 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Agents for Augmented Democracy
May 07, 2024



We explore the capabilities of an augmented democracy system built on off-the-shelf LLMs fine-tuned on data summarizing individual preferences across 67 policy proposals collected during the 2022 Brazilian presidential elections. We use a train-test cross-validation setup to estimate the accuracy with which the LLMs predict both: a subject's individual political choices and the aggregate preferences of the full sample of participants. At the individual level, the accuracy of the out of sample predictions lie in the range 69%-76% and are significantly better at predicting the preferences of liberal and college educated participants. At the population level, we aggregate preferences using an adaptation of the Borda score and compare the ranking of policy proposals obtained from a probabilistic sample of participants and from data augmented using LLMs. We find that the augmented data predicts the preferences of the full population of participants better than probabilistic samples alone when these represent less than 30% to 40% of the total population. These results indicate that LLMs are potentially useful for the construction of systems of augmented democracy.
Why do people judge humans differently from machines? The role of agency and experience
Oct 18, 2022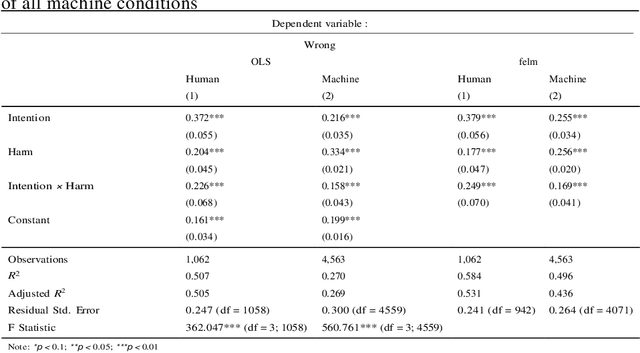
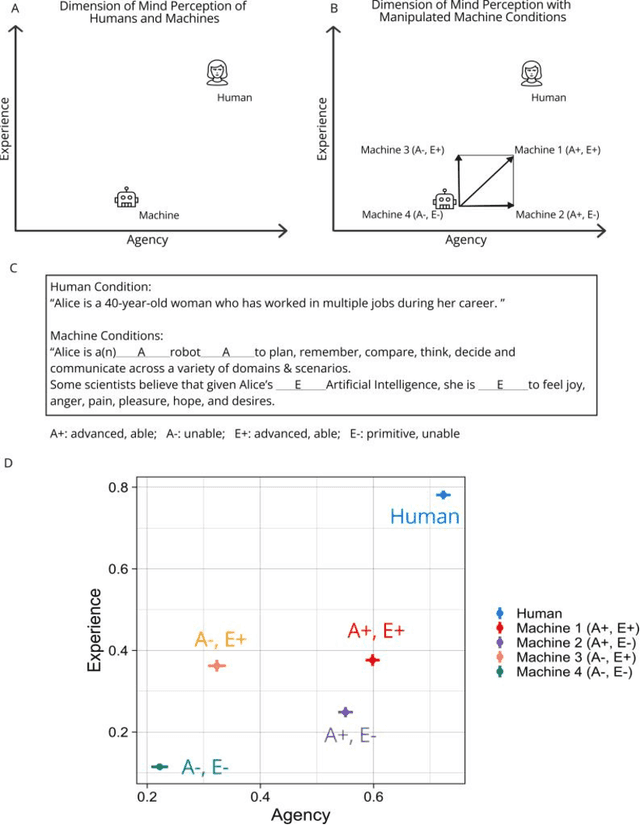
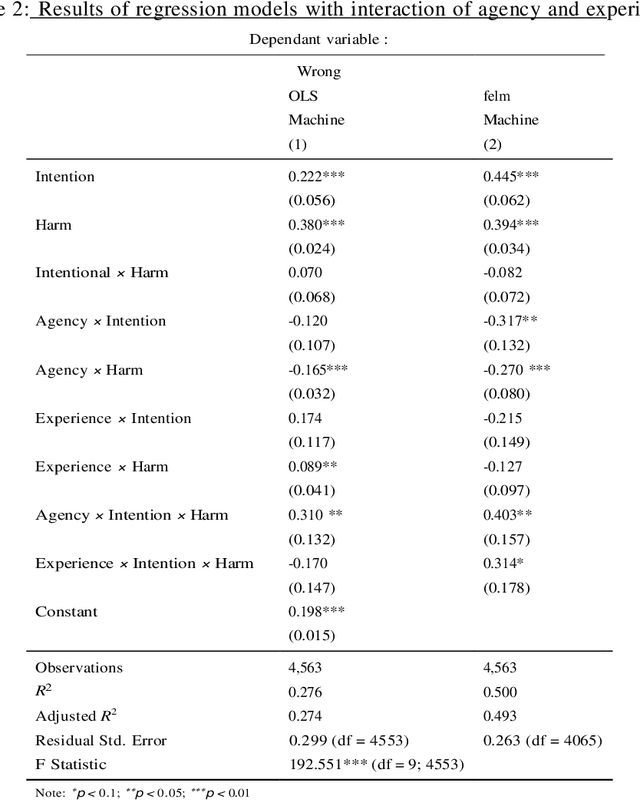
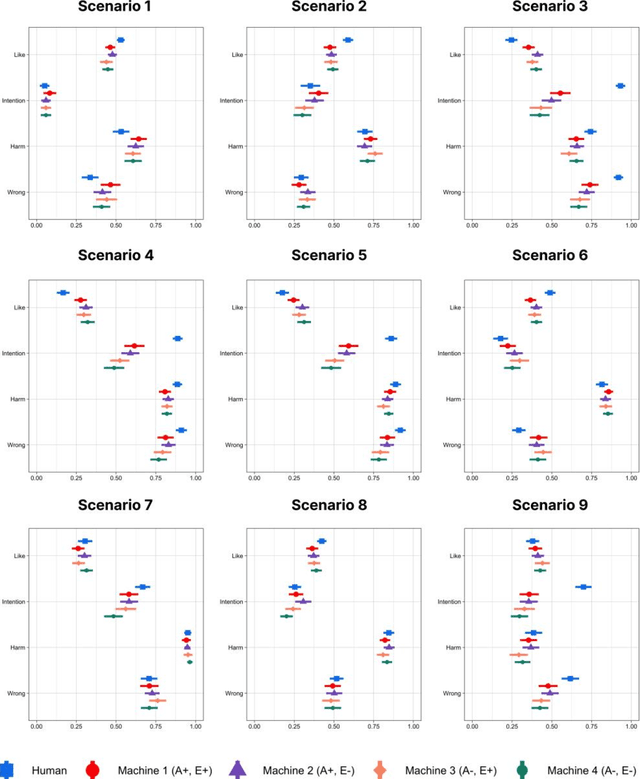
People are known to judge artificial intelligence using a utilitarian moral philosophy and humans using a moral philosophy emphasizing perceived intentions. But why do people judge humans and machines differently? Psychology suggests that people may have different mind perception models for humans and machines, and thus, will treat human-like robots more similarly to the way they treat humans. Here we present a randomized experiment where we manipulated people's perception of machines to explore whether people judge more human-like machines more similarly to the way they judge humans. We find that people's judgments of machines become more similar to that of humans when they perceive machines as having more agency (e.g. ability to plan, act), but not more experience (e.g. ability to feel). Our findings indicate that people's use of different moral philosophies to judge humans and machines can be explained by a progression of mind perception models where the perception of agency plays a prominent role. These findings add to the body of evidence suggesting that people's judgment of machines becomes more similar to that of humans motivating further work on differences in the judgment of human and machine actions.
VizML: A Machine Learning Approach to Visualization Recommendation
Aug 14, 2018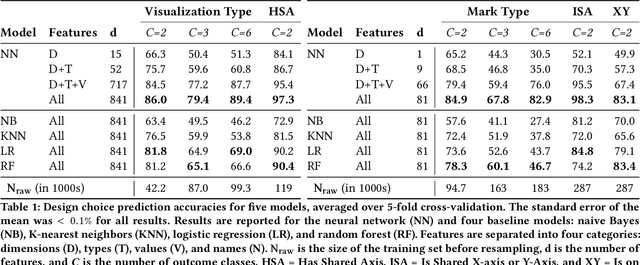
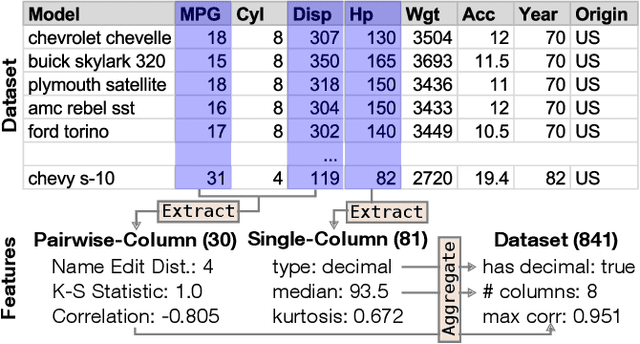
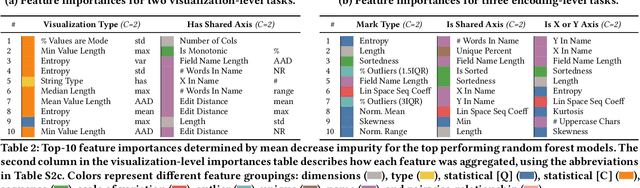
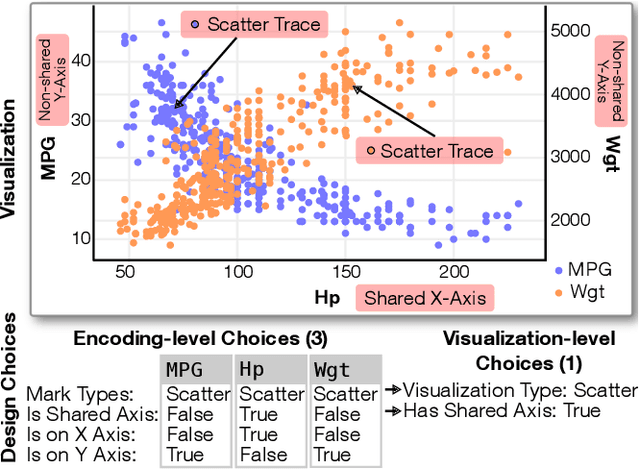
Data visualization should be accessible for all analysts with data, not just the few with technical expertise. Visualization recommender systems aim to lower the barrier to exploring basic visualizations by automatically generating results for analysts to search and select, rather than manually specify. Here, we demonstrate a novel machine learning-based approach to visualization recommendation that learns visualization design choices from a large corpus of datasets and associated visualizations. First, we identify five key design choices made by analysts while creating visualizations, such as selecting a visualization type and choosing to encode a column along the X- or Y-axis. We train models to predict these design choices using one million dataset-visualization pairs collected from a popular online visualization platform. Neural networks predict these design choices with high accuracy compared to baseline models. We report and interpret feature importances from one of these baseline models. To evaluate the generalizability and uncertainty of our approach, we benchmark with a crowdsourced test set, and show that the performance of our model is comparable to human performance when predicting consensus visualization type, and exceeds that of other ML-based systems.
Deep Learning the City : Quantifying Urban Perception At A Global Scale
Sep 12, 2016
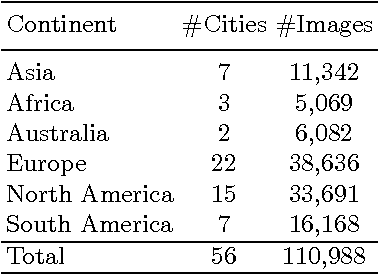
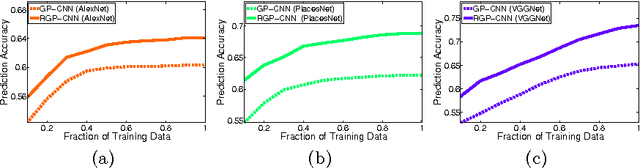
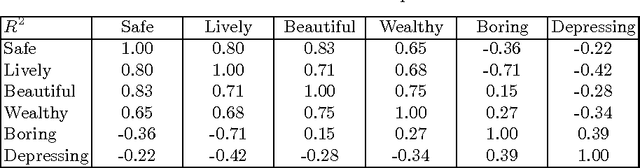
Computer vision methods that quantify the perception of urban environment are increasingly being used to study the relationship between a city's physical appearance and the behavior and health of its residents. Yet, the throughput of current methods is too limited to quantify the perception of cities across the world. To tackle this challenge, we introduce a new crowdsourced dataset containing 110,988 images from 56 cities, and 1,170,000 pairwise comparisons provided by 81,630 online volunteers along six perceptual attributes: safe, lively, boring, wealthy, depressing, and beautiful. Using this data, we train a Siamese-like convolutional neural architecture, which learns from a joint classification and ranking loss, to predict human judgments of pairwise image comparisons. Our results show that crowdsourcing combined with neural networks can produce urban perception data at the global scale.