 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIR-RAG: Faithful Adaptive Iterative Refinement for Retrieval-Augmented Generation
Oct 25, 2025While Retrieval-Augmented Generation (RAG) mitigates hallucination and knowledge staleness in Large Language Models (LLMs), existing frameworks often falter on complex, multi-hop queries that require synthesizing information from disparate sources. Current advanced RAG methods, employing iterative or adaptive strategies, lack a robust mechanism to systematically identify and fill evidence gaps, often propagating noise or failing to gather a comprehensive context. We introduce FAIR-RAG, a novel agentic framework that transforms the standard RAG pipeline into a dynamic, evidence-driven reasoning process. At its core is an Iterative Refinement Cycle governed by a module we term Structured Evidence Assessment (SEA). The SEA acts as an analytical gating mechanism: it deconstructs the initial query into a checklist of required findings and audits the aggregated evidence to identify confirmed facts and, critically, explicit informational gaps. These gaps provide a precise signal to an Adaptive Query Refinement agent, which generates new, targeted sub-queries to retrieve missing information. This cycle repeats until the evidence is verified as sufficient, ensuring a comprehensive context for a final, strictly faithful generation. We conducted experiments on challenging multi-hop QA benchmarks, including HotpotQA, 2WikiMultiHopQA, and MusiQue. In a unified experimental setup, FAIR-RAG significantly outperforms strong baselines. On HotpotQA, it achieves an F1-score of 0.453 -- an absolute improvement of 8.3 points over the strongest iterative baseline -- establishing a new state-of-the-art for this class of methods on these benchmarks. Our work demonstrates that a structured, evidence-driven refinement process with explicit gap analysis is crucial for unlocking reliable and accurate reasoning in advanced RAG systems for complex, knowledge-intensive tasks.
An Unsupervised Language-Independent Entity Disambiguation Method and its Evaluation on the English and Persian Languages
Jan 31, 2021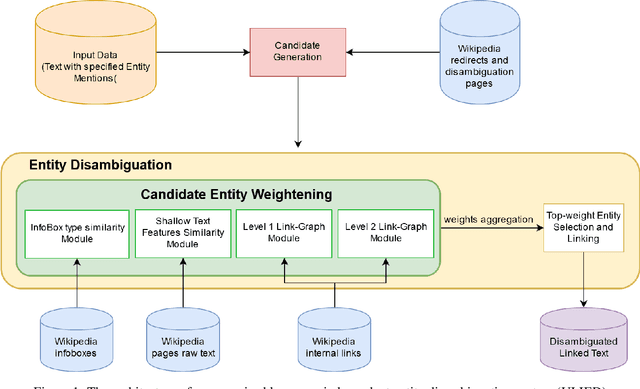
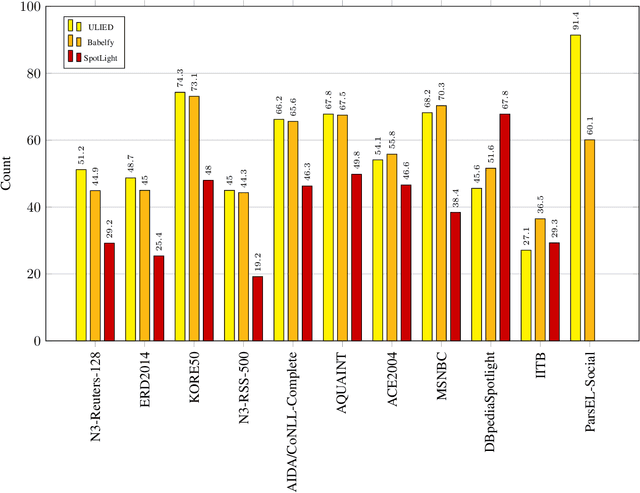
Entity Linking is one of the essential tasks of information extraction and natural language understanding. Entity linking mainly consists of two tasks: recognition and disambiguation of named entities. Most studies address these two tasks separately or focus only on one of them. Moreover, most of the state-of-the -art entity linking algorithms are either supervised, which have poor performance in the absence of annotated corpora or language-dependent, which are not appropriate for multi-lingual applications. In this paper, we introduce an Unsupervised Language-Independent Entity Disambiguation (ULIED), which utilizes a novel approach to disambiguate and link named entities. Evaluation of ULIED on different English entity linking datasets as well as the only available Persian dataset illustrates that ULIED in most of the cases outperforms the state-of-the-art unsupervised multi-lingual approaches.
PERLEX: A Bilingual Persian-English Gold Dataset for Relation Extraction
May 13, 2020

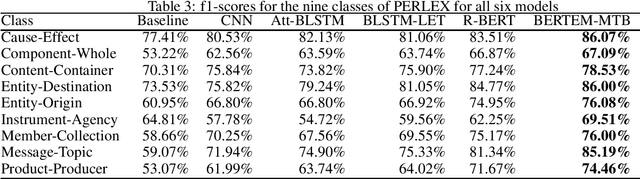
Relation extraction is the task of extracting semantic relations between entities in a sentence. It is an essential part of some natural language processing tasks such as information extraction, knowledge extraction, and knowledge base population. The main motivations of this research stem from a lack of a dataset for relation extraction in the Persian language as well as the necessity of extracting knowledge from the growing big-data in the Persian language for different applications. In this paper, we present "PERLEX" as the first Persian dataset for relation extraction, which is an expert-translated version of the "Semeval-2010-Task-8" dataset. Moreover, this paper addresses Persian relation extraction utilizing state-of-the-art language-agnostic algorithms. We employ six different models for relation extraction on the proposed bilingual dataset, including a non-neural model (as the baseline), three neural models, and two deep learning models fed by multilingual-BERT contextual word representations. The experiments result in the maximum f-score 77.66% (provided by BERTEM-MTB method) as the state-of-the-art of relation extraction in the Persian language.
FarsBase-KBP: A Knowledge Base Population System for the Persian Knowledge Graph
May 04, 2020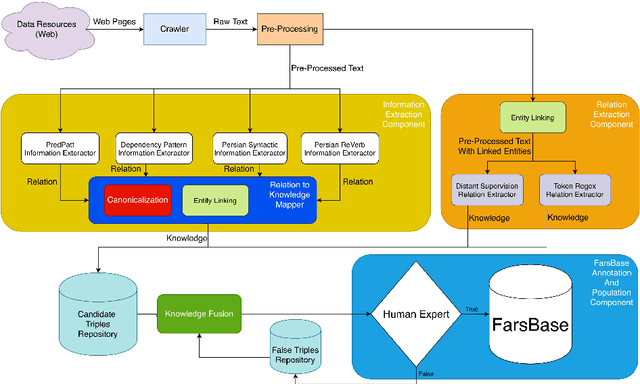

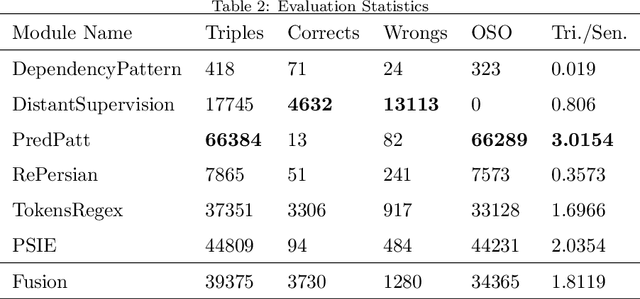
While most of the knowledge bases already support the English language, there is only one knowledge base for the Persian language, known as FarsBase, which is automatically created via semi-structured web information. Unlike English knowledge bases such as Wikidata, which have tremendous community support, the population of a knowledge base like FarsBase must rely on automatically extracted knowledge. Knowledge base population can let FarsBase keep growing in size, as the system continues working. In this paper, we present a knowledge base population system for the Persian language, which extracts knowledge from unlabeled raw text, crawled from the Web. The proposed system consists of a set of state-of-the-art modules such as an entity linking module as well as information and relation extraction modules designed for FarsBase. Moreover, a canonicalization system is introduced to link extracted relations to FarsBase properties. Then, the system uses knowledge fusion techniques with minimal intervention of human experts to integrate and filter the proper knowledge instances, extracted by each module. To evaluate the performance of the presented knowledge base population system, we present the first gold dataset for benchmarking knowledge base population in the Persian language, which consisting of 22015 FarsBase triples and verified by human experts. The evaluation results demonstrate the efficiency of the proposed system.
ParsEL 1.0: Unsupervised Entity Linking in Persian Social Media Texts
Apr 22, 2020
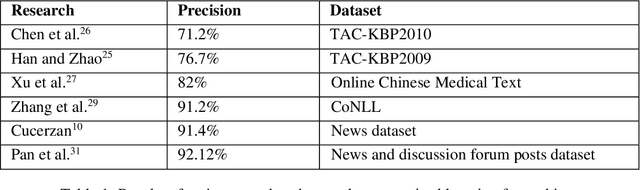
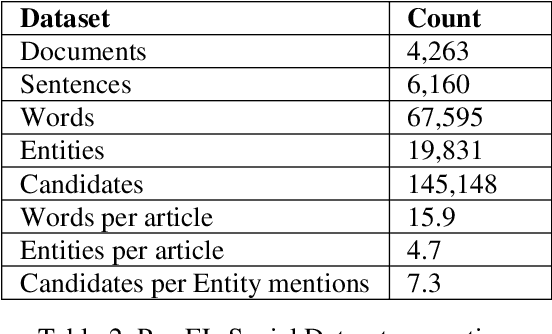

In recent years, social media data has exponentially increased, which can be enumerated as one of the largest data repositories in the world. A large portion of this social media data is natural language text. However, the natural language is highly ambiguous due to exposure to the frequent occurrences of entities, which have polysemous words or phrases. Entity linking is the task of linking the entity mentions in the text to their corresponding entities in a knowledge base. Recently, FarsBase, a Persian knowledge graph, has been introduced containing almost half a million entities. In this paper, we propose an unsupervised Persian Entity Linking system, the first entity linking system specially focused on the Persian language, which utilizes context-dependent and context-independent features. For this purpose, we also publish the first entity linking corpus of the Persian language containing 67,595 words that have been crawled from social media texts of some popular channels in the Telegram messenger. The output of the proposed method is 86.94% f-score for the Persian language, which is comparable with the similar state-of-the-art methods in the English language.