 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Persian Tokenizers
Feb 22, 2022
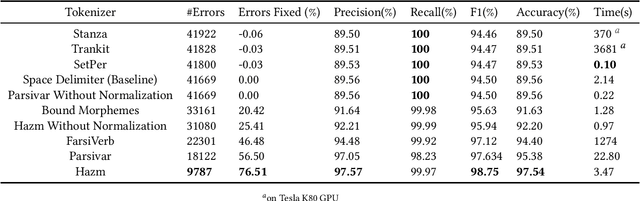
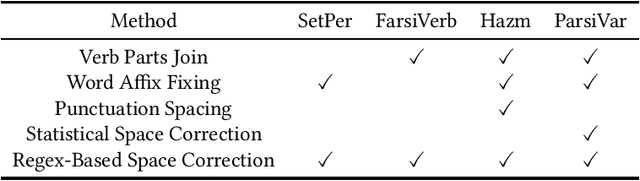
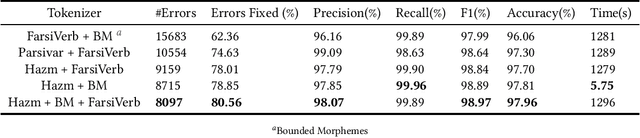
Tokenization plays a significant role in the process of lexical analysis. Tokens become the input for other natural language processing tasks, like semantic parsing and language modeling. Natural Language Processing in Persian is challenging due to Persian's exceptional cases, such as half-spaces. Thus, it is crucial to have a precise tokenizer for Persian. This article provides a novel work by introducing the most widely used tokenizers for Persian and comparing and evaluating their performance on Persian texts using a simple algorithm with a pre-tagged Persian dependency dataset. After evaluating tokenizers with the F1-Score, the hybrid version of the Farsi Verb and Hazm with bounded morphemes fixing showed the best performance with an F1 score of 98.97%.