 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCome Again? Re-Query in Referring Expression Comprehension
Oct 19, 2021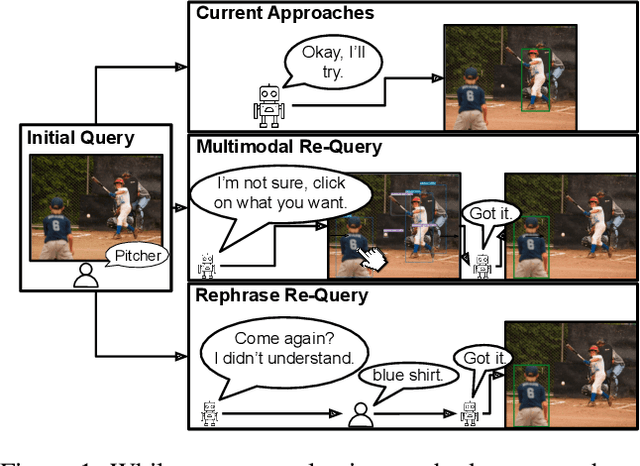
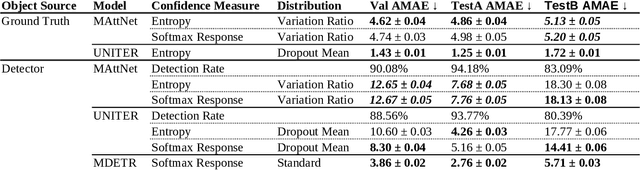


To build a shared perception of the world, humans rely on the ability to resolve misunderstandings by requesting and accepting clarifications. However, when evaluating visiolinguistic models, metrics such as accuracy enforce the assumption that a decision must be made based on a single piece of evidence. In this work, we relax this assumption for the task of referring expression comprehension by allowing the model to request help when its confidence is low. We consider two ways in which this help can be provided: multimodal re-query, where the user is allowed to point or click to provide additional information to the model, and rephrase re-query, where the user is only allowed to provide another referring expression. We demonstrate the importance of re-query by showing that providing the best referring expression for all objects can increase accuracy by up to 21.9% and that this accuracy can be matched by re-querying only 12% of initial referring expressions. We further evaluate re-query functions for both multimodal and rephrase re-query across three modern approaches and demonstrate combined replacement for rephrase re-query, which improves average single-query performance by up to 6.5% and converges to as close as 1.6% of the upper bound of single-query performance.
DAER to Reject Seeds with Dual-loss Additional Error Regression
Sep 16, 2020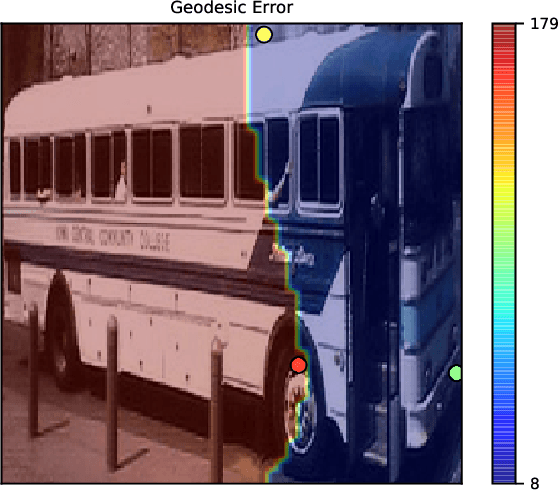
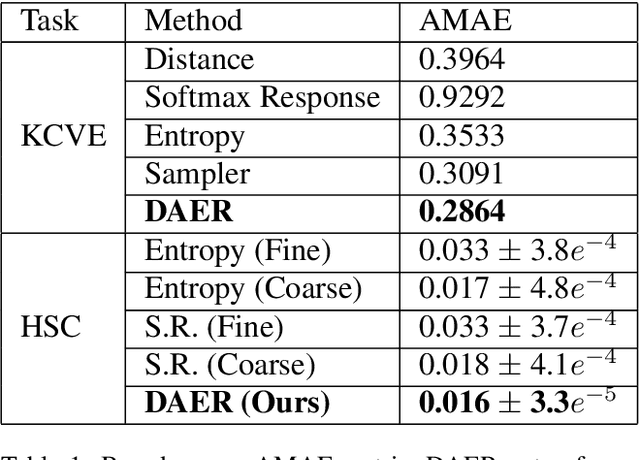
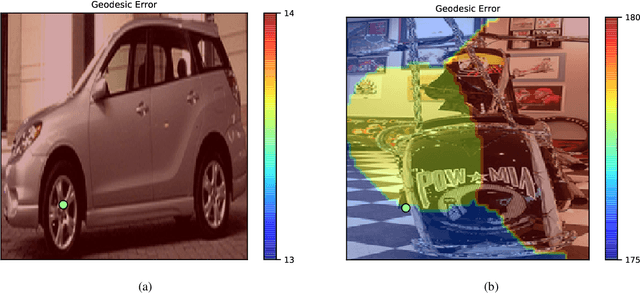
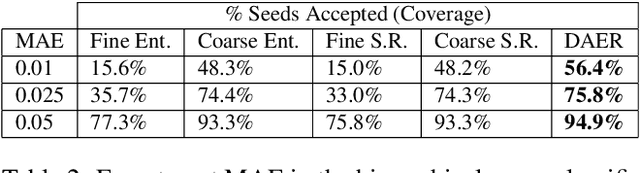
Many vision tasks require side information at inference time---a seed---to fully specify the problem. For example, an initial object segmentation is needed for video object segmentation. To date, all such work makes the tacit assumption that the seed is a good one. However, in practice, from crowd-sourcing to noisy automated seeds, this is not the case. We hence propose the novel problem of seed rejection---determining whether to reject a seed based on expected degradation relative to the gold-standard. We provide a formal definition to this problem, and focus on two challenges: distinguishing poor primary inputs from poor seeds and understanding the model's response to noisy seeds conditioned on the primary input. With these challenges in mind, we propose a novel training method and evaluation metrics for the seed rejection problem. We then validate these metrics and methods on two problems which use seeds as a source of additional information: keypoint-conditioned viewpoint estimation with crowdsourced seeds and hierarchical scene classification with automated seeds. In these experiments, we show our method reduces the required number of seeds that need to be reviewed for a target performance by up to 23% over strong baselines.