 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Persian Tokenizers
Feb 22, 2022
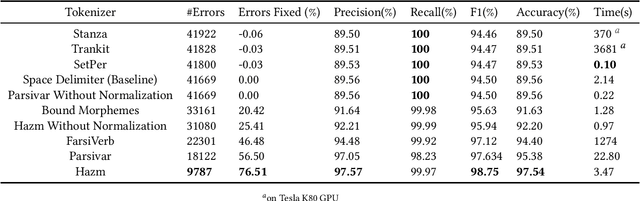
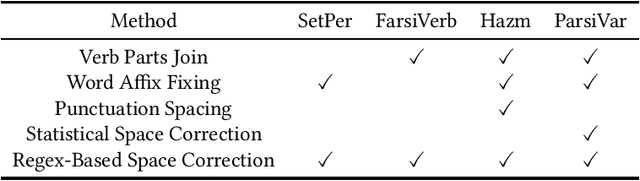
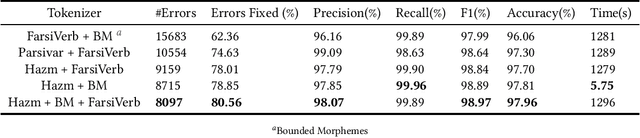
Tokenization plays a significant role in the process of lexical analysis. Tokens become the input for other natural language processing tasks, like semantic parsing and language modeling. Natural Language Processing in Persian is challenging due to Persian's exceptional cases, such as half-spaces. Thus, it is crucial to have a precise tokenizer for Persian. This article provides a novel work by introducing the most widely used tokenizers for Persian and comparing and evaluating their performance on Persian texts using a simple algorithm with a pre-tagged Persian dependency dataset. After evaluating tokenizers with the F1-Score, the hybrid version of the Farsi Verb and Hazm with bounded morphemes fixing showed the best performance with an F1 score of 98.97%.
An Unsupervised Language-Independent Entity Disambiguation Method and its Evaluation on the English and Persian Languages
Jan 31, 2021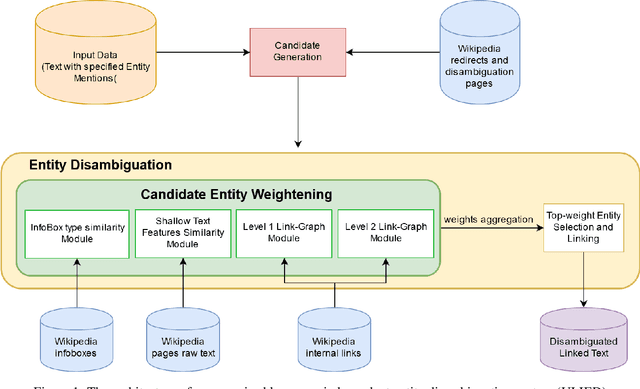
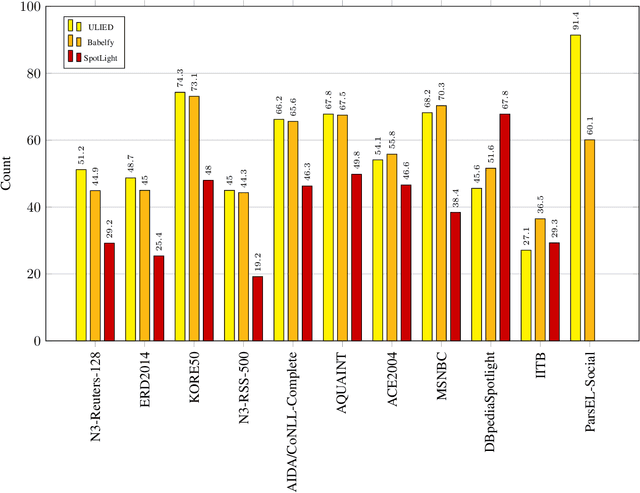
Entity Linking is one of the essential tasks of information extraction and natural language understanding. Entity linking mainly consists of two tasks: recognition and disambiguation of named entities. Most studies address these two tasks separately or focus only on one of them. Moreover, most of the state-of-the -art entity linking algorithms are either supervised, which have poor performance in the absence of annotated corpora or language-dependent, which are not appropriate for multi-lingual applications. In this paper, we introduce an Unsupervised Language-Independent Entity Disambiguation (ULIED), which utilizes a novel approach to disambiguate and link named entities. Evaluation of ULIED on different English entity linking datasets as well as the only available Persian dataset illustrates that ULIED in most of the cases outperforms the state-of-the-art unsupervised multi-lingual approaches.
PERLEX: A Bilingual Persian-English Gold Dataset for Relation Extraction
May 13, 2020

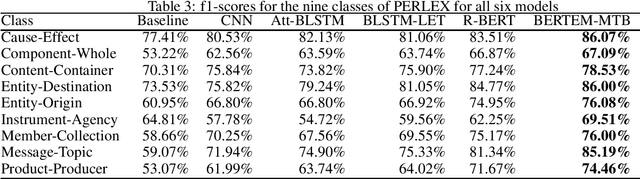
Relation extraction is the task of extracting semantic relations between entities in a sentence. It is an essential part of some natural language processing tasks such as information extraction, knowledge extraction, and knowledge base population. The main motivations of this research stem from a lack of a dataset for relation extraction in the Persian language as well as the necessity of extracting knowledge from the growing big-data in the Persian language for different applications. In this paper, we present "PERLEX" as the first Persian dataset for relation extraction, which is an expert-translated version of the "Semeval-2010-Task-8" dataset. Moreover, this paper addresses Persian relation extraction utilizing state-of-the-art language-agnostic algorithms. We employ six different models for relation extraction on the proposed bilingual dataset, including a non-neural model (as the baseline), three neural models, and two deep learning models fed by multilingual-BERT contextual word representations. The experiments result in the maximum f-score 77.66% (provided by BERTEM-MTB method) as the state-of-the-art of relation extraction in the Persian language.
FarsBase-KBP: A Knowledge Base Population System for the Persian Knowledge Graph
May 04, 2020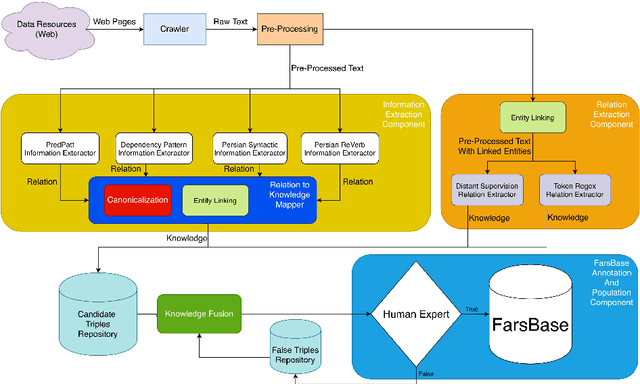

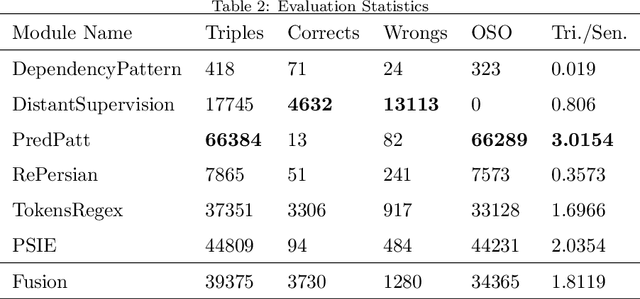
While most of the knowledge bases already support the English language, there is only one knowledge base for the Persian language, known as FarsBase, which is automatically created via semi-structured web information. Unlike English knowledge bases such as Wikidata, which have tremendous community support, the population of a knowledge base like FarsBase must rely on automatically extracted knowledge. Knowledge base population can let FarsBase keep growing in size, as the system continues working. In this paper, we present a knowledge base population system for the Persian language, which extracts knowledge from unlabeled raw text, crawled from the Web. The proposed system consists of a set of state-of-the-art modules such as an entity linking module as well as information and relation extraction modules designed for FarsBase. Moreover, a canonicalization system is introduced to link extracted relations to FarsBase properties. Then, the system uses knowledge fusion techniques with minimal intervention of human experts to integrate and filter the proper knowledge instances, extracted by each module. To evaluate the performance of the presented knowledge base population system, we present the first gold dataset for benchmarking knowledge base population in the Persian language, which consisting of 22015 FarsBase triples and verified by human experts. The evaluation results demonstrate the efficiency of the proposed system.