Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping a Tagged Corpus through Combination of Existing Heterogeneous Taggers
Paper and Code
Jul 13, 2000
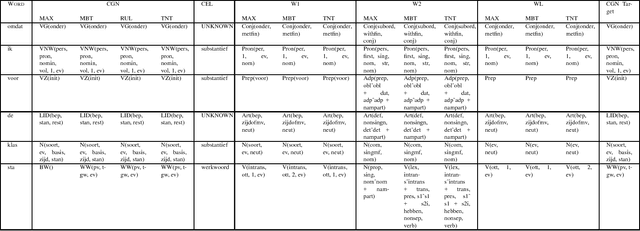
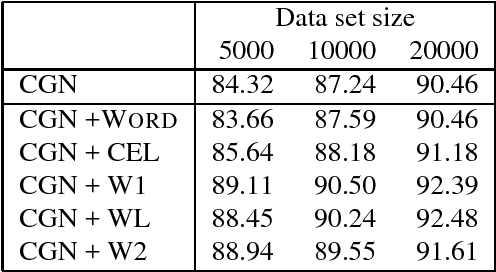

This paper describes a new method, Combi-bootstrap, to exploit existing taggers and lexical resources for the annotation of corpora with new tagsets. Combi-bootstrap uses existing resources as features for a second level machine learning module, that is trained to make the mapping to the new tagset on a very small sample of annotated corpus material. Experiments show that Combi-bootstrap: i) can integrate a wide variety of existing resources, and ii) achieves much higher accuracy (up to 44.7 % error reduction) than both the best single tagger and an ensemble tagger constructed out of the same small training sample.
* Proceedings of the 2nd International Conference on Language
Resources and Evaluation (LREC 2000), pp. 17--20 * 4 pages
View paper on