 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Reasoning in Generative Large Language Models
Paper and Code



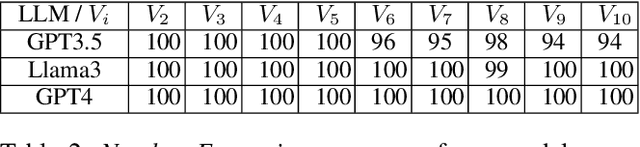
This paper considers the challenges that Large Language Models (LLMs) face when reasoning over text that includes information involving uncertainty explicitly quantified via probability values. This type of reasoning is relevant to a variety of contexts ranging from everyday conversations to medical decision-making. Despite improvements in the mathematical reasoning capabilities of LLMs, they still exhibit significant difficulties when it comes to probabilistic reasoning. To deal with this problem, we first introduce the Bayesian Linguistic Inference Dataset (BLInD), a new dataset specifically designed to test the probabilistic reasoning capabilities of LLMs. We then leverage this new dataset to thoroughly illustrate the specific limitations of LLMs for tasks involving probabilistic reasoning and present several strategies that map the problem to different formal representations, including Python code, probabilistic inference algorithms, and probabilistic logical programming. We conclude by providing an evaluation of our methods on BLInD and on an adaptation of a causal reasoning question-answering dataset, which further shows their practical effectiveness.