 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Accuracy and Low-Latency Speech Recognition with Two-Head Contextual Layer Trajectory LSTM Model
Paper and Code
Mar 17, 2020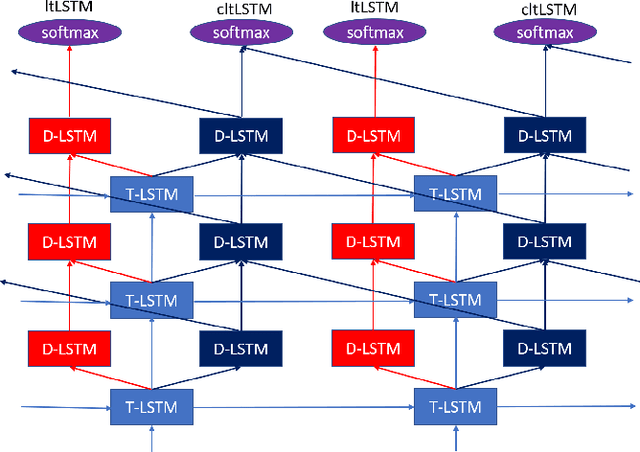

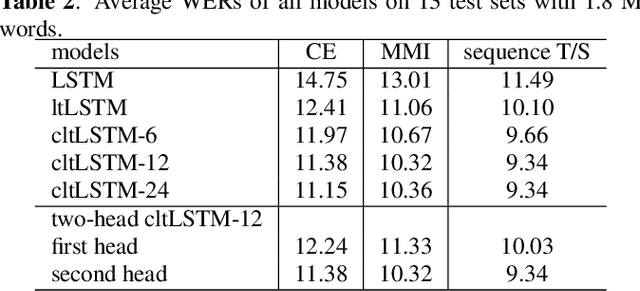

While the community keeps promoting end-to-end models over conventional hybrid models, which usually are long short-term memory (LSTM) models trained with a cross entropy criterion followed by a sequence discriminative training criterion, we argue that such conventional hybrid models can still be significantly improved. In this paper, we detail our recent efforts to improve conventional hybrid LSTM acoustic models for high-accuracy and low-latency automatic speech recognition. To achieve high accuracy, we use a contextual layer trajectory LSTM (cltLSTM), which decouples the temporal modeling and target classification tasks, and incorporates future context frames to get more information for accurate acoustic modeling. We further improve the training strategy with sequence-level teacher-student learning. To obtain low latency, we design a two-head cltLSTM, in which one head has zero latency and the other head has a small latency, compared to an LSTM. When trained with Microsoft's 65 thousand hours of anonymized training data and evaluated with test sets with 1.8 million words, the proposed two-head cltLSTM model with the proposed training strategy yields a 28.2\% relative WER reduction over the conventional LSTM acoustic model, with a similar perceived latency.