 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Graph Convolutional Networks with Redundancy-Free Neighbors
Apr 21, 2025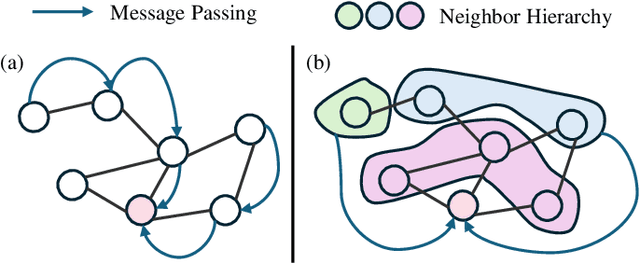
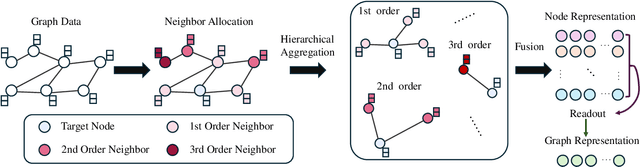
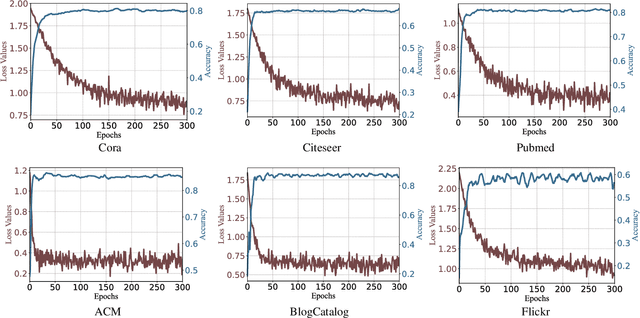
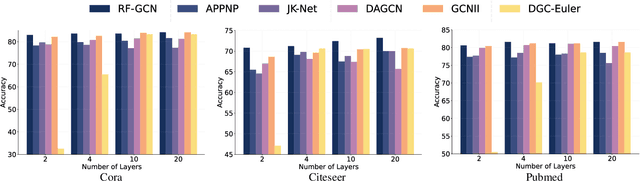
In recent years, Graph Convolutional Networks (GCNs) have gained popularity for their exceptional ability to process graph-structured data. Existing GCN-based approaches typically employ a shallow model architecture due to the over-smoothing phenomenon. Current approaches to mitigating over-smoothing primarily involve adding supplementary components to GCN architectures, such as residual connections and random edge-dropping strategies. However, these improvements toward deep GCNs have achieved only limited success. In this work, we analyze the intrinsic message passing mechanism of GCNs and identify a critical issue: messages originating from high-order neighbors must traverse through low-order neighbors to reach the target node. This repeated reliance on low-order neighbors leads to redundant information aggregation, a phenomenon we term over-aggregation. Our analysis demonstrates that over-aggregation not only introduces significant redundancy but also serves as the fundamental cause of over-smoothing in GCNs.
SpreadFGL: Edge-Client Collaborative Federated Graph Learning with Adaptive Neighbor Generation
Jul 14, 2024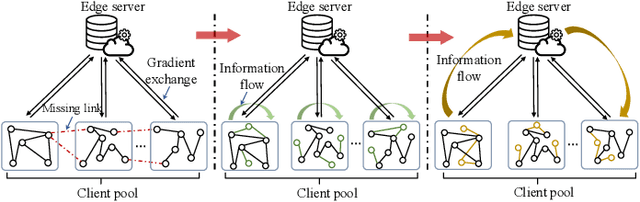
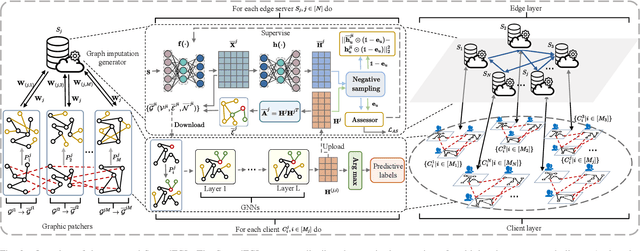
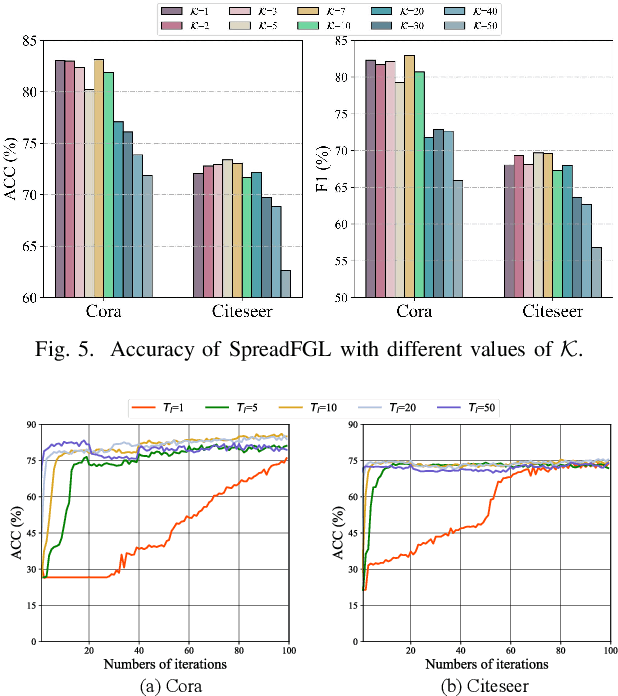
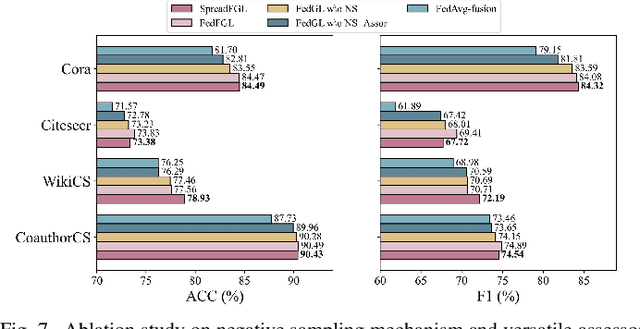
Federated Graph Learning (FGL) has garnered widespread attention by enabling collaborative training on multiple clients for semi-supervised classification tasks. However, most existing FGL studies do not well consider the missing inter-client topology information in real-world scenarios, causing insufficient feature aggregation of multi-hop neighbor clients during model training. Moreover, the classic FGL commonly adopts the FedAvg but neglects the high training costs when the number of clients expands, resulting in the overload of a single edge server. To address these important challenges, we propose a novel FGL framework, named SpreadFGL, to promote the information flow in edge-client collaboration and extract more generalized potential relationships between clients. In SpreadFGL, an adaptive graph imputation generator incorporated with a versatile assessor is first designed to exploit the potential links between subgraphs, without sharing raw data. Next, a new negative sampling mechanism is developed to make SpreadFGL concentrate on more refined information in downstream tasks. To facilitate load balancing at the edge layer, SpreadFGL follows a distributed training manner that enables fast model convergence. Using real-world testbed and benchmark graph datasets, extensive experiments demonstrate the effectiveness of the proposed SpreadFGL. The results show that SpreadFGL achieves higher accuracy and faster convergence against state-of-the-art algorithms.