 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDA2Net: Digging under the surface of COVID-19 topics in scientific literature
Dec 03, 2021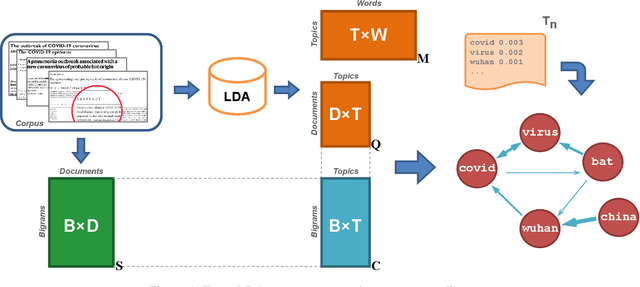



During the COVID-19 pandemic, the scientific literature related to SARS-COV-2 has been growing dramatically, both in terms of the number of publications and of its impact on people's life. This literature encompasses a varied set of sensible topics, ranging from vaccination, to protective equipment efficacy, to lockdown policy evaluation. Up to now, hundreds of thousands of papers have been uploaded on online repositories and published in scientific journals. As a result, the development of digital methods that allow an in-depth exploration of this growing literature has become a relevant issue, both to identify the topical trends of COVID-related research and to zoom-in its sub-themes. This work proposes a novel methodology, called LDA2Net, which combines topic modelling and network analysis to investigate topics under their surface. Specifically, LDA2Net exploits the frequencies of pairs of consecutive words to reconstruct the network structure of topics discussed in the Cord-19 corpus. The results suggest that the effectiveness of topic models can be magnified by enriching them with word network representations, and by using the latter to display, analyse, and explore COVID-related topics at different levels of granularity.
The Unfolding Structure of Arguments in Online Debates: The case of a No-Deal Brexit
Mar 09, 2021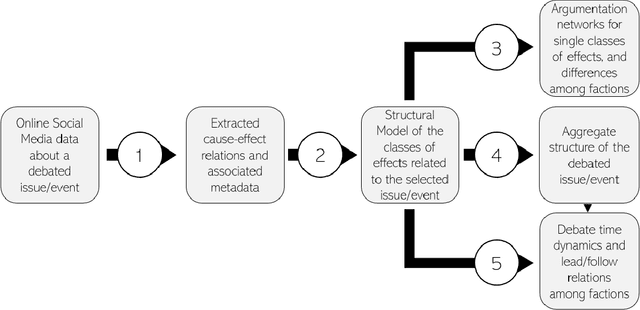

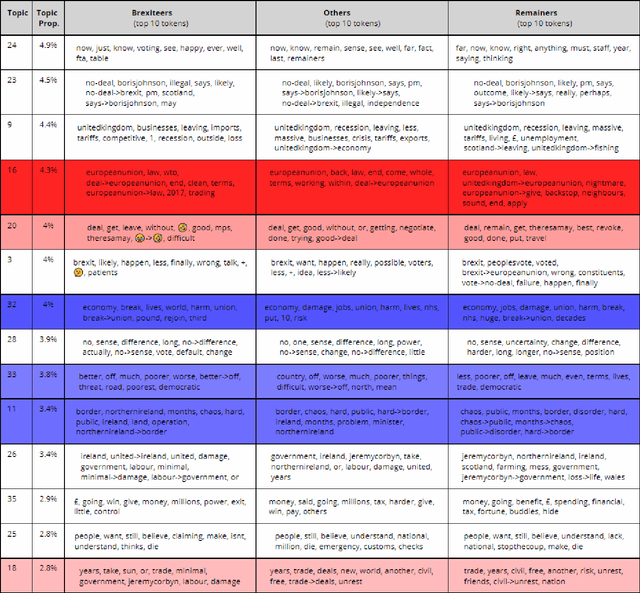
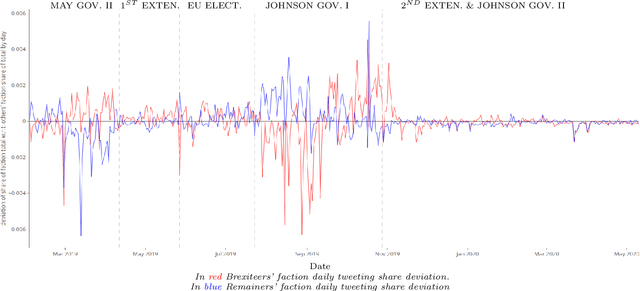
In the last decade, political debates have progressively shifted to social media. Rhetorical devices employed by online actors and factions that operate in these debating arenas can be captured and analysed to conduct a statistical reading of societal controversies and their argumentation dynamics. In this paper, we propose a five-step methodology, to extract, categorize and explore the latent argumentation structures of online debates. Using Twitter data about a "no-deal" Brexit, we focus on the expected effects in case of materialisation of this event. First, we extract cause-effect claims contained in tweets using RegEx that exploit verbs related to Creation, Destruction and Causation. Second, we categorise extracted "no-deal" effects using a Structural Topic Model estimated on unigrams and bigrams. Third, we select controversial effect topics and explore within-topic argumentation differences between self-declared partisan user factions. We hence type topics using estimated covariate effects on topic propensities, then, using the topics correlation network, we study the topological structure of the debate to identify coherent topical constellations. Finally, we analyse the debate time dynamics and infer lead/follow relations among factions. Results show that the proposed methodology can be employed to perform a statistical rhetorics analysis of debates, and map the architecture of controversies across time. In particular, the "no-deal" Brexit debate is shown to have an assortative argumentation structure heavily characterized by factional constellations of arguments, as well as by polarized narrative frames invoked through verbs related to Creation and Destruction. Our findings highlight the benefits of implementing a systemic approach to the analysis of debates, which allows the unveiling of topical and factional dependencies between arguments employed in online debates.
Tracing Antisemitic Language Through Diachronic Embedding Projections: France 1789-1914
Jun 04, 2019

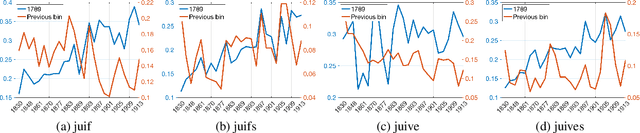

We investigate some aspects of the history of antisemitism in France, one of the cradles of modern antisemitism, using diachronic word embeddings. We constructed a large corpus of French books and periodicals issues that contain a keyword related to Jews and performed a diachronic word embedding over the 1789-1914 period. We studied the changes over time in the semantic spaces of 4 target words and performed embedding projections over 6 streams of antisemitic discourse. This allowed us to track the evolution of antisemitic bias in the religious, economic, socio-politic, racial, ethic and conspiratorial domains. Projections show a trend of growing antisemitism, especially in the years starting in the mid-80s and culminating in the Dreyfus affair. Our analysis also allows us to highlight the peculiar adverse bias towards Judaism in the broader context of other religions.