 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Acoustic-to-Word CTC Model
Paper and Code
Mar 15, 2018
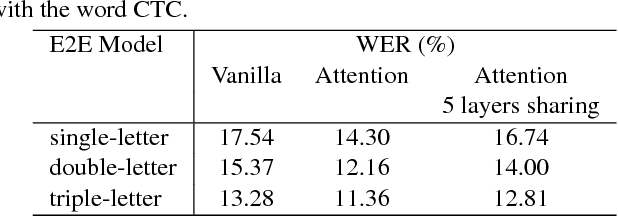


The acoustic-to-word model based on the connectionist temporal classification (CTC) criterion was shown as a natural end-to-end (E2E) model directly targeting words as output units. However, the word-based CTC model suffers from the out-of-vocabulary (OOV) issue as it can only model limited number of words in the output layer and maps all the remaining words into an OOV output node. Hence, such a word-based CTC model can only recognize the frequent words modeled by the network output nodes. Our first attempt to improve the acoustic-to-word model is a hybrid CTC model which consults a letter-based CTC when the word-based CTC model emits OOV tokens during testing time. Then, we propose a much better solution by training a mixed-unit CTC model which decomposes all the OOV words into sequences of frequent words and multi-letter units. Evaluated on a 3400 hours Microsoft Cortana voice assistant task, the final acoustic-to-word solution improves the baseline word-based CTC by relative 12.09% word error rate (WER) reduction when combined with our proposed attention CTC. Such an E2E model without using any language model (LM) or complex decoder outperforms the traditional context-dependent phoneme CTC which has strong LM and decoder by relative 6.79%.