 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Retrieval-augmented Text-to-SQL with AST-based Ranking and Schema Pruning
Jul 03, 2024

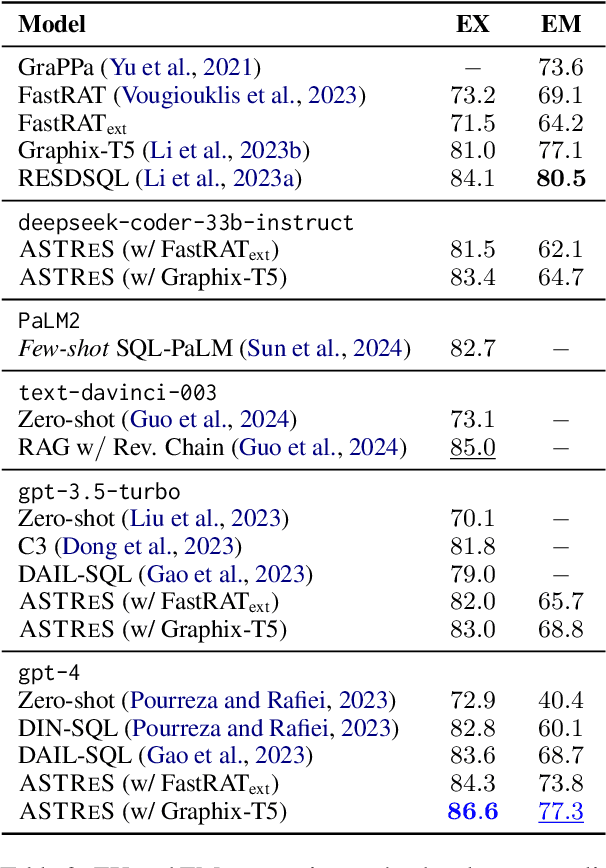

We focus on Text-to-SQL semantic parsing from the perspective of Large Language Models. Motivated by challenges related to the size of commercial database schemata and the deployability of business intelligence solutions, we propose an approach that dynamically retrieves input database information and uses abstract syntax trees to select few-shot examples for in-context learning. Furthermore, we investigate the extent to which an in-parallel semantic parser can be leveraged for generating $\textit{approximated}$ versions of the expected SQL queries, to support our retrieval. We take this approach to the extreme--we adapt a model consisting of less than $500$M parameters, to act as an extremely efficient approximator, enhancing it with the ability to process schemata in a parallelised manner. We apply our approach to monolingual and cross-lingual benchmarks for semantic parsing, showing improvements over state-of-the-art baselines. Comprehensive experiments highlight the contribution of modules involved in this retrieval-augmented generation setting, revealing interesting directions for future work.