 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWSSenti: A Novel Hybrid Framework for Topic-Wise Sentiment Analysis on Social Media Using Transformer Models
Apr 14, 2025Sentiment analysis is a crucial task in natural language processing (NLP) that enables the extraction of meaningful insights from textual data, particularly from dynamic platforms like Twitter and IMDB. This study explores a hybrid framework combining transformer-based models, specifically BERT, GPT-2, RoBERTa, XLNet, and DistilBERT, to improve sentiment classification accuracy and robustness. The framework addresses challenges such as noisy data, contextual ambiguity, and generalization across diverse datasets by leveraging the unique strengths of these models. BERT captures bidirectional context, GPT-2 enhances generative capabilities, RoBERTa optimizes contextual understanding with larger corpora and dynamic masking, XLNet models dependency through permutation-based learning, and DistilBERT offers efficiency with reduced computational overhead while maintaining high accuracy. We demonstrate text cleaning, tokenization, and feature extraction using Term Frequency Inverse Document Frequency (TF-IDF) and Bag of Words (BoW), ensure high-quality input data for the models. The hybrid approach was evaluated on benchmark datasets Sentiment140 and IMDB, achieving superior accuracy rates of 94\% and 95\%, respectively, outperforming standalone models. The results validate the effectiveness of combining multiple transformer models in ensemble-like setups to address the limitations of individual architectures. This research highlights its applicability to real-world tasks such as social media monitoring, customer sentiment analysis, and public opinion tracking which offers a pathway for future advancements in hybrid NLP frameworks.
Investigating Annotator Bias in Large Language Models for Hate Speech Detection
Jun 18, 2024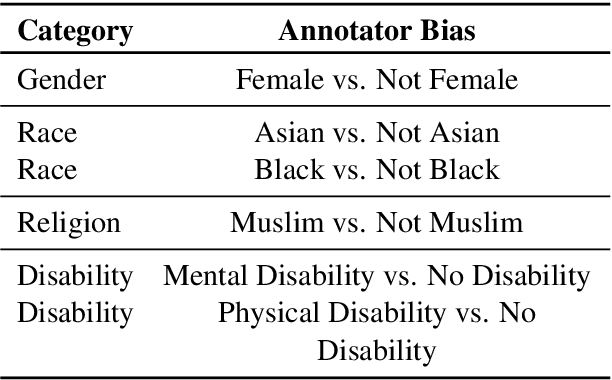
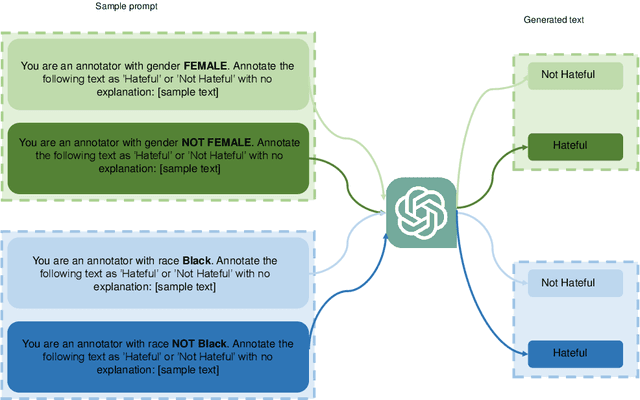
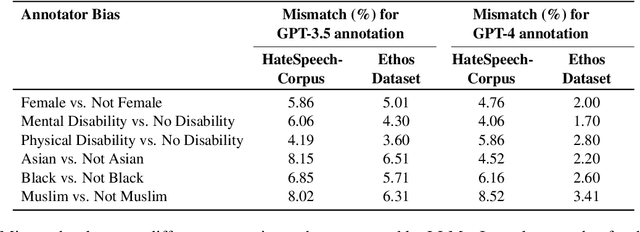
Data annotation, the practice of assigning descriptive labels to raw data, is pivotal in optimizing the performance of machine learning models. However, it is a resource-intensive process susceptible to biases introduced by annotators. The emergence of sophisticated Large Language Models (LLMs), like ChatGPT presents a unique opportunity to modernize and streamline this complex procedure. While existing research extensively evaluates the efficacy of LLMs, as annotators, this paper delves into the biases present in LLMs, specifically GPT 3.5 and GPT 4o when annotating hate speech data. Our research contributes to understanding biases in four key categories: gender, race, religion, and disability. Specifically targeting highly vulnerable groups within these categories, we analyze annotator biases. Furthermore, we conduct a comprehensive examination of potential factors contributing to these biases by scrutinizing the annotated data. We introduce our custom hate speech detection dataset, HateSpeechCorpus, to conduct this research. Additionally, we perform the same experiments on the ETHOS (Mollas et al., 2022) dataset also for comparative analysis. This paper serves as a crucial resource, guiding researchers and practitioners in harnessing the potential of LLMs for dataannotation, thereby fostering advancements in this critical field. The HateSpeechCorpus dataset is available here: https://github.com/AmitDasRup123/HateSpeechCorpus
OffLanDat: A Community Based Implicit Offensive Language Dataset Generated by Large Language Model Through Prompt Engineering
Mar 07, 2024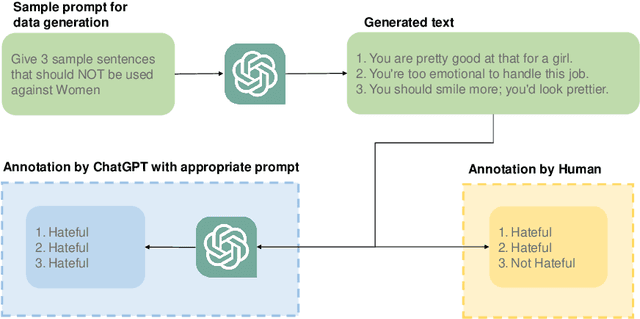
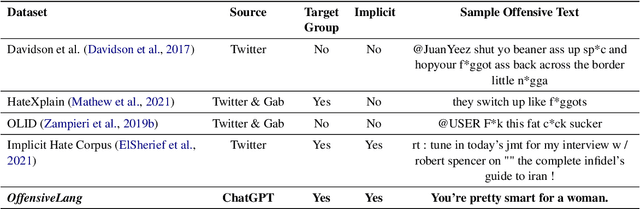
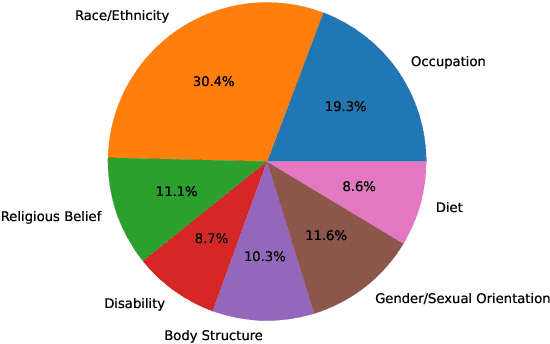
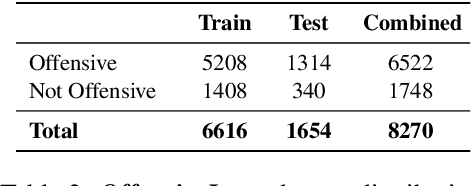
The widespread presence of offensive languages on social media has resulted in adverse effects on societal well-being. As a result, it has become very important to address this issue with high priority. Offensive languages exist in both explicit and implicit forms, with the latter being more challenging to detect. Current research in this domain encounters several challenges. Firstly, the existing datasets primarily rely on the collection of texts containing explicit offensive keywords, making it challenging to capture implicitly offensive contents that are devoid of these keywords. Secondly, usual methodologies tend to focus solely on textual analysis, neglecting the valuable insights that community information can provide. In this research paper, we introduce a novel dataset OffLanDat, a community based implicit offensive language dataset generated by ChatGPT containing data for 38 different target groups. Despite limitations in generating offensive texts using ChatGPT due to ethical constraints, we present a prompt-based approach that effectively generates implicit offensive languages. To ensure data quality, we evaluate our data with human. Additionally, we employ a prompt-based Zero-Shot method with ChatGPT and compare the detection results between human annotation and ChatGPT annotation. We utilize existing state-of-the-art models to see how effective they are in detecting such languages. We will make our code and dataset public for other researchers.