 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicate-Argument Structure Divergences in Chinese and English Parallel Sentences and their Impact on Language Transfer
Nov 12, 2025Cross-lingual Natural Language Processing (NLP) has gained significant traction in recent years, offering practical solutions in low-resource settings by transferring linguistic knowledge from resource-rich to low-resource languages. This field leverages techniques like annotation projection and model transfer for language adaptation, supported by multilingual pre-trained language models. However, linguistic divergences hinder language transfer, especially among typologically distant languages. In this paper, we present an analysis of predicate-argument structures in parallel Chinese and English sentences. We explore the alignment and misalignment of predicate annotations, inspecting similarities and differences and proposing a categorization of structural divergences. The analysis and the categorization are supported by a qualitative and quantitative analysis of the results of an annotation projection experiment, in which, in turn, one of the two languages has been used as source language to project annotations into the corresponding parallel sentences. The results of this analysis show clearly that language transfer is asymmetric. An aspect that requires attention when it comes to selecting the source language in transfer learning applications and that needs to be investigated before any scientific claim about cross-lingual NLP is proposed.
Musical Heritage Historical Entity Linking
Feb 13, 2025Linking named entities occurring in text to their corresponding entity in a Knowledge Base (KB) is challenging, especially when dealing with historical texts. In this work, we introduce Musical Heritage named Entities Recognition, Classification and Linking (MHERCL), a novel benchmark consisting of manually annotated sentences extrapolated from historical periodicals of the music domain. MHERCL contains named entities under-represented or absent in the most famous KBs. We experiment with several State-of-the-Art models on the Entity Linking (EL) task and show that MHERCL is a challenging dataset for all of them. We propose a novel unsupervised EL model and a method to extend supervised entity linkers by using Knowledge Graphs (KGs) to tackle the main difficulties posed by historical documents. Our experiments reveal that relying on unsupervised techniques and improving models with logical constraints based on KGs and heuristics to predict NIL entities (entities not represented in the KB of reference) results in better EL performance on historical documents.
Is Your Model Sensitive? SPeDaC: A New Benchmark for Detecting and Classifying Sensitive Personal Data
Aug 12, 2022



In recent years we have seen the exponential growth of applications, including dialogue systems, that handle sensitive personal information. This has brought to light the extremely important issue regarding personal data protection in virtual environments. Firstly, a performing model should be able to distinguish sentences with sensitive content from neutral sentences. Secondly, it should be able to identify the type of personal data category contained in them. In this way, a different privacy treatment could be considered for each category. In literature, if there are works on automatic sensitive data identification, these are often conducted on different domains or languages without a common benchmark. To fill this gap, in this work we introduce SPeDaC, a new annotated benchmark for the identification of sensitive personal data categories. Furthermore, we provide an extensive evaluation of our dataset, conducted using different baselines and a classifier based on RoBERTa, a neural architecture that achieves strong performances on the detection of sensitive sentences and on the personal data categories classification.
Tracing Antisemitic Language Through Diachronic Embedding Projections: France 1789-1914
Jun 04, 2019

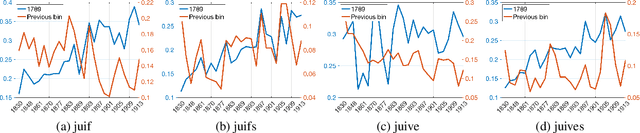

We investigate some aspects of the history of antisemitism in France, one of the cradles of modern antisemitism, using diachronic word embeddings. We constructed a large corpus of French books and periodicals issues that contain a keyword related to Jews and performed a diachronic word embedding over the 1789-1914 period. We studied the changes over time in the semantic spaces of 4 target words and performed embedding projections over 6 streams of antisemitic discourse. This allowed us to track the evolution of antisemitic bias in the religious, economic, socio-politic, racial, ethic and conspiratorial domains. Projections show a trend of growing antisemitism, especially in the years starting in the mid-80s and culminating in the Dreyfus affair. Our analysis also allows us to highlight the peculiar adverse bias towards Judaism in the broader context of other religions.
Analysis of Italian Word Embeddings
Nov 30, 2017
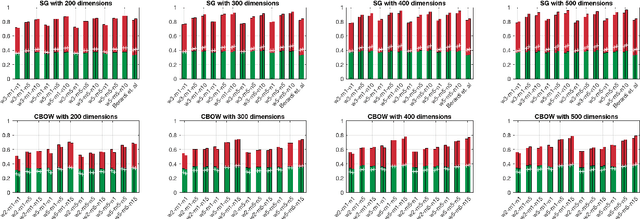


In this work we analyze the performances of two of the most used word embeddings algorithms, skip-gram and continuous bag of words on Italian language. These algorithms have many hyper-parameter that have to be carefully tuned in order to obtain accurate word representation in vectorial space. We provide an accurate analysis and an evaluation, showing what are the best configuration of parameters for specific tasks.
Context Aware Nonnegative Matrix Factorization Clustering
Sep 15, 2016



In this article we propose a method to refine the clustering results obtained with the nonnegative matrix factorization (NMF) technique, imposing consistency constraints on the final labeling of the data. The research community focused its effort on the initialization and on the optimization part of this method, without paying attention to the final cluster assignments. We propose a game theoretic framework in which each object to be clustered is represented as a player, which has to choose its cluster membership. The information obtained with NMF is used to initialize the strategy space of the players and a weighted graph is used to model the interactions among the players. These interactions allow the players to choose a cluster which is coherent with the clusters chosen by similar players, a property which is not guaranteed by NMF, since it produces a soft clustering of the data. The results on common benchmarks show that our model is able to improve the performances of many NMF formulations.
Document Clustering Games in Static and Dynamic Scenarios
Jul 08, 2016



In this work we propose a game theoretic model for document clustering. Each document to be clustered is represented as a player and each cluster as a strategy. The players receive a reward interacting with other players that they try to maximize choosing their best strategies. The geometry of the data is modeled with a weighted graph that encodes the pairwise similarity among documents, so that similar players are constrained to choose similar strategies, updating their strategy preferences at each iteration of the games. We used different approaches to find the prototypical elements of the clusters and with this information we divided the players into two disjoint sets, one collecting players with a definite strategy and the other one collecting players that try to learn from others the correct strategy to play. The latter set of players can be considered as new data points that have to be clustered according to previous information. This representation is useful in scenarios in which the data are streamed continuously. The evaluation of the system was conducted on 13 document datasets using different settings. It shows that the proposed method performs well compared to different document clustering algorithms.
A Game-Theoretic Approach to Word Sense Disambiguation
Jul 04, 2016This paper presents a new model for word sense disambiguation formulated in terms of evolutionary game theory, where each word to be disambiguated is represented as a node on a graph whose edges represent word relations and senses are represented as classes. The words simultaneously update their class membership preferences according to the senses that neighboring words are likely to choose. We use distributional information to weigh the influence that each word has on the decisions of the others and semantic similarity information to measure the strength of compatibility among the choices. With this information we can formulate the word sense disambiguation problem as a constraint satisfaction problem and solve it using tools derived from game theory, maintaining the textual coherence. The model is based on two ideas: similar words should be assigned to similar classes and the meaning of a word does not depend on all the words in a text but just on some of them. The paper provides an in-depth motivation of the idea of modeling the word sense disambiguation problem in terms of game theory, which is illustrated by an example. The conclusion presents an extensive analysis on the combination of similarity measures to use in the framework and a comparison with state-of-the-art systems. The results show that our model outperforms state-of-the-art algorithms and can be applied to different tasks and in different scenarios.