Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Based Learning: Using Similarity for Smoothing
Paper and Code
May 12, 1997
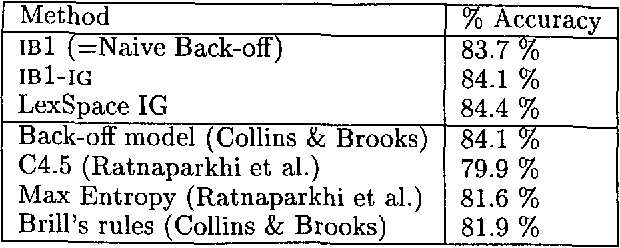

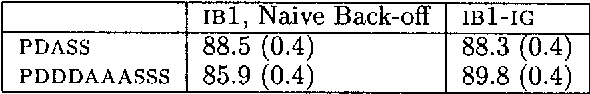
This paper analyses the relation between the use of similarity in Memory-Based Learning and the notion of backed-off smoothing in statistical language modeling. We show that the two approaches are closely related, and we argue that feature weighting methods in the Memory-Based paradigm can offer the advantage of automatically specifying a suitable domain-specific hierarchy between most specific and most general conditioning information without the need for a large number of parameters. We report two applications of this approach: PP-attachment and POS-tagging. Our method achieves state-of-the-art performance in both domains, and allows the easy integration of diverse information sources, such as rich lexical representations.
* 8 pages, uses aclap.sty, To appear in Proc. ACL/EACL 97
View paper on