 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCBench: A Streaming Counting Benchmark for Spatial-Temporal State Maintenance in Long Videos
Mar 13, 2026Video understanding requires models to continuously track and update world state during playback. While existing benchmarks have advanced video understanding evaluation across multiple dimensions, the observation of how models maintain world state remains insufficient. We propose VCBench, a streaming counting benchmark that repositions counting as a minimal probe for diagnosing world state maintenance capability. We decompose this capability into object counting (tracking currently visible objects vs.\ tracking cumulative unique identities) and event counting (detecting instantaneous actions vs.\ tracking complete activity cycles), forming 8 fine-grained subcategories. VCBench contains 406 videos with frame-by-frame annotations of 10,071 event occurrence moments and object state change moments, generating 1,000 streaming QA pairs with 4,576 query points along timelines. By observing state maintenance trajectories through streaming multi-point queries, we design three complementary metrics to diagnose numerical precision, trajectory consistency, and temporal awareness. Evaluation on mainstream video-language models shows that current models still exhibit significant deficiencies in spatial-temporal state maintenance, particularly struggling with tasks like periodic event counting. VCBench provides a diagnostic framework for measuring and improving state maintenance in video understanding systems.
Do Language Models Understand the Cognitive Tasks Given to Them? Investigations with the N-Back Paradigm
Dec 24, 2024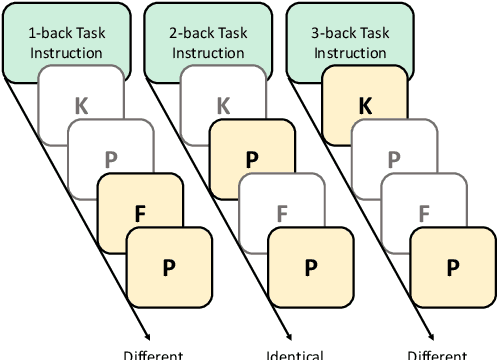

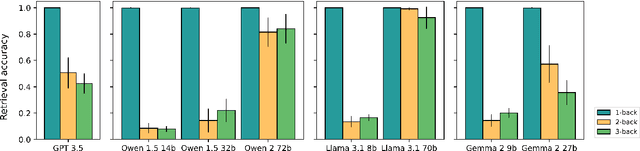

Cognitive tasks originally developed for humans are now increasingly used to study language models. While applying these tasks is often straightforward, interpreting their results can be challenging. In particular, when a model underperforms, it's often unclear whether this results from a limitation in the cognitive ability being tested or a failure to understand the task itself. A recent study argued that GPT 3.5's declining performance on 2-back and 3-back tasks reflects a working memory capacity limit similar to humans. By analyzing a range of open-source language models of varying performance levels on these tasks, we show that the poor performance instead reflects a limitation in task comprehension and task set maintenance. In addition, we push the best performing model to higher n values and experiment with alternative prompting strategies, before analyzing model attentions. Our larger aim is to contribute to the ongoing conversation around refining methodologies for the cognitive evaluation of language models.
In-Context Analogical Reasoning with Pre-Trained Language Models
Jun 05, 2023
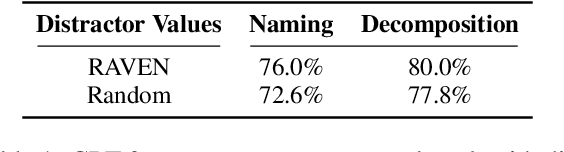

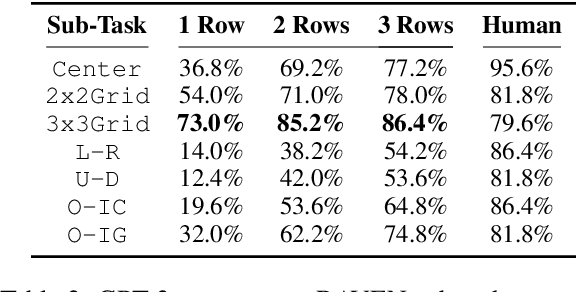
Analogical reasoning is a fundamental capacity of human cognition that allows us to reason abstractly about novel situations by relating them to past experiences. While it is thought to be essential for robust reasoning in AI systems, conventional approaches require significant training and/or hard-coding of domain knowledge to be applied to benchmark tasks. Inspired by cognitive science research that has found connections between human language and analogy-making, we explore the use of intuitive language-based abstractions to support analogy in AI systems. Specifically, we apply large pre-trained language models (PLMs) to visual Raven's Progressive Matrices (RPM), a common relational reasoning test. By simply encoding the perceptual features of the problem into language form, we find that PLMs exhibit a striking capacity for zero-shot relational reasoning, exceeding human performance and nearing supervised vision-based methods. We explore different encodings that vary the level of abstraction over task features, finding that higher-level abstractions further strengthen PLMs' analogical reasoning. Our detailed analysis reveals insights on the role of model complexity, in-context learning, and prior knowledge in solving RPM tasks.