 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-based Language Models: An Efficient, Explainable, and Eco-friendly Approach to Large Language Modeling
Oct 25, 2025We present memory-based language modeling as an efficient, eco-friendly alternative to deep neural network-based language modeling. It offers log-linearly scalable next-token prediction performance and strong memorization capabilities. Implementing fast approximations of k-nearest neighbor classification, memory-based language modeling leaves a relatively small ecological footprint both in training and in inference mode, as it relies fully on CPUs and attains low token latencies. Its internal workings are simple and fully transparent. We compare our implementation of memory-based language modeling, OLIFANT, with GPT-2 and GPT-Neo on next-token prediction accuracy, estimated emissions and speeds, and offer some deeper analyses of the model.
Unsupervised Discovery of Phonological Categories through Supervised Learning of Morphological Rules
Jul 11, 1996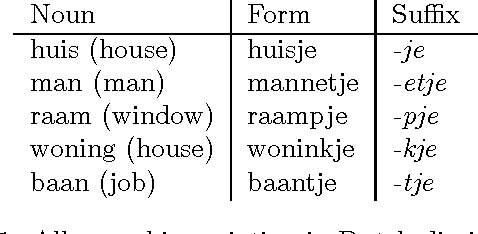
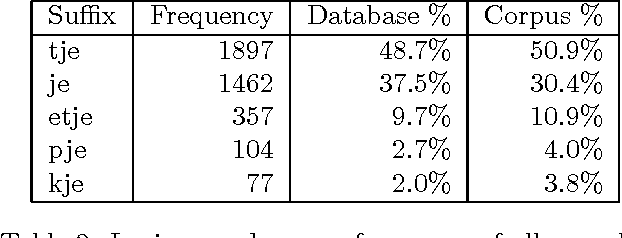
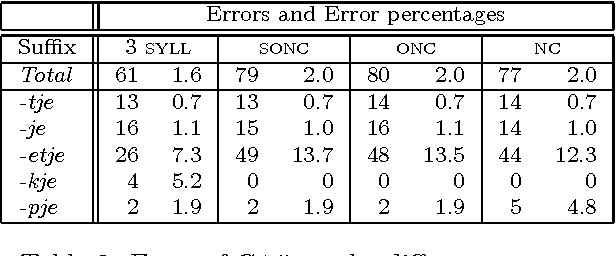
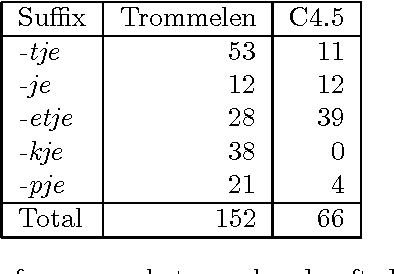
We describe a case study in the application of {\em symbolic machine learning} techniques for the discovery of linguistic rules and categories. A supervised rule induction algorithm is used to learn to predict the correct diminutive suffix given the phonological representation of Dutch nouns. The system produces rules which are comparable to rules proposed by linguists. Furthermore, in the process of learning this morphological task, the phonemes used are grouped into phonologically relevant categories. We discuss the relevance of our method for linguistics and language technology.
MBT: A Memory-Based Part of Speech Tagger-Generator
Jul 11, 1996



We introduce a memory-based approach to part of speech tagging. Memory-based learning is a form of supervised learning based on similarity-based reasoning. The part of speech tag of a word in a particular context is extrapolated from the most similar cases held in memory. Supervised learning approaches are useful when a tagged corpus is available as an example of the desired output of the tagger. Based on such a corpus, the tagger-generator automatically builds a tagger which is able to tag new text the same way, diminishing development time for the construction of a tagger considerably. Memory-based tagging shares this advantage with other statistical or machine learning approaches. Additional advantages specific to a memory-based approach include (i) the relatively small tagged corpus size sufficient for training, (ii) incremental learning, (iii) explanation capabilities, (iv) flexible integration of information in case representations, (v) its non-parametric nature, (vi) reasonably good results on unknown words without morphological analysis, and (vii) fast learning and tagging. In this paper we show that a large-scale application of the memory-based approach is feasible: we obtain a tagging accuracy that is on a par with that of known statistical approaches, and with attractive space and time complexity properties when using {\em IGTree}, a tree-based formalism for indexing and searching huge case bases.} The use of IGTree has as additional advantage that optimal context size for disambiguation is dynamically computed.
* 14 pages, 2 Postscript figures