 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Modeling of Social Concepts Evoked by Art Images as Multimodal Frames
Paper and Code
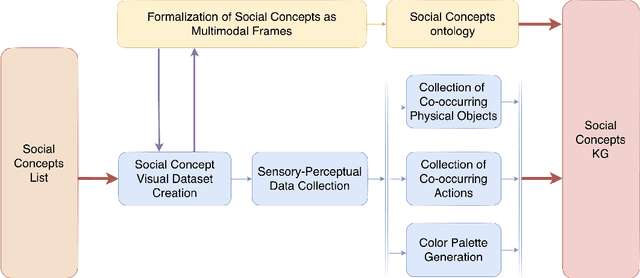
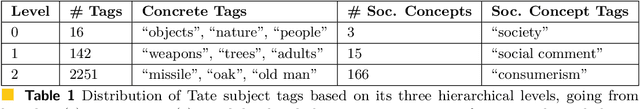
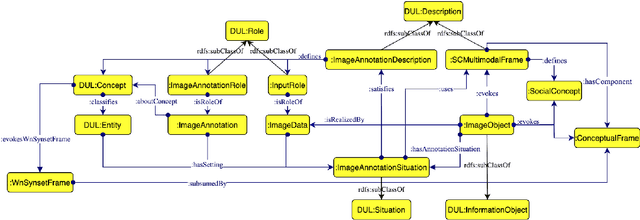
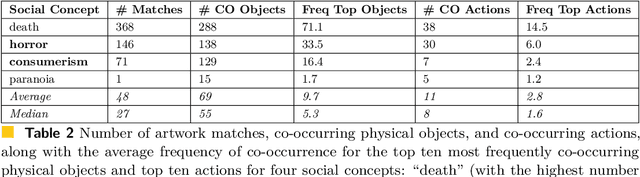
Social concepts referring to non-physical objects--such as revolution, violence, or friendship--are powerful tools to describe, index, and query the content of visual data, including ever-growing collections of art images from the Cultural Heritage (CH) field. While much progress has been made towards complete image understanding in computer vision, automatic detection of social concepts evoked by images is still a challenge. This is partly due to the well-known semantic gap problem, worsened for social concepts given their lack of unique physical features, and reliance on more unspecific features than concrete concepts. In this paper, we propose the translation of recent cognitive theories about social concept representation into a software approach to represent them as multimodal frames, by integrating multisensory data. Our method focuses on the extraction, analysis, and integration of multimodal features from visual art material tagged with the concepts of interest. We define a conceptual model and present a novel ontology for formally representing social concepts as multimodal frames. Taking the Tate Gallery's collection as an empirical basis, we experiment our method on a corpus of art images to provide a proof of concept of its potential. We discuss further directions of research, and provide all software, data sources, and results.