 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting-Led Evolutionary Algorithm for Large-Scale Multi-Objective VNF Placement Problems
Dec 17, 2025Modern data centers contain thousands of servers making them major consumers of electricity. To minimize their environmental impact, it is critical that we use their resources efficiently. In this paper we study how to discover the optimal placement of virtual network functions in large scale data centers. We propose a novel parallel metaheuristic, fast heuristic objective functions of the QoS and new memory efficient data structures for large networks. We further identify a simple, fast heuristic that can produce competitive solutions to very large problem instances. Using these new concepts, we are able to find high quality solutions for data centres with up to 64,000 servers.
SpreadFGL: Edge-Client Collaborative Federated Graph Learning with Adaptive Neighbor Generation
Jul 14, 2024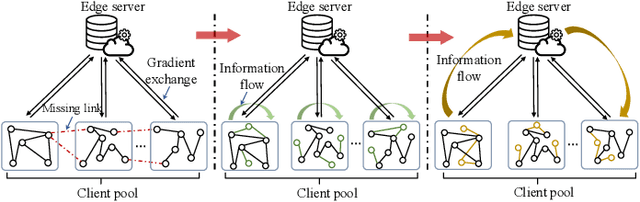
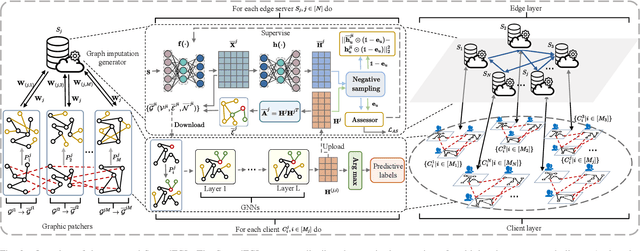
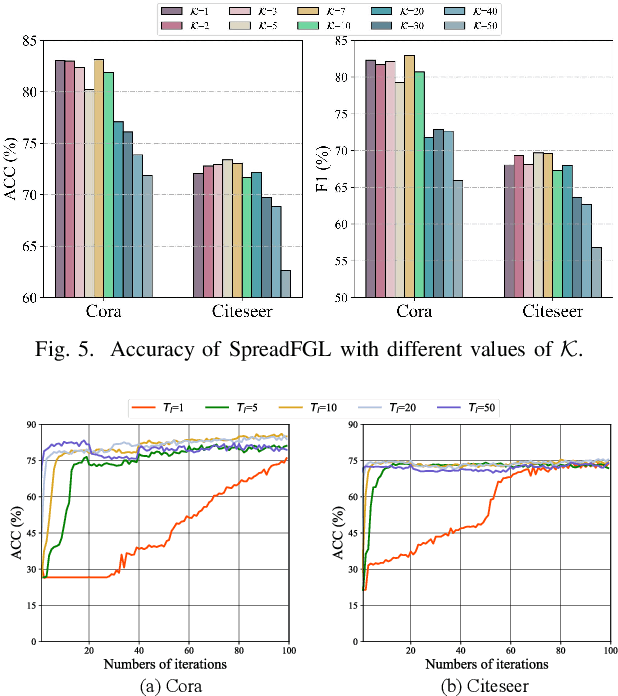
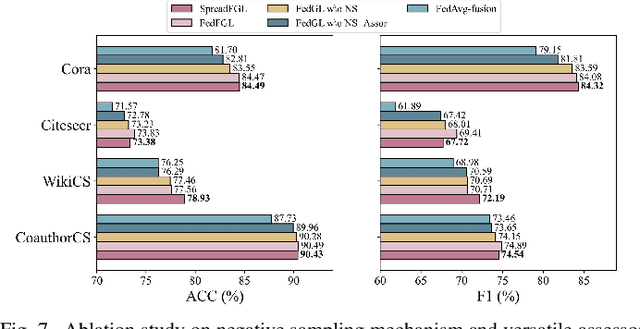
Federated Graph Learning (FGL) has garnered widespread attention by enabling collaborative training on multiple clients for semi-supervised classification tasks. However, most existing FGL studies do not well consider the missing inter-client topology information in real-world scenarios, causing insufficient feature aggregation of multi-hop neighbor clients during model training. Moreover, the classic FGL commonly adopts the FedAvg but neglects the high training costs when the number of clients expands, resulting in the overload of a single edge server. To address these important challenges, we propose a novel FGL framework, named SpreadFGL, to promote the information flow in edge-client collaboration and extract more generalized potential relationships between clients. In SpreadFGL, an adaptive graph imputation generator incorporated with a versatile assessor is first designed to exploit the potential links between subgraphs, without sharing raw data. Next, a new negative sampling mechanism is developed to make SpreadFGL concentrate on more refined information in downstream tasks. To facilitate load balancing at the edge layer, SpreadFGL follows a distributed training manner that enables fast model convergence. Using real-world testbed and benchmark graph datasets, extensive experiments demonstrate the effectiveness of the proposed SpreadFGL. The results show that SpreadFGL achieves higher accuracy and faster convergence against state-of-the-art algorithms.
Automating the Selection of Proxy Variables of Unmeasured Confounders
May 25, 2024



Recently, interest has grown in the use of proxy variables of unobserved confounding for inferring the causal effect in the presence of unmeasured confounders from observational data. One difficulty inhibiting the practical use is finding valid proxy variables of unobserved confounding to a target causal effect of interest. These proxy variables are typically justified by background knowledge. In this paper, we investigate the estimation of causal effects among multiple treatments and a single outcome, all of which are affected by unmeasured confounders, within a linear causal model, without prior knowledge of the validity of proxy variables. To be more specific, we first extend the existing proxy variable estimator, originally addressing a single unmeasured confounder, to accommodate scenarios where multiple unmeasured confounders exist between the treatments and the outcome. Subsequently, we present two different sets of precise identifiability conditions for selecting valid proxy variables of unmeasured confounders, based on the second-order statistics and higher-order statistics of the data, respectively. Moreover, we propose two data-driven methods for the selection of proxy variables and for the unbiased estimation of causal effects. Theoretical analysis demonstrates the correctness of our proposed algorithms. Experimental results on both synthetic and real-world data show the effectiveness of the proposed approach.
NAS-ASDet: An Adaptive Design Method for Surface Defect Detection Network using Neural Architecture Search
Nov 18, 2023



Deep convolutional neural networks (CNNs) have been widely used in surface defect detection. However, no CNN architecture is suitable for all detection tasks and designing effective task-specific requires considerable effort. The neural architecture search (NAS) technology makes it possible to automatically generate adaptive data-driven networks. Here, we propose a new method called NAS-ASDet to adaptively design network for surface defect detection. First, a refined and industry-appropriate search space that can adaptively adjust the feature distribution is designed, which consists of repeatedly stacked basic novel cells with searchable attention operations. Then, a progressive search strategy with a deep supervision mechanism is used to explore the search space faster and better. This method can design high-performance and lightweight defect detection networks with data scarcity in industrial scenarios. The experimental results on four datasets demonstrate that the proposed method achieves superior performance and a relatively lighter model size compared to other competitive methods, including both manual and NAS-based approaches.
Routing-Led Placement of VNFs in Arbitrary Networks
Jan 30, 2020

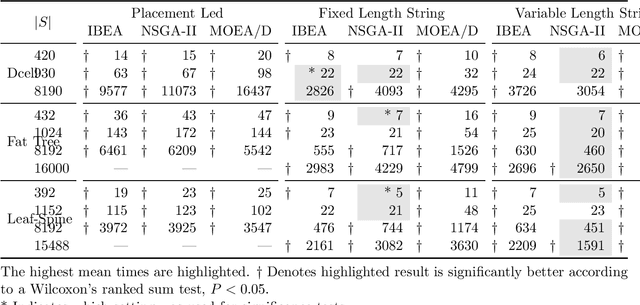
The ever increasing demand for computing resources has led to the creation of hyperscale datacentres with tens of thousands of servers. As demand continues to rise, new technologies must be incorporated to ensure high quality services can be provided without the damaging environmental impact of high energy consumption. Virtualisation technology such as network function virtualisation (NFV) allows for the creation of services by connecting component parts known as virtual network functions (VNFs). VNFs cam be used to maximally utilise available datacentre resources by optimising the placement and routes of VNFs, to maintain a high quality of service whilst minimising energy costs. Current research on this problem has focussed on placing VNFs and considered routing as a secondary concern. In this work we argue that the opposite approach, a routing-led approach is preferable. We propose a novel routing-led algorithm and analyse each of the component parts over a range of different topologies on problems with up to 16000 variables and compare its performance against a traditional placement based algorithm. Empirical results show that our routing-led algorithm can produce significantly better, faster solutions to large problem instances on a range of datacentre topologies.