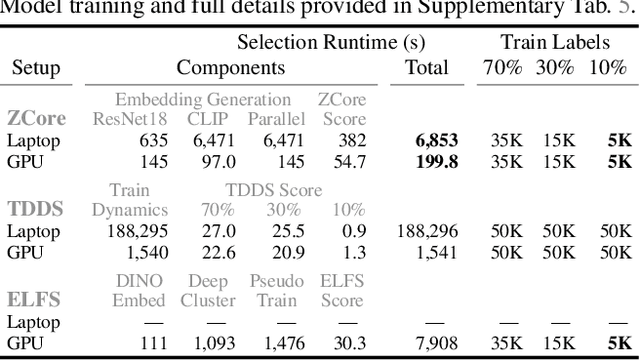

Deep learning increasingly relies on massive data with substantial costs for storage, annotation, and model training. To reduce these costs, coreset selection aims to find a representative subset of data to train models while ideally performing on par with the full data training. State-of-the-art coreset methods use carefully-designed criteria to quantify the importance of each data example via ground truth labels and dataset-specific training, then select examples whose scores lie in a certain range to construct a coreset. These methods work well in their respective settings, however, they cannot select data that are unlabeled, which is the majority of real-world data. To that end, this paper motivates and formalizes the problem of unlabeled coreset selection to enable greater scale and reduce annotation costs for deep learning. As a solution, we develop Zero-Shot Coreset Selection (ZCore), a method that efficiently selects coresets without ground truth labels or training on candidate data. Instead, ZCore uses existing foundation models to generate a zero-shot embedding space for unlabeled data, then quantifies the relative importance of each example based on overall coverage and redundancy within the embedding distribution. We evaluate ZCore on four datasets and outperform several state-of-the-art label-based methods, leading to a strong baseline for future research in unlabeled coreset selection. On ImageNet, ZCore selections achieve a downstream model accuracy of 53.99% with only 10% training data, which outperforms label-based methods while removing annotation requirements for 1.15 million images. Our code is publicly available at https://github.com/voxel51/zcore.
Depth from Camera Motion and Object Detection
Mar 02, 2021
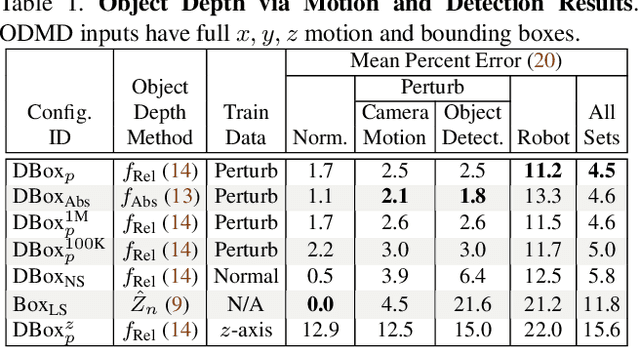


This paper addresses the problem of learning to estimate the depth of detected objects given some measurement of camera motion (e.g., from robot kinematics or vehicle odometry). We achieve this by 1) designing a recurrent neural network (DBox) that estimates the depth of objects using a generalized representation of bounding boxes and uncalibrated camera movement and 2) introducing the Object Depth via Motion and Detection Dataset (ODMD). ODMD training data are extensible and configurable, and the ODMD benchmark includes 21,600 examples across four validation and test sets. These sets include mobile robot experiments using an end-effector camera to locate objects from the YCB dataset and examples with perturbations added to camera motion or bounding box data. In addition to the ODMD benchmark, we evaluate DBox in other monocular application domains, achieving state-of-the-art results on existing driving and robotics benchmarks and estimating the depth of objects using a camera phone.
Learning Object Depth from Camera Motion and Video Object Segmentation
Jul 11, 2020
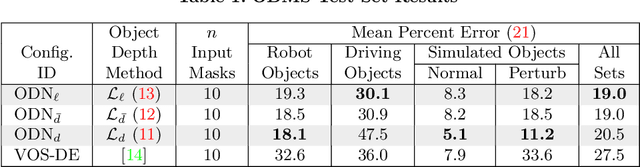
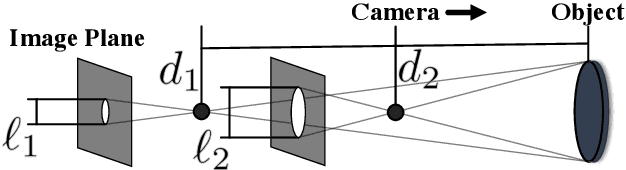

Video object segmentation, i.e., the separation of a target object from background in video, has made significant progress on real and challenging videos in recent years. To leverage this progress in 3D applications, this paper addresses the problem of learning to estimate the depth of segmented objects given some measurement of camera motion (e.g., from robot kinematics or vehicle odometry). We achieve this by, first, introducing a diverse, extensible dataset and, second, designing a novel deep network that estimates the depth of objects using only segmentation masks and uncalibrated camera movement. Our data-generation framework creates artificial object segmentations that are scaled for changes in distance between the camera and object, and our network learns to estimate object depth even with segmentation errors. We demonstrate our approach across domains using a robot camera to locate objects from the YCB dataset and a vehicle camera to locate obstacles while driving.
BubbleNets: Learning to Select the Guidance Frame in Video Object Segmentation by Deep Sorting Frames
Mar 28, 2019
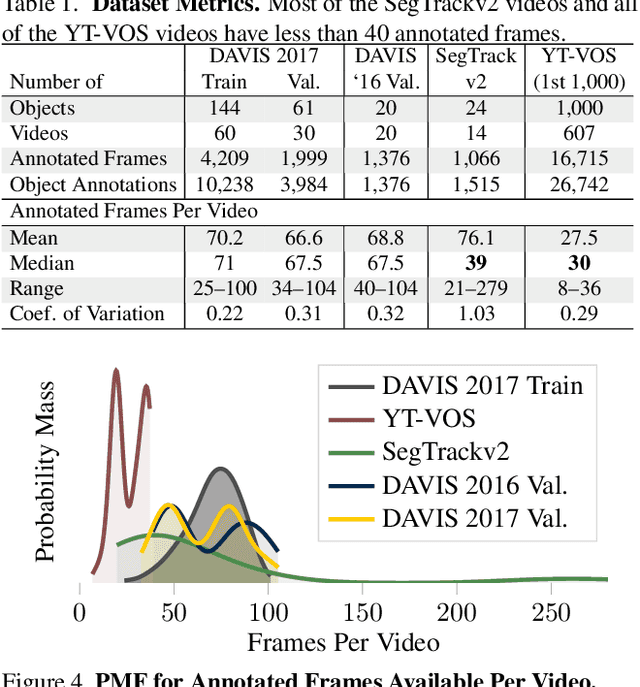

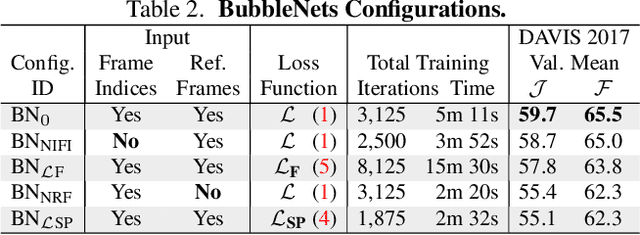
Semi-supervised video object segmentation has made significant progress on real and challenging videos in recent years. The current paradigm for segmentation methods and benchmark datasets is to segment objects in video provided a single annotation in the first frame. However, we find that segmentation performance across the entire video varies dramatically when selecting an alternative frame for annotation. This paper address the problem of learning to suggest the single best frame across the video for user annotation---this is, in fact, never the first frame of video. We achieve this by introducing BubbleNets, a novel deep sorting network that learns to select frames using a performance-based loss function that enables the conversion of expansive amounts of training examples from already existing datasets. Using BubbleNets, we are able to achieve an 11% relative improvement in segmentation performance on the DAVIS benchmark without any changes to the underlying method of segmentation.
Tukey-Inspired Video Object Segmentation
Nov 30, 2018
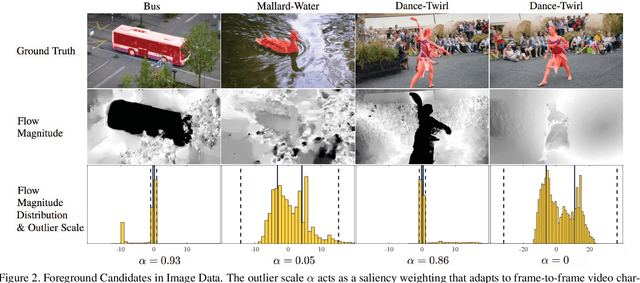
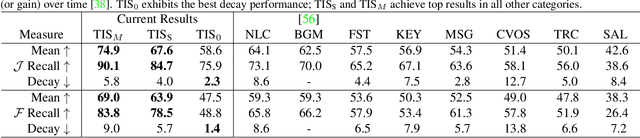
We investigate the problem of strictly unsupervised video object segmentation, i.e., the separation of a primary object from background in video without a user-provided object mask or any training on an annotated dataset. We find foreground objects in low-level vision data using a John Tukey-inspired measure of "outlierness". This Tukey-inspired measure also estimates the reliability of each data source as video characteristics change (e.g., a camera starts moving). The proposed method achieves state-of-the-art results for strictly unsupervised video object segmentation on the challenging DAVIS dataset. Finally, we use a variant of the Tukey-inspired measure to combine the output of multiple segmentation methods, including those using supervision during training, runtime, or both. This collectively more robust method of segmentation improves the Jaccard measure of its constituent methods by as much as 28%.
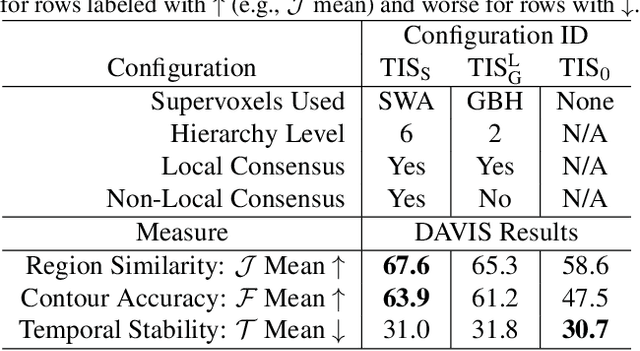
Video Object Segmentation using Supervoxel-Based Gerrymandering
Apr 18, 2017


Pixels operate locally. Superpixels have some potential to collect information across many pixels; supervoxels have more potential by implicitly operating across time. In this paper, we explore this well established notion thoroughly analyzing how supervoxels can be used in place of and in conjunction with other means of aggregating information across space-time. Focusing on the problem of strictly unsupervised video object segmentation, we devise a method called supervoxel gerrymandering that links masks of foregroundness and backgroundness via local and non-local consensus measures. We pose and answer a series of critical questions about the ability of supervoxels to adequately sway local voting; the questions regard type and scale of supervoxels as well as local versus non-local consensus, and the questions are posed in a general way so as to impact the broader knowledge of the use of supervoxels in video understanding. We work with the DAVIS dataset and find that our analysis yields an unsupervised method that outperforms all other known unsupervised methods and even many supervised ones.