 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sample-Based Training Method for Distantly Supervised Relation Extraction with Pre-Trained Transformers
Apr 15, 2021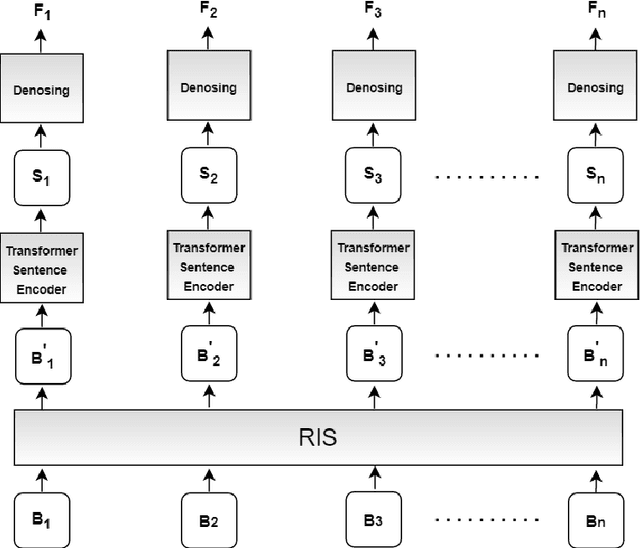
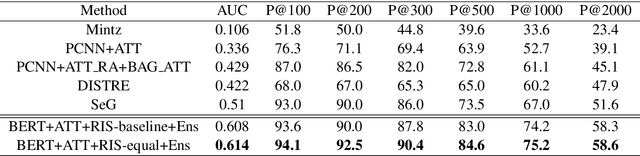

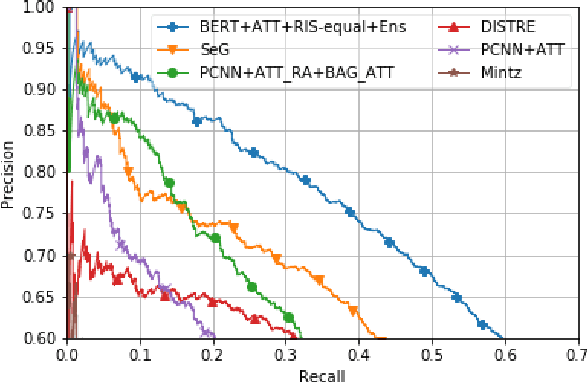
Multiple instance learning (MIL) has become the standard learning paradigm for distantly supervised relation extraction (DSRE). However, due to relation extraction being performed at bag level, MIL has significant hardware requirements for training when coupled with large sentence encoders such as deep transformer neural networks. In this paper, we propose a novel sampling method for DSRE that relaxes these hardware requirements. In the proposed method, we limit the number of sentences in a batch by randomly sampling sentences from the bags in the batch. However, this comes at the cost of losing valid sentences from bags. To alleviate the issues caused by random sampling, we use an ensemble of trained models for prediction. We demonstrate the effectiveness of our approach by using our proposed learning setting to fine-tuning BERT on the widely NYT dataset. Our approach significantly outperforms previous state-of-the-art methods in terms of AUC and P@N metrics.
PERLEX: A Bilingual Persian-English Gold Dataset for Relation Extraction
May 13, 2020

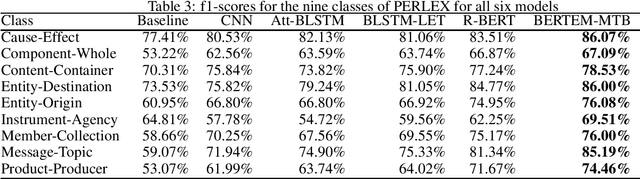
Relation extraction is the task of extracting semantic relations between entities in a sentence. It is an essential part of some natural language processing tasks such as information extraction, knowledge extraction, and knowledge base population. The main motivations of this research stem from a lack of a dataset for relation extraction in the Persian language as well as the necessity of extracting knowledge from the growing big-data in the Persian language for different applications. In this paper, we present "PERLEX" as the first Persian dataset for relation extraction, which is an expert-translated version of the "Semeval-2010-Task-8" dataset. Moreover, this paper addresses Persian relation extraction utilizing state-of-the-art language-agnostic algorithms. We employ six different models for relation extraction on the proposed bilingual dataset, including a non-neural model (as the baseline), three neural models, and two deep learning models fed by multilingual-BERT contextual word representations. The experiments result in the maximum f-score 77.66% (provided by BERTEM-MTB method) as the state-of-the-art of relation extraction in the Persian language.