 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Tournament Solutions with Minimal Supports
Sep 11, 2025Tournaments are widely used models to represent pairwise dominance between candidates, alternatives, or teams. We study the problem of providing certified explanations for why a candidate appears among the winners under various tournament rules. To this end, we identify minimal supports, minimal sub-tournaments in which the candidate is guaranteed to win regardless of how the rest of the tournament is completed (that is, the candidate is a necessary winner of the sub-tournament). This notion corresponds to an abductive explanation for the question,"Why does the winner win the tournament", a central concept in formal explainable AI. We focus on common tournament solutions: the top cycle, the uncovered set, the Copeland rule, the Borda rule, the maximin rule, and the weighted uncovered set. For each rule we determine the size of the smallest minimal supports, and we present polynomial-time algorithms to compute them for all but the weighted uncovered set, for which the problem is NP-complete. Finally, we show how minimal supports can serve to produce compact, certified, and intuitive explanations.
Responsibility in a Multi-Value Strategic Setting
Oct 22, 2024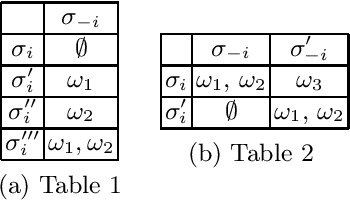
Responsibility is a key notion in multi-agent systems and in creating safe, reliable and ethical AI. However, most previous work on responsibility has only considered responsibility for single outcomes. In this paper we present a model for responsibility attribution in a multi-agent, multi-value setting. We also expand our model to cover responsibility anticipation, demonstrating how considerations of responsibility can help an agent to select strategies that are in line with its values. In particular we show that non-dominated regret-minimising strategies reliably minimise an agent's expected degree of responsibility.
Abductive and Contrastive Explanations for Scoring Rules in Voting
Aug 26, 2024

We view voting rules as classifiers that assign a winner (a class) to a profile of voters' preferences (an instance). We propose to apply techniques from formal explainability, most notably abductive and contrastive explanations, to identify minimal subsets of a preference profile that either imply the current winner or explain why a different candidate was not elected. Formal explanations turn out to have strong connections with classical problems studied in computational social choice such as bribery, possible and necessary winner identification, and preference learning. We design algorithms for computing abductive and contrastive explanations for scoring rules. For the Borda rule, we find a lower bound on the size of the smallest abductive explanations, and we conduct simulations to identify correlations between properties of preference profiles and the size of their smallest abductive explanations.
Large Language Models as Agents for Augmented Democracy
May 07, 2024



We explore the capabilities of an augmented democracy system built on off-the-shelf LLMs fine-tuned on data summarizing individual preferences across 67 policy proposals collected during the 2022 Brazilian presidential elections. We use a train-test cross-validation setup to estimate the accuracy with which the LLMs predict both: a subject's individual political choices and the aggregate preferences of the full sample of participants. At the individual level, the accuracy of the out of sample predictions lie in the range 69%-76% and are significantly better at predicting the preferences of liberal and college educated participants. At the population level, we aggregate preferences using an adaptation of the Borda score and compare the ranking of policy proposals obtained from a probabilistic sample of participants and from data augmented using LLMs. We find that the augmented data predicts the preferences of the full population of participants better than probabilistic samples alone when these represent less than 30% to 40% of the total population. These results indicate that LLMs are potentially useful for the construction of systems of augmented democracy.
Anticipating Responsibility in Multiagent Planning
Jul 31, 2023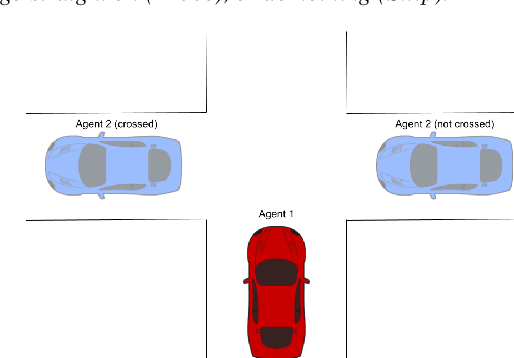
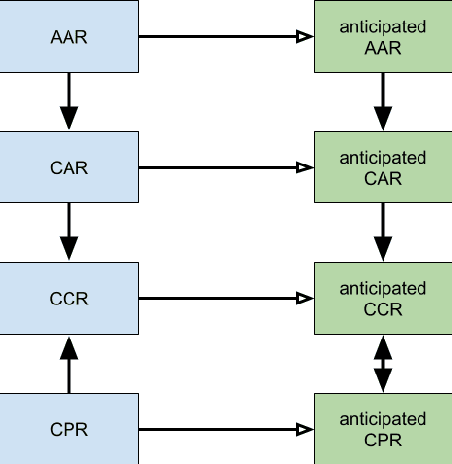
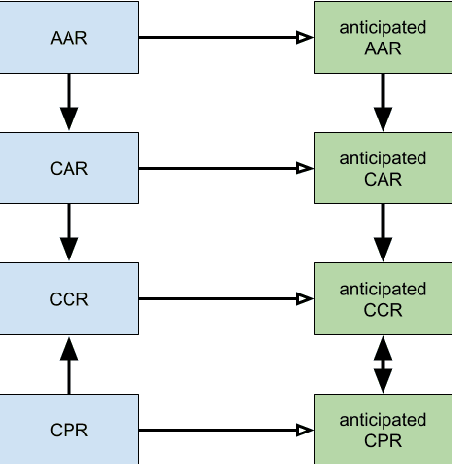
Responsibility anticipation is the process of determining if the actions of an individual agent may cause it to be responsible for a particular outcome. This can be used in a multi-agent planning setting to allow agents to anticipate responsibility in the plans they consider. The planning setting in this paper includes partial information regarding the initial state and considers formulas in linear temporal logic as positive or negative outcomes to be attained or avoided. We firstly define attribution for notions of active, passive and contributive responsibility, and consider their agentive variants. We then use these to define the notion of responsibility anticipation. We prove that our notions of anticipated responsibility can be used to coordinate agents in a planning setting and give complexity results for our model, discussing equivalence with classical planning. We also present an outline for solving some of our attribution and anticipation problems using PDDL solvers.
Measuring and Controlling Divisiveness in Rank Aggregation
Jun 14, 2023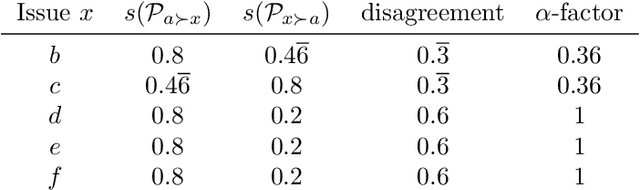
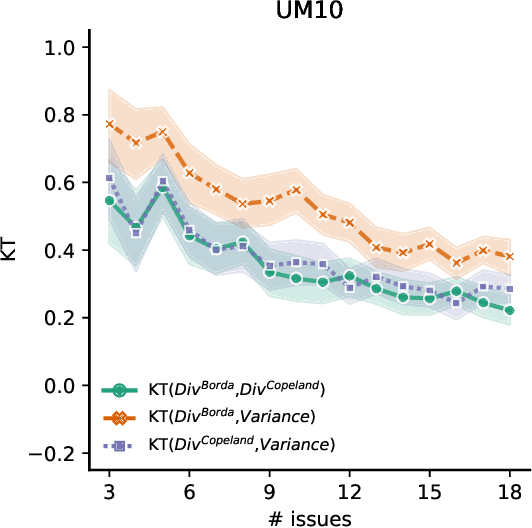

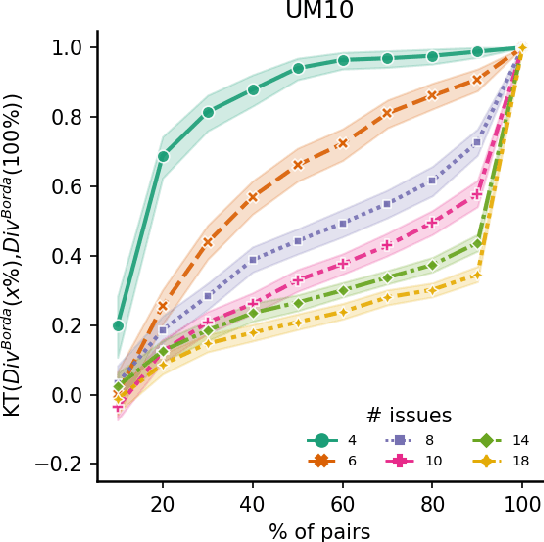
In rank aggregation, members of a population rank issues to decide which are collectively preferred. We focus instead on identifying divisive issues that express disagreements among the preferences of individuals. We analyse the properties of our divisiveness measures and their relation to existing notions of polarisation. We also study their robustness under incomplete preferences and algorithms for control and manipulation of divisiveness. Our results advance our understanding of how to quantify disagreements in collective decision-making.
Logic-Based Ethical Planning
Jun 02, 2022In this paper we propose a framework for ethical decision making in the context of planning, with intended application to robotics. We put forward a compact but highly expressive language for ethical planning that combines linear temporal logic with lexicographic preference modelling. This original combination allows us to assess plans both with respect to an agent's values and their desires, introducing the novel concept of the morality level of an agent and moving towards multigoal, multivalue planning. We initiate the study of computational complexity of planning tasks in our setting, and we discuss potential applications to robotics.
Collective discrete optimisation as judgment aggregation
Dec 01, 2021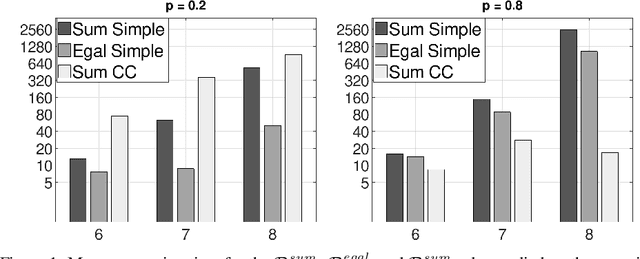
Many important collective decision-making problems can be seen as multi-agent versions of discrete optimisation problems. Participatory budgeting, for instance, is the collective version of the knapsack problem; other examples include collective scheduling, and collective spanning trees. Rather than developing a specific model, as well as specific algorithmic techniques, for each of these problems, we propose to represent and solve them in the unifying framework of judgment aggregation with weighted issues. We provide a modular definition of collective discrete optimisation (CDO) rules based on coupling a set scoring function with an operator, and we show how they generalise several existing procedures developed for specific CDO problems. We also give an implementation based on integer linear programming (ILP) and test it on the problem of collective spanning trees.
Unravelling multi-agent ranked delegations
Nov 25, 2021



We introduce a voting model with multi-agent ranked delegations. This model generalises liquid democracy in two aspects: first, an agent's delegation can use the votes of multiple other agents to determine their own -- for instance, an agent's vote may correspond to the majority outcome of the votes of a trusted group of agents; second, agents can submit a ranking over multiple delegations, so that a backup delegation can be used when their preferred delegations are involved in cycles. The main focus of this paper is the study of unravelling procedures that transform the delegation ballots received from the agents into a profile of direct votes, from which a winning alternative can then be determined by using a standard voting rule. We propose and study six such unravelling procedures, two based on optimisation and four using a greedy approach. We study both algorithmic and axiomatic properties, as well as related computational complexity problems of our unravelling procedures for different restrictions on the types of ballots that the agents can submit.
Aggregation in Value-Based Argumentation Frameworks
Jul 22, 2019



Value-based argumentation enhances a classical abstract argumentation graph - in which arguments are modelled as nodes connected by directed arrows called attacks - with labels on arguments, called values, and an ordering on values, called audience, to provide a more fine-grained justification of the attack relation. With more than one agent facing such an argumentation problem, agents may differ in their ranking of values. When needing to reach a collective view, such agents face a dilemma between two equally justifiable approaches: aggregating their views at the level of values, or aggregating their attack relations, remaining therefore at the level of the graphs. We explore the strenghts and limitations of both approaches, employing techniques from preference aggregation and graph aggregation, and propose a third possibility aggregating rankings extracted from given attack relations.
* In Proceedings TARK 2019, arXiv:1907.08335