 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Retrieval for Claim Verification over Cross-Document Evidence
Paper and Code
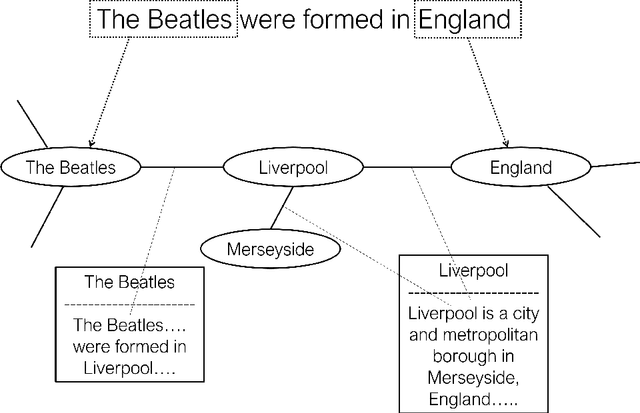
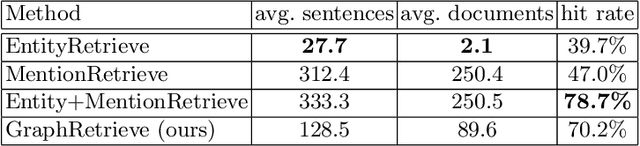
Verifying the veracity of claims requires reasoning over a large knowledge base, often in the form of corpora of trustworthy sources. A common approach consists in retrieving short portions of relevant text from the reference documents and giving them as input to a natural language inference module that determines whether the claim can be inferred or contradicted from them. This approach, however, struggles when multiple pieces of evidence need to be collected and combined from different documents, since the single documents are often barely related to the target claim and hence they are left out by the retrieval module. We conjecture that a graph-based approach can be beneficial to identify fragmented evidence. We tested this hypothesis by building, over the whole corpus, a large graph that interconnects text portions by means of mentioned entities and exploiting such a graph for identifying candidate sets of evidence from multiple sources. Our experiments show that leveraging on a graph structure is beneficial in identifying a reasonably small portion of passages related to a claim.