 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-Extrapolation: Generating Interactive Traffic Scenarios
Apr 26, 2024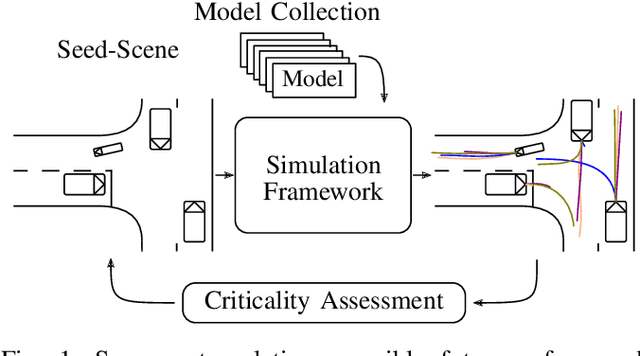
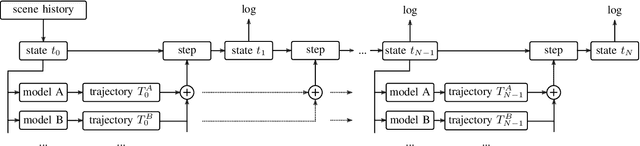
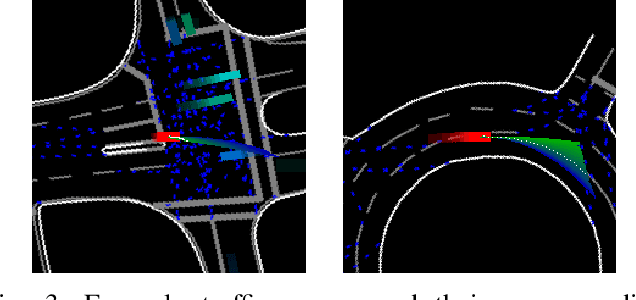
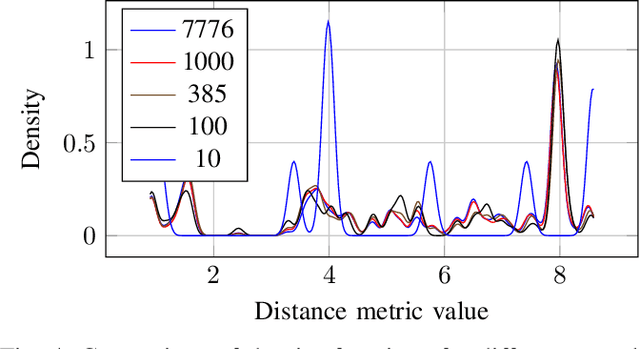
Verifying highly automated driving functions can be challenging, requiring identifying relevant test scenarios. Scenario-based testing will likely play a significant role in verifying these systems, predominantly occurring within simulation. In our approach, we use traffic scenes as a starting point (seed-scene) to address the individuality of various highly automated driving functions and to avoid the problems associated with a predefined test traffic scenario. Different highly autonomous driving functions, or their distinct iterations, may display different behaviors under the same operating conditions. To make a generalizable statement about a seed-scene, we simulate possible outcomes based on various behavior profiles. We utilize our lightweight simulation environment and populate it with rule-based and machine learning behavior models for individual actors in the scenario. We analyze resulting scenarios using a variety of criticality metrics. The density distributions of the resulting criticality values enable us to make a profound statement about the significance of a particular scene, considering various eventualities.
Exploring the Range of Possible Outcomes by means of Logical Scenario Analysis and Reduction for Testing Automated Driving Systems
Jun 22, 2023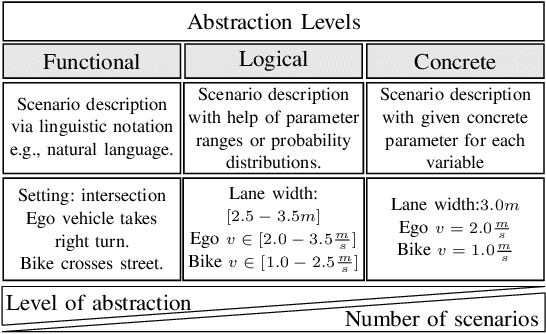
With the implementation of the new EU regulation 2022/1426 regarding the type-approval of the automated driving system (ADS) of fully automated vehicles, scenario-based testing has gained significant importance in evaluating the performance and safety of advanced driver assistance systems and automated driving systems. However, the exploration and generation of concrete scenarios from a single logical scenario can often lead to a number of similar or redundant scenarios, which may not contribute to the testing goals. This paper focuses on the the goal to reduce the scenario set by clustering concrete scenarios from a single logical scenario. By employing clustering techniques, redundant and uninteresting scenarios can be identified and eliminated, resulting in a representative scenario set. This reduction allows for a more focused and efficient testing process, enabling the allocation of resources to the most relevant and critical scenarios. Furthermore, the identified clusters can provide valuable insights into the scenario space, revealing patterns and potential problems with the system's behavior.
Inverse Universal Traffic Quality -- a Criticality Metric for Crowded Urban Traffic Scenes
Apr 21, 2023



An essential requirement for scenario-based testing the identification of critical scenes and their associated scenarios. However, critical scenes, such as collisions, occur comparatively rarely. Accordingly, large amounts of data must be examined. A further issue is that recorded real-world traffic often consists of scenes with a high number of vehicles, and it can be challenging to determine which are the most critical vehicles regarding the safety of an ego vehicle. Therefore, we present the inverse universal traffic quality, a criticality metric for urban traffic independent of predefined adversary vehicles and vehicle constellations such as intersection trajectories or car-following scenarios. Our metric is universally applicable for different urban traffic situations, e.g., intersections or roundabouts, and can be adjusted to certain situations if needed. Additionally, in this paper, we evaluate the proposed metric and compares its result to other well-known criticality metrics of this field, such as time-to-collision or post-encroachment time.
1001 Ways of Scenario Generation for Testing of Self-driving Cars: A Survey
Apr 21, 2023


Scenario generation is one of the essential steps in scenario-based testing and, therefore, a significant part of the verification and validation of driver assistance functions and autonomous driving systems. However, the term scenario generation is used for many different methods, e.g., extraction of scenarios from naturalistic driving data or variation of scenario parameters. This survey aims to give a systematic overview of different approaches, establish different categories of scenario acquisition and generation, and show that each group of methods has typical input and output types. It shows that although the term is often used throughout literature, the evaluated methods use different inputs and the resulting scenarios differ in abstraction level and from a systematical point of view. Additionally, recent research and literature examples are given to underline this categorization.
Fingerprint of a Traffic Scene: an Approach for a Generic and Independent Scene Assessment
Nov 24, 2022



A major challenge in the safety assessment of automated vehicles is to ensure that risk for all traffic participants is as low as possible. A concept that is becoming increasingly popular for testing in automated driving is scenario-based testing. It is founded on the assumption that most time on the road can be seen as uncritical and in mainly critical situations contribute to the safety case. Metrics describing the criticality are necessary to automatically identify the critical situations and scenarios from measurement data. However, established metrics lack universality or a concept for metric combination. In this work, we present a multidimensional evaluation model that, based on conventional metrics, can evaluate scenes independently of the scene type. Furthermore, we present two new, further enhanced evaluation approaches, which can additionally serve as universal metrics. The metrics we introduce are then evaluated and discussed using real data from a motion dataset.
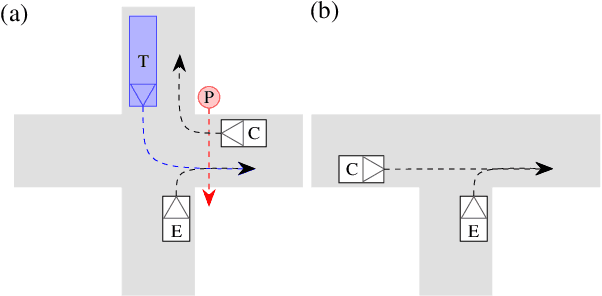
An Application of Scenario Exploration to Find New Scenarios for the Development and Testing of Automated Driving Systems in Urban Scenarios
May 17, 2022



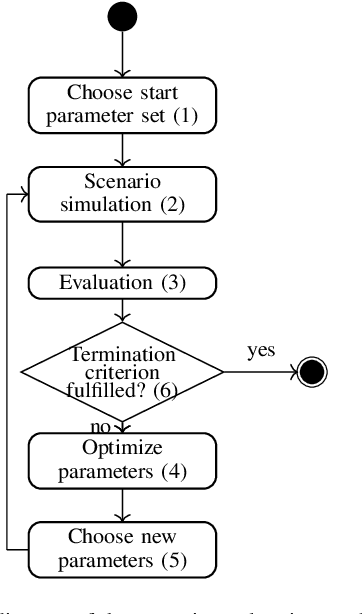
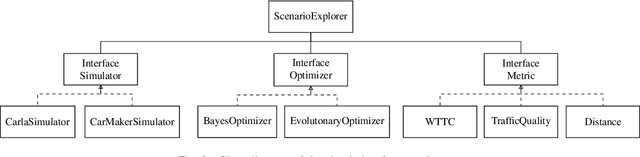
Verification and validation are major challenges for developing automated driving systems. A concept that gets more and more recognized for testing in automated driving is scenario-based testing. However, it introduces the problem of what scenarios are relevant for testing and which are not. This work aims to find relevant, interesting, or critical parameter sets within logical scenarios by utilizing Bayes optimization and Gaussian processes. The parameter optimization is done by comparing and evaluating six different metrics in two urban intersection scenarios. Finally, a list of ideas this work leads to and should be investigated further is presented.
Criticality Metrics for Automated Driving: A Review and Suitability Analysis of the State of the Art
Aug 05, 2021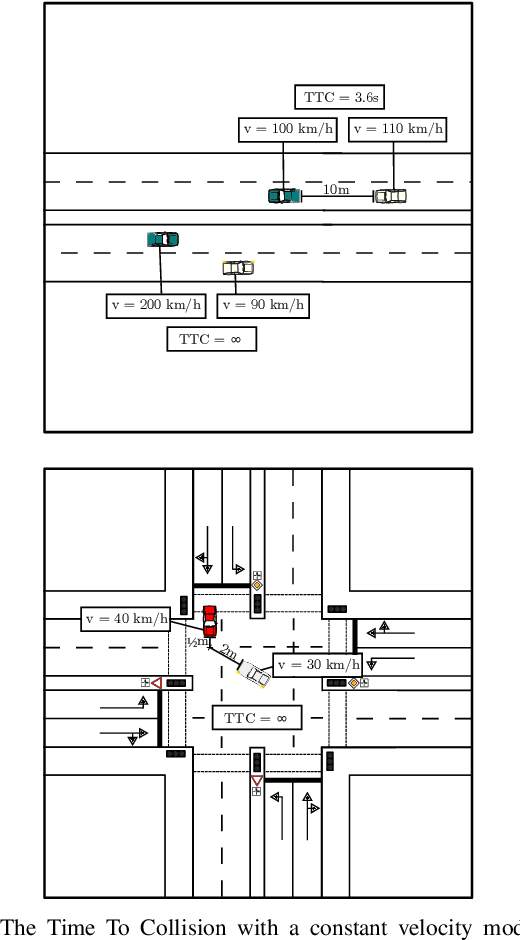

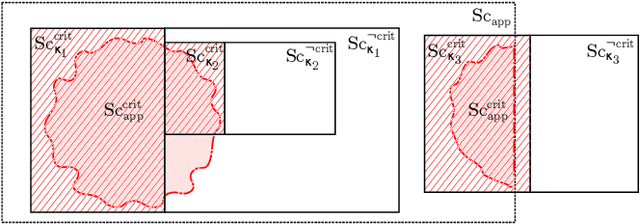

The large-scale deployment of automated vehicles on public roads has the potential to vastly change the transportation modalities of today's society. Although this pursuit has been initiated decades ago, there still exist open challenges in reliably ensuring that such vehicles operate safely in open contexts. While functional safety is a well-established concept, the question of measuring the behavioral safety of a vehicle remains subject to research. One way to both objectively and computationally analyze traffic conflicts is the development and utilization of so-called criticality metrics. Contemporary approaches have leveraged the potential of criticality metrics in various applications related to automated driving, e.g. for computationally assessing the dynamic risk or filtering large data sets to build scenario catalogs. As a prerequisite to systematically choose adequate criticality metrics for such applications, we extensively review the state of the art of criticality metrics, their properties, and their applications in the context of automated driving. Based on this review, we propose a suitability analysis as a methodical tool to be used by practitioners. Both the proposed method and the state of the art review can then be harnessed to select well-suited measurement tools that cover an application's requirements, as demonstrated by an exemplary execution of the analysis. Ultimately, efficient, valid, and reliable measurements of an automated vehicle's safety performance are a key requirement for demonstrating its trustworthiness.