 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied4C: Measuring What Matters for Embodied Vision-Language Navigation
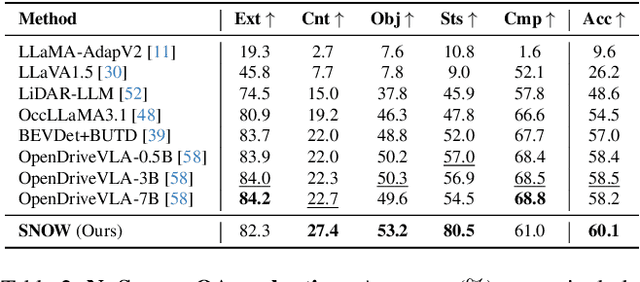
Dec 19, 2025Vision-language navigation requires agents to reason and act under constraints of embodiment. While vision-language models (VLMs) demonstrate strong generalization, current benchmarks provide limited understanding of how embodiment -- i.e., the choice of physical platform, sensor configuration, and modality alignment -- influences perception, reasoning, and control. We introduce Embodied4C, a closed-loop benchmark designed as a Turing test for embodied reasoning. The benchmark evaluates the core embodied capabilities of VLMs across three heterogeneous embodiments -- autonomous vehicles, aerial drones, and robotic manipulators -- through approximately 1.1K one-shot reasoning questions and 58 goal-directed navigation tasks. These tasks jointly assess four foundational dimensions: semantic, spatial, temporal, and physical reasoning. Each embodiment presents dynamic sensor configurations and environment variations to probe generalization beyond platform-specific adaptation. To prevent embodiment overfitting, Embodied4C integrates domain-far queries targeting abstract and cross-context reasoning. Comprehensive evaluation across ten state-of-the-art VLMs and four embodied control baselines shows that cross-modal alignment and instruction tuning matter more than scale, while spatial and temporal reasoning remains the primary bottleneck for reliable embodied competence.
SNOW: Spatio-Temporal Scene Understanding with World Knowledge for Open-World Embodied Reasoning
Dec 18, 2025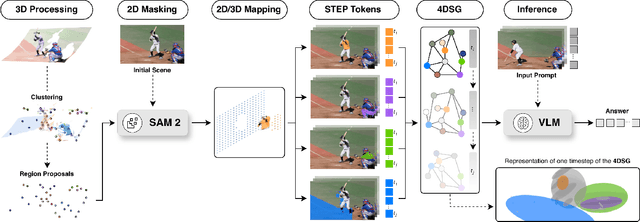
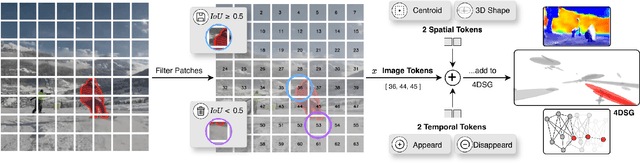
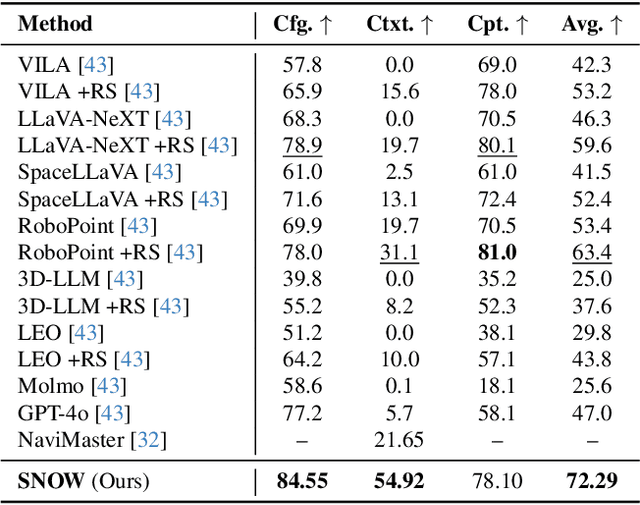
Autonomous robotic systems require spatio-temporal understanding of dynamic environments to ensure reliable navigation and interaction. While Vision-Language Models (VLMs) provide open-world semantic priors, they lack grounding in 3D geometry and temporal dynamics. Conversely, geometric perception captures structure and motion but remains semantically sparse. We propose SNOW (Scene Understanding with Open-World Knowledge), a training-free and backbone-agnostic framework for unified 4D scene understanding that integrates VLM-derived semantics with point cloud geometry and temporal consistency. SNOW processes synchronized RGB images and 3D point clouds, using HDBSCAN clustering to generate object-level proposals that guide SAM2-based segmentation. Each segmented region is encoded through our proposed Spatio-Temporal Tokenized Patch Encoding (STEP), producing multimodal tokens that capture localized semantic, geometric, and temporal attributes. These tokens are incrementally integrated into a 4D Scene Graph (4DSG), which serves as 4D prior for downstream reasoning. A lightweight SLAM backend anchors all STEP tokens spatially in the environment, providing the global reference alignment, and ensuring unambiguous spatial grounding across time. The resulting 4DSG forms a queryable, unified world model through which VLMs can directly interpret spatial scene structure and temporal dynamics. Experiments on a diverse set of benchmarks demonstrate that SNOW enables precise 4D scene understanding and spatially grounded inference, thereby setting new state-of-the-art performance in several settings, highlighting the importance of structured 4D priors for embodied reasoning and autonomous robotics.
R4: Retrieval-Augmented Reasoning for Vision-Language Models in 4D Spatio-Temporal Space
Dec 17, 2025Humans perceive and reason about their surroundings in four dimensions by building persistent, structured internal representations that encode semantic meaning, spatial layout, and temporal dynamics. These multimodal memories enable them to recall past events, infer unobserved states, and integrate new information into context-dependent reasoning. Inspired by this capability, we introduce R4, a training-free framework for retrieval-augmented reasoning in 4D spatio-temporal space that equips vision-language models (VLMs) with structured, lifelong memory. R4 continuously constructs a 4D knowledge database by anchoring object-level semantic descriptions in metric space and time, yielding a persistent world model that can be shared across agents. At inference, natural language queries are decomposed into semantic, spatial, and temporal keys to retrieve relevant observations, which are integrated into the VLM's reasoning. Unlike classical retrieval-augmented generation methods, retrieval in R4 operates directly in 4D space, enabling episodic and collaborative reasoning without training. Experiments on embodied question answering and navigation benchmarks demonstrate that R4 substantially improves retrieval and reasoning over spatio-temporal information compared to baselines, advancing a new paradigm for embodied 4D reasoning in dynamic environments.
Data Quality Matters: Quantifying Image Quality Impact on Machine Learning Performance
Mar 28, 2025
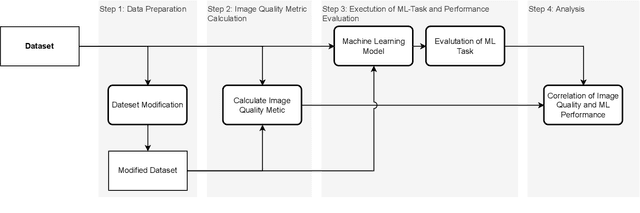
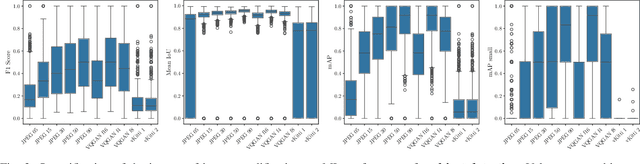
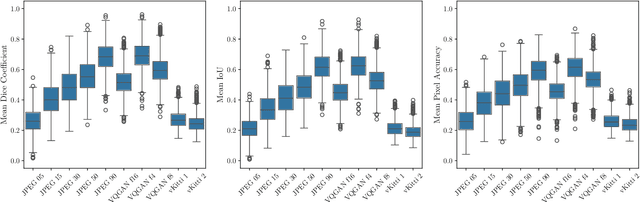
Precise perception of the environment is essential in highly automated driving systems, which rely on machine learning tasks such as object detection and segmentation. Compression of sensor data is commonly used for data handling, while virtualization is used for hardware-in-the-loop validation. Both methods can alter sensor data and degrade model performance. This necessitates a systematic approach to quantifying image validity. This paper presents a four-step framework to evaluate the impact of image modifications on machine learning tasks. First, a dataset with modified images is prepared to ensure one-to-one matching image pairs, enabling measurement of deviations resulting from compression and virtualization. Second, image deviations are quantified by comparing the effects of compression and virtualization against original camera-based sensor data. Third, the performance of state-of-the-art object detection models is analyzed to determine how altered input data affects perception tasks, including bounding box accuracy and reliability. Finally, a correlation analysis is performed to identify relationships between image quality and model performance. As a result, the LPIPS metric achieves the highest correlation between image deviation and machine learning performance across all evaluated machine learning tasks.
A Framework for a Capability-driven Evaluation of Scenario Understanding for Multimodal Large Language Models in Autonomous Driving
Mar 14, 2025Multimodal large language models (MLLMs) hold the potential to enhance autonomous driving by combining domain-independent world knowledge with context-specific language guidance. Their integration into autonomous driving systems shows promising results in isolated proof-of-concept applications, while their performance is evaluated on selective singular aspects of perception, reasoning, or planning. To leverage their full potential a systematic framework for evaluating MLLMs in the context of autonomous driving is required. This paper proposes a holistic framework for a capability-driven evaluation of MLLMs in autonomous driving. The framework structures scenario understanding along the four core capability dimensions semantic, spatial, temporal, and physical. They are derived from the general requirements of autonomous driving systems, human driver cognition, and language-based reasoning. It further organises the domain into context layers, processing modalities, and downstream tasks such as language-based interaction and decision-making. To illustrate the framework's applicability, two exemplary traffic scenarios are analysed, grounding the proposed dimensions in realistic driving situations. The framework provides a foundation for the structured evaluation of MLLMs' potential for scenario understanding in autonomous driving.
Adversarial and Reactive Traffic Agents for Realistic Driving Simulation
Sep 21, 2024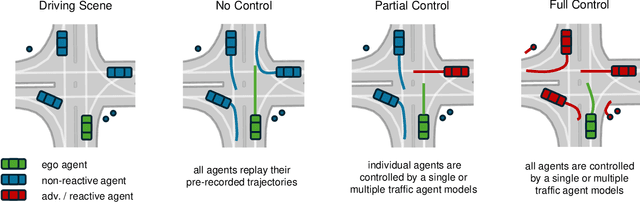
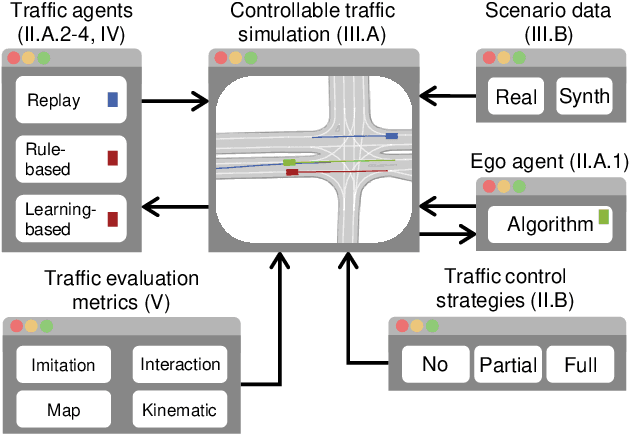
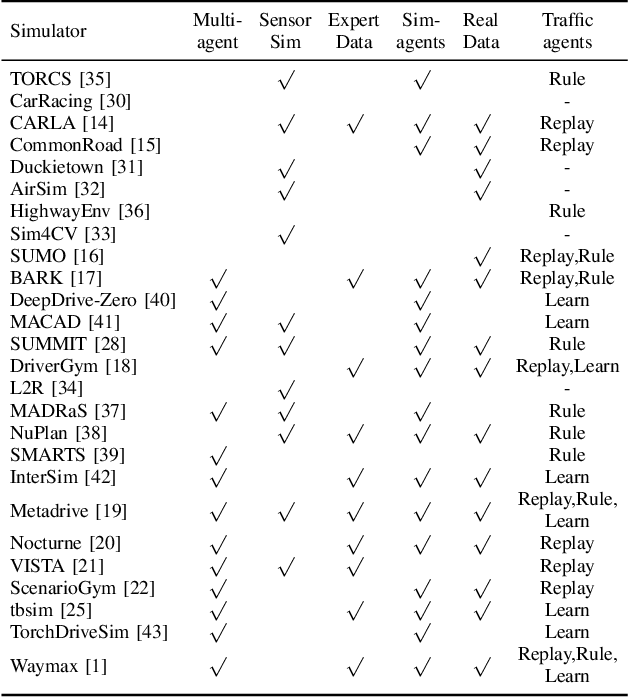
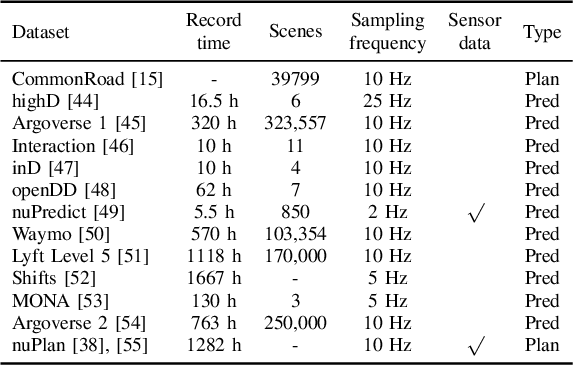
Despite advancements in perception and planning for autonomous vehicles (AVs), validating their performance remains a significant challenge. The deployment of planning algorithms in real-world environments is often ineffective due to discrepancies between simulations and real traffic conditions. Evaluating AVs planning algorithms in simulation typically involves replaying driving logs from recorded real-world traffic. However, agents replayed from offline data are not reactive, lack the ability to respond to arbitrary AV behavior, and cannot behave in an adversarial manner to test certain properties of the driving policy. Therefore, simulation with realistic and potentially adversarial agents represents a critical task for AV planning software validation. In this work, we aim to review current research efforts in the field of adversarial and reactive traffic agents, with a particular focus on the application of classical and adversarial learning-based techniques. The objective of this work is to categorize existing approaches based on the proposed scenario controllability, defined by the number of reactive or adversarial agents. Moreover, we examine existing traffic simulations with respect to their employed default traffic agents and potential extensions, collate datasets that provide initial driving data, and collect relevant evaluation metrics.
Navigating Dimensionality through State Machines in Automotive System Validation
Aug 20, 2024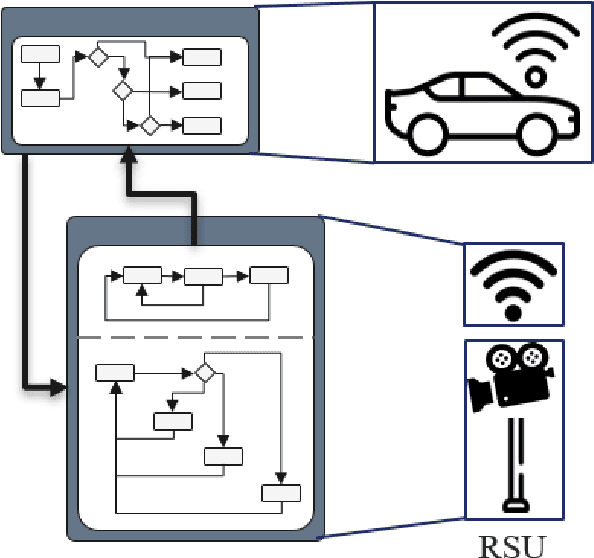

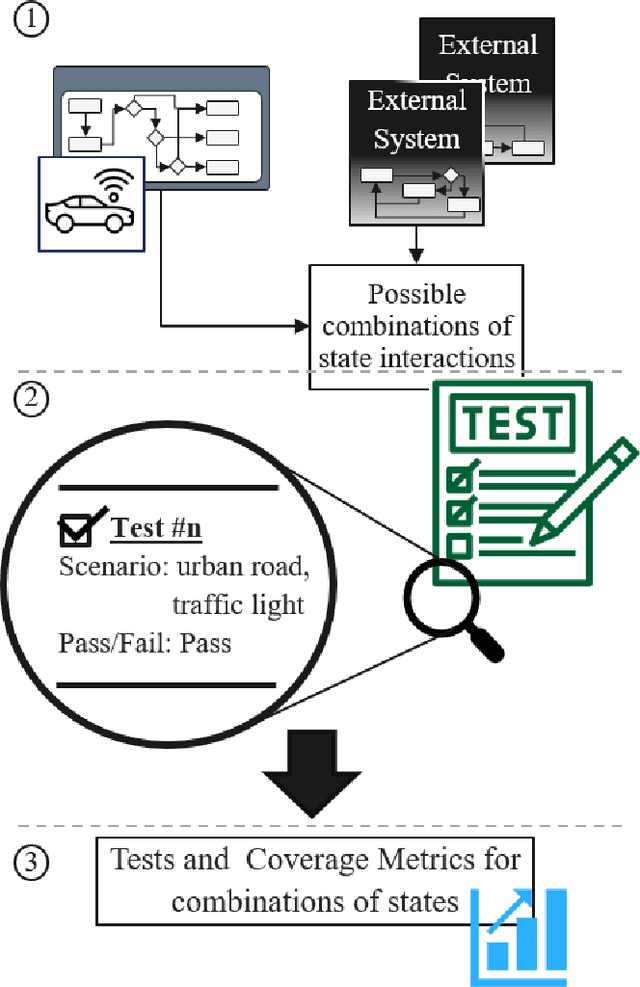
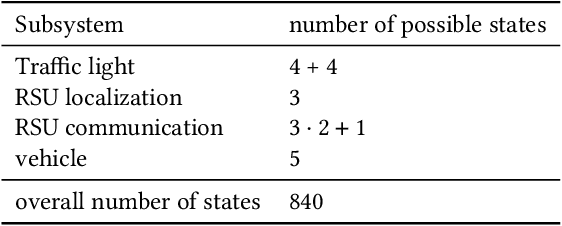
The increasing automation of vehicles is resulting in the integration of more extensive in-vehicle sensor systems, electronic control units, and software. Additionally, vehicle-to-everything communication is seen as an opportunity to extend automated driving capabilities through information from a source outside the ego vehicle. However, the validation and verification of automated driving functions already pose a challenge due to the number of possible scenarios that can occur for a driving function, which makes it difficult to achieve comprehensive test coverage. Currently, the establishment of Safety Of The Intended Functionality ( SOTIF ) mandates the implementation of scenario-based testing. The introduction of additional external systems through vehicle-to-everything further complicates the problem and increases the scenario space. In this paper, a methodology based on state charts is proposed for modeling the interaction with external systems, which may remain as black boxes. This approach leverages the testability and coverage analysis inherent in state charts by combining them with scenario-based testing. The overall objective is to reduce the space of scenarios necessary for testing a networked driving function and to streamline validation and verification. The utilization of this approach is demonstrated using a simulated signalized intersection with a roadside unit that detects vulnerable road users.
CLIPping the Limits: Finding the Sweet Spot for Relevant Images in Automated Driving Systems Perception Testing
Apr 08, 2024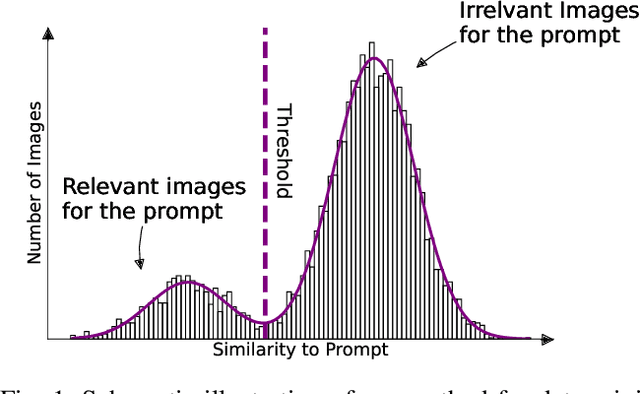
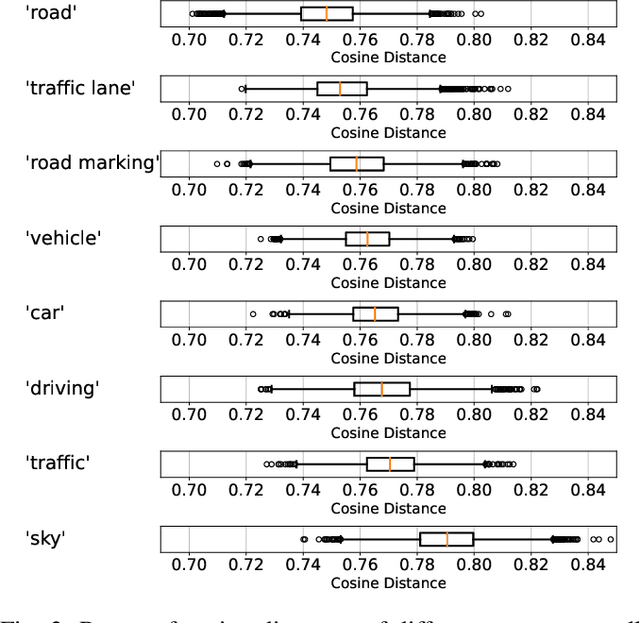
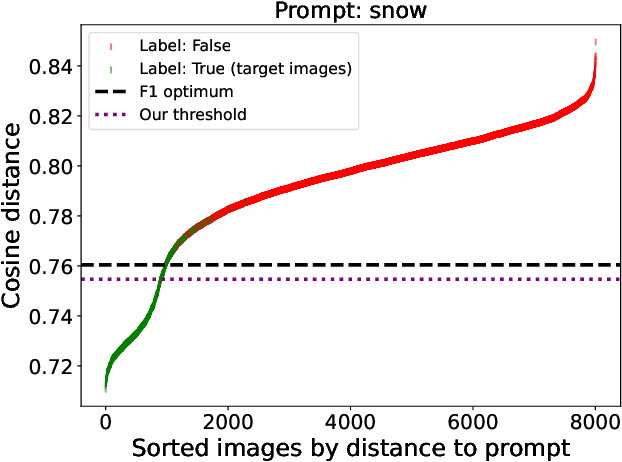
Perception systems, especially cameras, are the eyes of automated driving systems. Ensuring that they function reliably and robustly is therefore an important building block in the automation of vehicles. There are various approaches to test the perception of automated driving systems. Ultimately, however, it always comes down to the investigation of the behavior of perception systems under specific input data. Camera images are a crucial part of the input data. Image data sets are therefore collected for the testing of automated driving systems, but it is non-trivial to find specific images in these data sets. Thanks to recent developments in neural networks, there are now methods for sorting the images in a data set according to their similarity to a prompt in natural language. In order to further automate the provision of search results, we make a contribution by automating the threshold definition in these sorted results and returning only the images relevant to the prompt as a result. Our focus is on preventing false positives and false negatives equally. It is also important that our method is robust and in the case that our assumptions are not fulfilled, we provide a fallback solution.
The Machine Vision Iceberg Explained: Advancing Dynamic Testing by Considering Holistic Environmental Circumstances
Feb 05, 2024Are we heading for an iceberg with the current testing of machine vision? This work delves into the landscape of Machine Vision (MV) testing, which is heavily required in Highly Automated Driving (HAD) systems. Utilizing the metaphorical notion of navigating towards an iceberg, we discuss the potential shortcomings concealed within current testing strategies. We emphasize the urgent need for a deeper understanding of how to deal with the opaque functions of MV in development processes. As overlooked considerations can cost lives. Our main contribution is the hierarchical level model, which we call Granularity Grades. The model encourages a refined exploration of the multi-scaled depths of understanding about the circumstances of environments in which MV is intended to operate. This model aims to provide a holistic overview of all entities that may impact MV functions, ranging from relations of individual entities like object attributes to entire environmental scenes. The application of our model delivers a structured exploration of entities in a specific domain, their relationships and assigning results of a MV-under-test to construct an entity-relationship graph. Through clustering patterns of relations in the graph general MV deficits are arguable. In Summary, our work contributes to a more nuanced and systematized identification of deficits of a MV test object in correlation to holistic circumstances in HAD operating domains.
EfficientPPS: Part-aware Panoptic Segmentation of Transparent Objects for Robotic Manipulation
Dec 21, 2023The use of autonomous robots for assistance tasks in hospitals has the potential to free up qualified staff and im-prove patient care. However, the ubiquity of deformable and transparent objects in hospital settings poses signif-icant challenges to vision-based perception systems. We present EfficientPPS, a neural architecture for part-aware panoptic segmentation that provides robots with semantically rich visual information for grasping and ma-nipulation tasks. We also present an unsupervised data collection and labelling method to reduce the need for human involvement in the training process. EfficientPPS is evaluated on a dataset containing real-world hospital objects and demonstrated to be robust and efficient in grasping transparent transfusion bags with a collaborative robot arm.
* 8 pages, 8 figures, presented at the 56th International Symposium on Robotics (ISR Europe)