 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReXGradient-160K: A Large-Scale Publicly Available Dataset of Chest Radiographs with Free-text Reports
May 01, 2025

We present ReXGradient-160K, representing the largest publicly available chest X-ray dataset to date in terms of the number of patients. This dataset contains 160,000 chest X-ray studies with paired radiological reports from 109,487 unique patients across 3 U.S. health systems (79 medical sites). This comprehensive dataset includes multiple images per study and detailed radiology reports, making it particularly valuable for the development and evaluation of AI systems for medical imaging and automated report generation models. The dataset is divided into training (140,000 studies), validation (10,000 studies), and public test (10,000 studies) sets, with an additional private test set (10,000 studies) reserved for model evaluation on the ReXrank benchmark. By providing this extensive dataset, we aim to accelerate research in medical imaging AI and advance the state-of-the-art in automated radiological analysis. Our dataset will be open-sourced at https://huggingface.co/datasets/rajpurkarlab/ReXGradient-160K.
ReXrank: A Public Leaderboard for AI-Powered Radiology Report Generation
Nov 22, 2024



AI-driven models have demonstrated significant potential in automating radiology report generation for chest X-rays. However, there is no standardized benchmark for objectively evaluating their performance. To address this, we present ReXrank, https://rexrank.ai, a public leaderboard and challenge for assessing AI-powered radiology report generation. Our framework incorporates ReXGradient, the largest test dataset consisting of 10,000 studies, and three public datasets (MIMIC-CXR, IU-Xray, CheXpert Plus) for report generation assessment. ReXrank employs 8 evaluation metrics and separately assesses models capable of generating only findings sections and those providing both findings and impressions sections. By providing this standardized evaluation framework, ReXrank enables meaningful comparisons of model performance and offers crucial insights into their robustness across diverse clinical settings. Beyond its current focus on chest X-rays, ReXrank's framework sets the stage for comprehensive evaluation of automated reporting across the full spectrum of medical imaging.
DIP-RL: Demonstration-Inferred Preference Learning in Minecraft
Jul 22, 2023

In machine learning for sequential decision-making, an algorithmic agent learns to interact with an environment while receiving feedback in the form of a reward signal. However, in many unstructured real-world settings, such a reward signal is unknown and humans cannot reliably craft a reward signal that correctly captures desired behavior. To solve tasks in such unstructured and open-ended environments, we present Demonstration-Inferred Preference Reinforcement Learning (DIP-RL), an algorithm that leverages human demonstrations in three distinct ways, including training an autoencoder, seeding reinforcement learning (RL) training batches with demonstration data, and inferring preferences over behaviors to learn a reward function to guide RL. We evaluate DIP-RL in a tree-chopping task in Minecraft. Results suggest that the method can guide an RL agent to learn a reward function that reflects human preferences and that DIP-RL performs competitively relative to baselines. DIP-RL is inspired by our previous work on combining demonstrations and pairwise preferences in Minecraft, which was awarded a research prize at the 2022 NeurIPS MineRL BASALT competition, Learning from Human Feedback in Minecraft. Example trajectory rollouts of DIP-RL and baselines are located at https://sites.google.com/view/dip-rl.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023

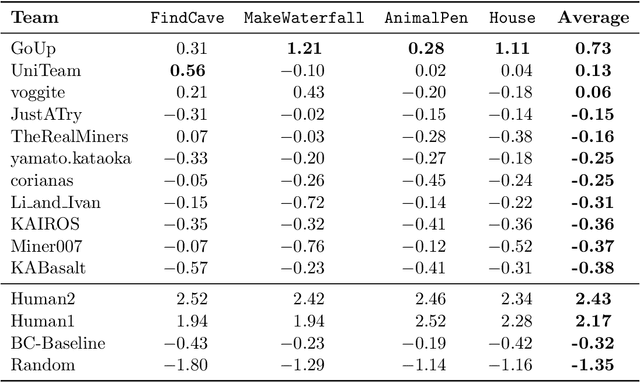
To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.