 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Open-Domain Table Question Answering via Syntax- and Structure-aware Dense Retrieval
Sep 19, 2023



Open-domain table question answering aims to provide answers to a question by retrieving and extracting information from a large collection of tables. Existing studies of open-domain table QA either directly adopt text retrieval methods or consider the table structure only in the encoding layer for table retrieval, which may cause syntactical and structural information loss during table scoring. To address this issue, we propose a syntax- and structure-aware retrieval method for the open-domain table QA task. It provides syntactical representations for the question and uses the structural header and value representations for the tables to avoid the loss of fine-grained syntactical and structural information. Then, a syntactical-to-structural aggregator is used to obtain the matching score between the question and a candidate table by mimicking the human retrieval process. Experimental results show that our method achieves the state-of-the-art on the NQ-tables dataset and overwhelms strong baselines on a newly curated open-domain Text-to-SQL dataset.
A Survey on Table Question Answering: Recent Advances
Jul 12, 2022
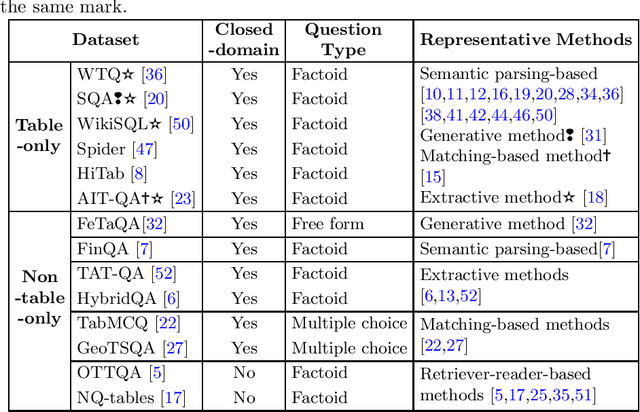


Table Question Answering (Table QA) refers to providing precise answers from tables to answer a user's question. In recent years, there have been a lot of works on table QA, but there is a lack of comprehensive surveys on this research topic. Hence, we aim to provide an overview of available datasets and representative methods in table QA. We classify existing methods for table QA into five categories according to their techniques, which include semantic-parsing-based, generative, extractive, matching-based, and retriever-reader-based methods. Moreover, as table QA is still a challenging task for existing methods, we also identify and outline several key challenges and discuss the potential future directions of table QA.