 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterval Probabilistic Fuzzy WordNet
Apr 04, 2021
WordNet lexical-database groups English words into sets of synonyms called "synsets." Synsets are utilized for several applications in the field of text-mining. However, they were also open to criticism because although, in reality, not all the members of a synset represent the meaning of that synset with the same degree, in practice, they are considered as members of the synset, identically. Thus, the fuzzy version of synsets, called fuzzy-synsets (or fuzzy word-sense classes) were proposed and studied. In this study, we discuss why (type-1) fuzzy synsets (T1 F-synsets) do not properly model the membership uncertainty, and propose an upgraded version of fuzzy synsets in which membership degrees of word-senses are represented by intervals, similar to what in Interval Type 2 Fuzzy Sets (IT2 FS) and discuss that IT2 FS theoretical framework is insufficient for analysis and design of such synsets, and propose a new concept, called Interval Probabilistic Fuzzy (IPF) sets. Then we present an algorithm for constructing the IPF synsets in any language, given a corpus and a word-sense-disambiguation system. Utilizing our algorithm and the open-American-online-corpus (OANC) and UKB word-sense-disambiguation, we constructed and published the IPF synsets of WordNet for English language.
An Algorithm for Fuzzification of WordNets, Supported by a Mathematical Proof
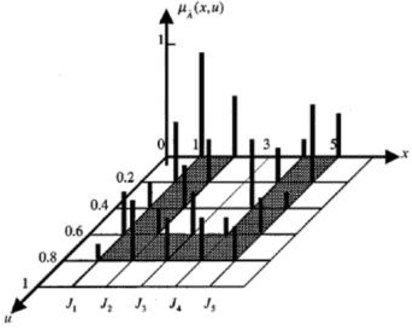
Jun 07, 2020WordNet-like Lexical Databases (WLDs) group English words into sets of synonyms called "synsets." Although the standard WLDs are being used in many successful Text-Mining applications, they have the limitation that word-senses are considered to represent the meaning associated to their corresponding synsets, to the same degree, which is not generally true. In order to overcome this limitation, several fuzzy versions of synsets have been proposed. A common trait of these studies is that, to the best of our knowledge, they do not aim to produce fuzzified versions of the existing WLD's, but build new WLDs from scratch, which has limited the attention received from the Text-Mining community, many of whose resources and applications are based on the existing WLDs. In this study, we present an algorithm for constructing fuzzy versions of WLDs of any language, given a corpus of documents and a word-sense disambiguation (WSD) system for that language. Then, using the Open-American-National-Corpus and UKB WSD as algorithm inputs, we construct and publish online the fuzzified version of English WordNet (FWN). We also propose a theoretical (mathematical) proof of the validity of its results.
A Linear-complexity Multi-biometric Forensic Document Analysis System, by Fusing the Stylome and Signature Modalities
Jan 26, 2019
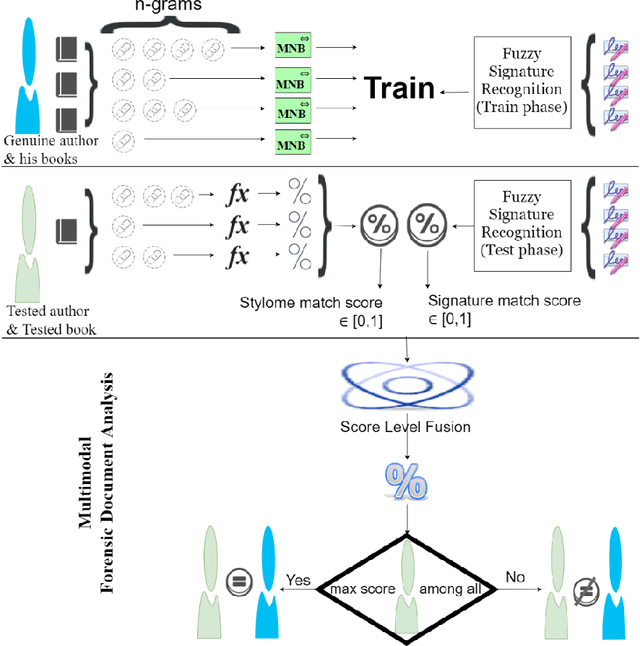
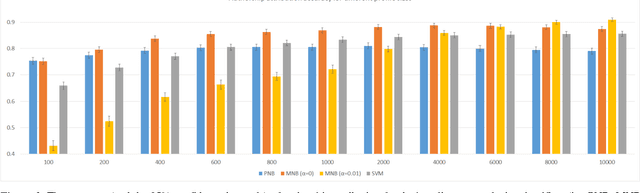
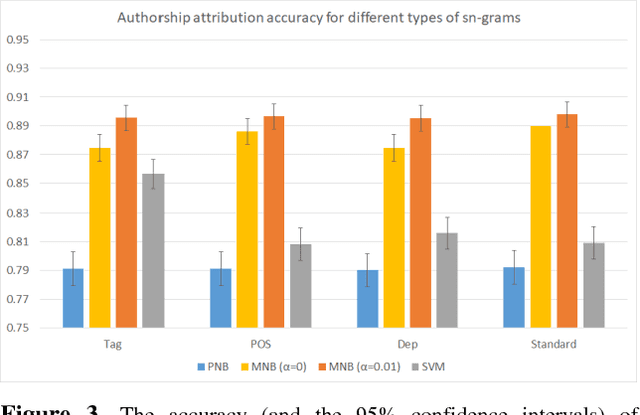
Forensic Document Analysis (FDA) addresses the problem of finding the authorship of a given document. Identification of the document writer via a number of its modalities (e.g. handwriting, signature, linguistic writing style (i.e. stylome), etc.) has been studied in the FDA state-of-the-art. But, no research is conducted on the fusion of stylome and signature modalities. In this paper, we propose such a bimodal FDA system (which has vast applications in judicial, police-related, and historical documents analysis) with a focus on time-complexity. The proposed bimodal system can be trained and tested with linear time complexity. For this purpose, we first revisit Multinomial Na\"ive Bayes (MNB), as the best state-of-the-art linear-complexity authorship attribution system and, then, prove its superior accuracy to the well-known linear-complexity classifiers in the state-of-the-art. Then, we propose a fuzzy version of MNB for being fused with a state-of-the-art well-known linear-complexity fuzzy signature recognition system. For the evaluation purposes, we construct a chimeric dataset, composed of signatures and textual contents of different letters. Despite its linear-complexity, the proposed multi-biometric system is proven to meaningfully improve its state-of-the-art unimodal counterparts, regarding the accuracy, F-Score, Detection Error Trade-off (DET), Cumulative Match Characteristics (CMC), and Match Score Histograms (MSH) evaluation metrics.