 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollective discrete optimisation as judgment aggregation
Dec 01, 2021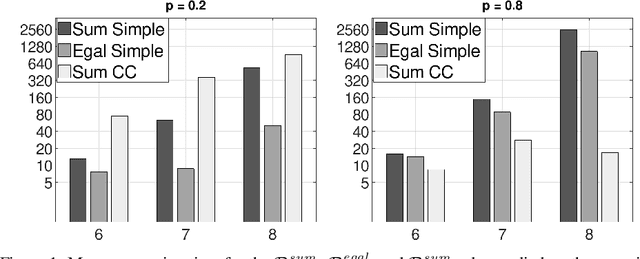
Many important collective decision-making problems can be seen as multi-agent versions of discrete optimisation problems. Participatory budgeting, for instance, is the collective version of the knapsack problem; other examples include collective scheduling, and collective spanning trees. Rather than developing a specific model, as well as specific algorithmic techniques, for each of these problems, we propose to represent and solve them in the unifying framework of judgment aggregation with weighted issues. We provide a modular definition of collective discrete optimisation (CDO) rules based on coupling a set scoring function with an operator, and we show how they generalise several existing procedures developed for specific CDO problems. We also give an implementation based on integer linear programming (ILP) and test it on the problem of collective spanning trees.
Computing and Testing Pareto Optimal Committees
Mar 18, 2018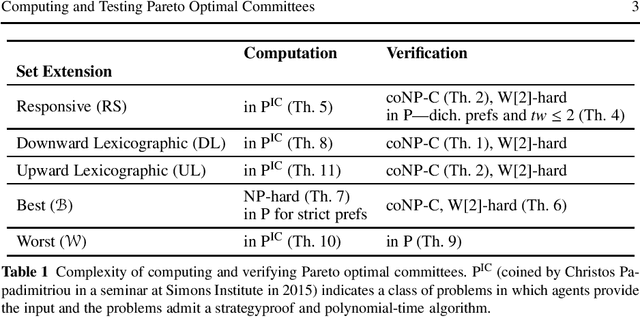
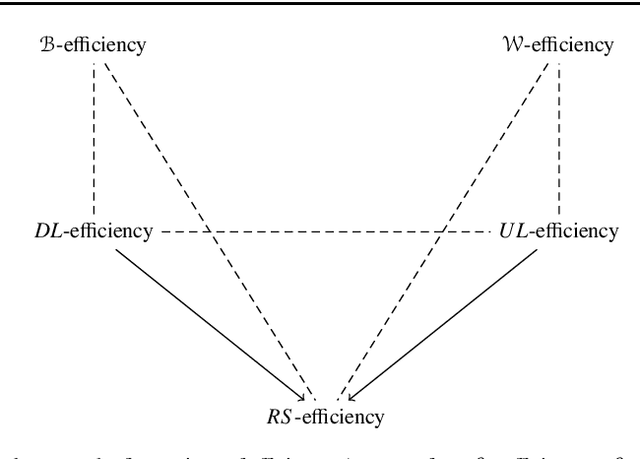
Selecting a set of alternatives based on the preferences of agents is an important problem in committee selection and beyond. Among the various criteria put forth for the desirability of a committee, Pareto optimality is a minimal and important requirement. As asking agents to specify their preferences over exponentially many subsets of alternatives is practically infeasible, we assume that each agent specifies a weak order on single alternatives, from which a preference relation over subsets is derived using some preference extension. We consider five prominent extensions (responsive, downward lexicographic, upward lexicographic, best, and worst). For each of them, we consider the corresponding Pareto optimality notion, and we study the complexity of computing and verifying Pareto optimal outcomes. We also consider strategic issues: for four of the set extensions, we present a linear-time, Pareto optimal and strategyproof algorithm that even works for weak preferences.
Finding a Collective Set of Items: From Proportional Multirepresentation to Group Recommendation
Jan 08, 2016
We consider the following problem: There is a set of items (e.g., movies) and a group of agents (e.g., passengers on a plane); each agent has some intrinsic utility for each of the items. Our goal is to pick a set of $K$ items that maximize the total derived utility of all the agents (i.e., in our example we are to pick $K$ movies that we put on the plane's entertainment system). However, the actual utility that an agent derives from a given item is only a fraction of its intrinsic one, and this fraction depends on how the agent ranks the item among the chosen, available, ones. We provide a formal specification of the model and provide concrete examples and settings where it is applicable. We show that the problem is hard in general, but we show a number of tractability results for its natural special cases.
Multi-Attribute Proportional Representation
Sep 11, 2015
We consider the following problem in which a given number of items has to be chosen from a predefined set. Each item is described by a vector of attributes and for each attribute there is a desired distribution that the selected set should have. We look for a set that fits as much as possible the desired distributions on all attributes. Examples of applications include choosing members of a representative committee, where candidates are described by attributes such as sex, age and profession, and where we look for a committee that for each attribute offers a certain representation, i.e., a single committee that contains a certain number of young and old people, certain number of men and women, certain number of people with different professions, etc. With a single attribute the problem collapses to the apportionment problem for party-list proportional representation systems (in such case the value of the single attribute would be a political affiliation of a candidate). We study the properties of the associated subset selection rules, as well as their computation complexity.
The Computational Complexity of Dominance and Consistency in CP-Nets
Jan 15, 2014We investigate the computational complexity of testing dominance and consistency in CP-nets. Previously, the complexity of dominance has been determined for restricted classes in which the dependency graph of the CP-net is acyclic. However, there are preferences of interest that define cyclic dependency graphs; these are modeled with general CP-nets. In our main results, we show here that both dominance and consistency for general CP-nets are PSPACE-complete. We then consider the concept of strong dominance, dominance equivalence and dominance incomparability, and several notions of optimality, and identify the complexity of the corresponding decision problems. The reductions used in the proofs are from STRIPS planning, and thus reinforce the earlier established connections between both areas.
Knowledge-Based Programs as Plans: Succinctness and the Complexity of Plan Existence
Oct 23, 2013Knowledge-based programs (KBPs) are high-level protocols describing the course of action an agent should perform as a function of its knowledge. The use of KBPs for expressing action policies in AI planning has been surprisingly overlooked. Given that to each KBP corresponds an equivalent plan and vice versa, KBPs are typically more succinct than standard plans, but imply more on-line computation time. Here we make this argument formal, and prove that there exists an exponential succinctness gap between knowledge-based programs and standard plans. Then we address the complexity of plan existence. Some results trivially follow from results already known from the literature on planning under incomplete knowledge, but many were unknown so far.
Automated Reasoning Using Possibilistic Logic: Semantics, Belief Revision and Variable Certainty Weights
Mar 27, 2013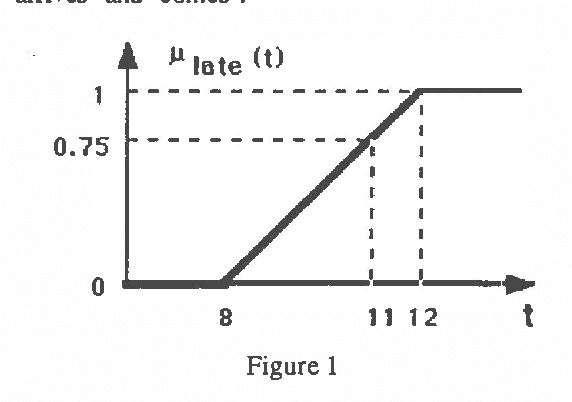
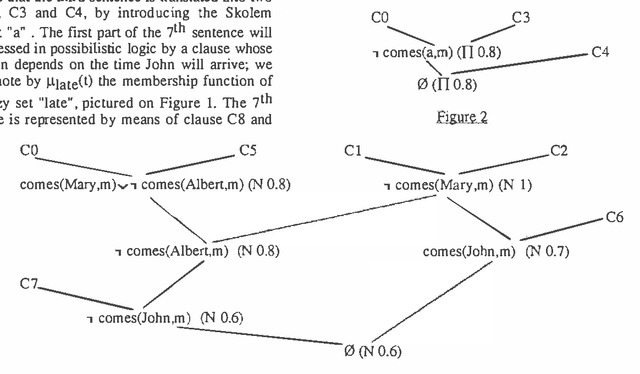
In this paper an approach to automated deduction under uncertainty,based on possibilistic logic, is proposed ; for that purpose we deal with clauses weighted by a degree which is a lower bound of a necessity or a possibility measure, according to the nature of the uncertainty. Two resolution rules are used for coping with the different situations, and the refutation method can be generalized. Besides the lower bounds are allowed to be functions of variables involved in the clause, which gives hypothetical reasoning capabilities. The relation between our approach and the idea of minimizing abnormality is briefly discussed. In case where only lower bounds of necessity measures are involved, a semantics is proposed, in which the completeness of the extended resolution principle is proved. Moreover deduction from a partially inconsistent knowledge base can be managed in this approach and displays some form of non-monotonicity.
A Logic of Graded Possibility and Certainty Coping with Partial Inconsistency
Mar 20, 2013A semantics is given to possibilistic logic, a logic that handles weighted classical logic formulae, and where weights are interpreted as lower bounds on degrees of certainty or possibility, in the sense of Zadeh's possibility theory. The proposed semantics is based on fuzzy sets of interpretations. It is tolerant to partial inconsistency. Satisfiability is extended from interpretations to fuzzy sets of interpretations, each fuzzy set representing a possibility distribution describing what is known about the state of the world. A possibilistic knowledge base is then viewed as a set of possibility distributions that satisfy it. The refutation method of automated deduction in possibilistic logic, based on previously introduced generalized resolution principle is proved to be sound and complete with respect to the proposed semantics, including the case of partial inconsistency.
Possibilistic decreasing persistence
Mar 06, 2013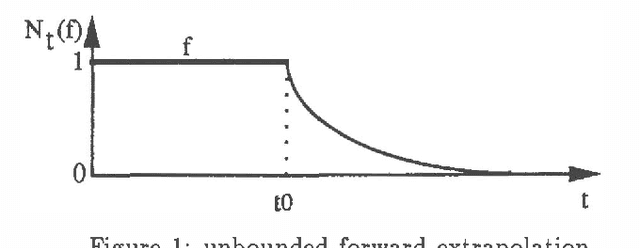
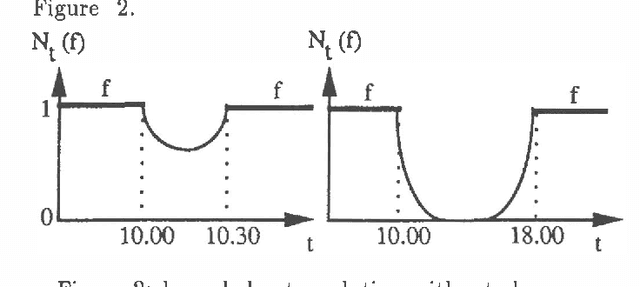
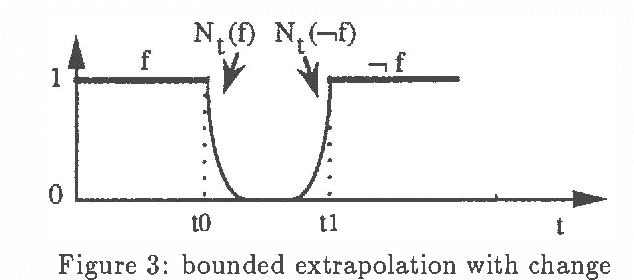

A key issue in the handling of temporal data is the treatment of persistence; in most approaches it consists in inferring defeasible confusions by extrapolating from the actual knowledge of the history of the world; we propose here a gradual modelling of persistence, following the idea that persistence is decreasing (the further we are from the last time point where a fluent is known to be true, the less certainly true the fluent is); it is based on possibility theory, which has strong relations with other well-known ordering-based approaches to nonmonotonic reasoning. We compare our approach with Dean and Kanazawa's probabilistic projection. We give a formal modelling of the decreasing persistence problem. Lastly, we show how to infer nonmonotonic conclusions using the principle of decreasing persistence.
Syntax-based Default Reasoning as Probabilistic Model-based Diagnosis
Feb 27, 2013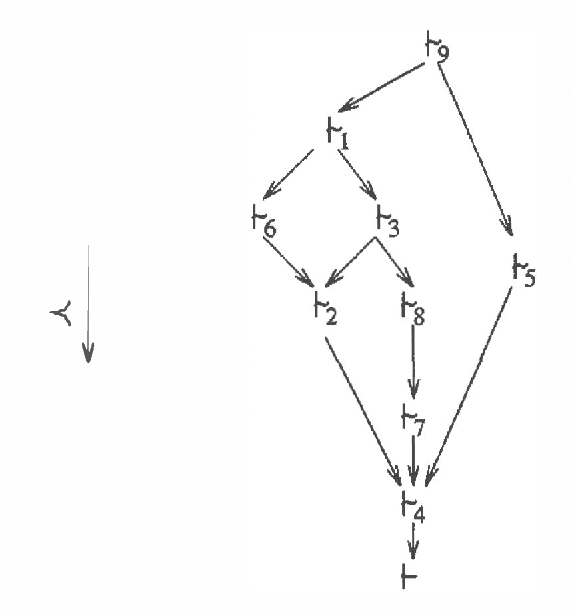
We view the syntax-based approaches to default reasoning as a model-based diagnosis problem, where each source giving a piece of information is considered as a component. It is formalized in the ATMS framework (each source corresponds to an assumption). We assume then that all sources are independent and "fail" with a very small probability. This leads to a probability assignment on the set of candidates, or equivalently on the set of consistent environments. This probability assignment induces a Dempster-Shafer belief function which measures the probability that a proposition can be deduced from the evidence. This belief function can be used in several different ways to define a non-monotonic consequence relation. We study and compare these consequence relations. The -case of prioritized knowledge bases is briefly considered.