 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFarsBase-KBP: A Knowledge Base Population System for the Persian Knowledge Graph
Paper and Code
May 04, 2020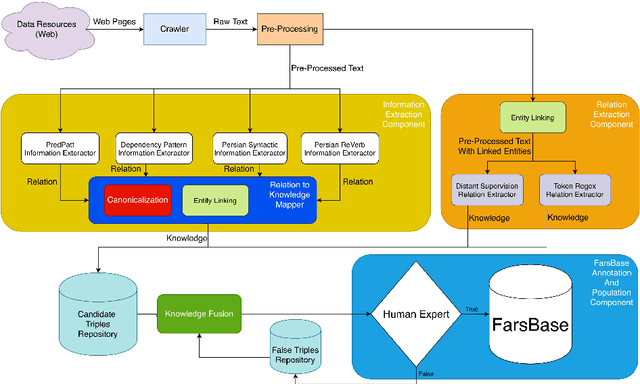

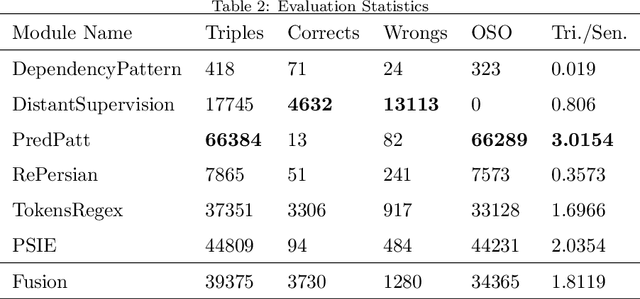
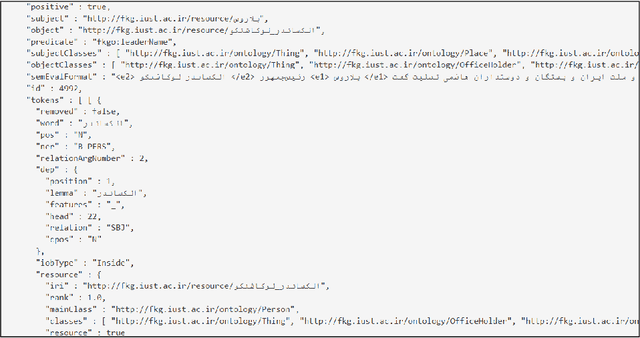
While most of the knowledge bases already support the English language, there is only one knowledge base for the Persian language, known as FarsBase, which is automatically created via semi-structured web information. Unlike English knowledge bases such as Wikidata, which have tremendous community support, the population of a knowledge base like FarsBase must rely on automatically extracted knowledge. Knowledge base population can let FarsBase keep growing in size, as the system continues working. In this paper, we present a knowledge base population system for the Persian language, which extracts knowledge from unlabeled raw text, crawled from the Web. The proposed system consists of a set of state-of-the-art modules such as an entity linking module as well as information and relation extraction modules designed for FarsBase. Moreover, a canonicalization system is introduced to link extracted relations to FarsBase properties. Then, the system uses knowledge fusion techniques with minimal intervention of human experts to integrate and filter the proper knowledge instances, extracted by each module. To evaluate the performance of the presented knowledge base population system, we present the first gold dataset for benchmarking knowledge base population in the Persian language, which consisting of 22015 FarsBase triples and verified by human experts. The evaluation results demonstrate the efficiency of the proposed system.