 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChordEdit: One-Step Low-Energy Transport for Image Editing
Feb 22, 2026The advent of one-step text-to-image (T2I) models offers unprecedented synthesis speed. However, their application to text-guided image editing remains severely hampered, as forcing existing training-free editors into a single inference step fails. This failure manifests as severe object distortion and a critical loss of consistency in non-edited regions, resulting from the high-energy, erratic trajectories produced by naive vector arithmetic on the models' structured fields. To address this problem, we introduce ChordEdit, a model agnostic, training-free, and inversion-free method that facilitates high-fidelity one-step editing. We recast editing as a transport problem between the source and target distributions defined by the source and target text prompts. Leveraging dynamic optimal transport theory, we derive a principled, low-energy control strategy. This strategy yields a smoothed, variance-reduced editing field that is inherently stable, facilitating the field to be traversed in a single, large integration step. A theoretically grounded and experimentally validated approach allows ChordEdit to deliver fast, lightweight and precise edits, finally achieving true real-time editing on these challenging models.
MMErroR: A Benchmark for Erroneous Reasoning in Vision-Language Models
Jan 06, 2026Recent advances in Vision-Language Models (VLMs) have improved performance in multi-modal learning, raising the question of whether these models truly understand the content they process. Crucially, can VLMs detect when a reasoning process is wrong and identify its error type? To answer this, we present MMErroR, a multi-modal benchmark of 2,013 samples, each embedding a single coherent reasoning error. These samples span 24 subdomains across six top-level domains, ensuring broad coverage and taxonomic richness. Unlike existing benchmarks that focus on answer correctness, MMErroR targets a process-level, error-centric evaluation that requires models to detect incorrect reasoning and classify the error type within both visual and linguistic contexts. We evaluate 20 advanced VLMs, even the best model (Gemini-3.0-Pro) classifies the error in only 66.47\% of cases, underscoring the challenge of identifying erroneous reasoning. Furthermore, the ability to accurately identify errors offers valuable insights into the capabilities of multi-modal reasoning models. Project Page: https://mmerror-benchmark.github.io
Exploring Low-Dimensional Subspaces in Diffusion Models for Controllable Image Editing
Sep 04, 2024
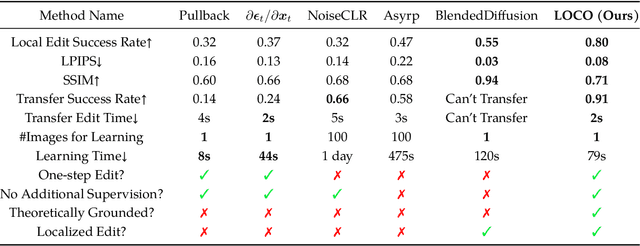
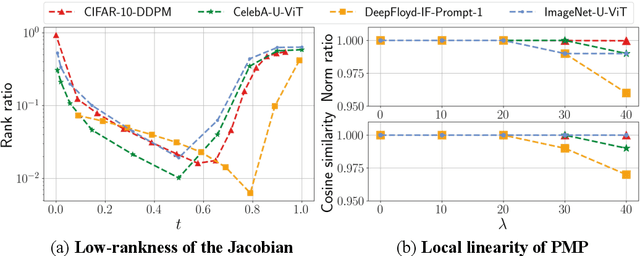
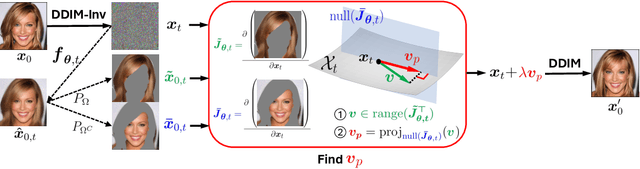
Recently, diffusion models have emerged as a powerful class of generative models. Despite their success, there is still limited understanding of their semantic spaces. This makes it challenging to achieve precise and disentangled image generation without additional training, especially in an unsupervised way. In this work, we improve the understanding of their semantic spaces from intriguing observations: among a certain range of noise levels, (1) the learned posterior mean predictor (PMP) in the diffusion model is locally linear, and (2) the singular vectors of its Jacobian lie in low-dimensional semantic subspaces. We provide a solid theoretical basis to justify the linearity and low-rankness in the PMP. These insights allow us to propose an unsupervised, single-step, training-free LOw-rank COntrollable image editing (LOCO Edit) method for precise local editing in diffusion models. LOCO Edit identified editing directions with nice properties: homogeneity, transferability, composability, and linearity. These properties of LOCO Edit benefit greatly from the low-dimensional semantic subspace. Our method can further be extended to unsupervised or text-supervised editing in various text-to-image diffusion models (T-LOCO Edit). Finally, extensive empirical experiments demonstrate the effectiveness and efficiency of LOCO Edit. The codes will be released at https://github.com/ChicyChen/LOCO-Edit.
The Emergence of Reproducibility and Consistency in Diffusion Models
Oct 08, 2023



Recently, diffusion models have emerged as powerful deep generative models, showcasing cutting-edge performance across various applications such as image generation, solving inverse problems, and text-to-image synthesis. These models generate new data (e.g., images) by transforming random noise inputs through a reverse diffusion process. In this work, we uncover a distinct and prevalent phenomenon within diffusion models in contrast to most other generative models, which we refer to as ``consistent model reproducibility''. To elaborate, our extensive experiments have consistently shown that when starting with the same initial noise input and sampling with a deterministic solver, diffusion models tend to produce nearly identical output content. This consistency holds true regardless of the choices of model architectures and training procedures. Additionally, our research has unveiled that this exceptional model reproducibility manifests in two distinct training regimes: (i) ``memorization regime,'' characterized by a significantly overparameterized model which attains reproducibility mainly by memorizing the training data; (ii) ``generalization regime,'' in which the model is trained on an extensive dataset, and its reproducibility emerges with the model's generalization capabilities. Our analysis provides theoretical justification for the model reproducibility in ``memorization regime''. Moreover, our research reveals that this valuable property generalizes to many variants of diffusion models, including conditional diffusion models, diffusion models for solving inverse problems, and fine-tuned diffusion models. A deeper understanding of this phenomenon has the potential to yield more interpretable and controllable data generative processes based on diffusion models.
Towards Robustness against Unsuspicious Adversarial Examples
May 08, 2020


Despite the remarkable success of deep neural networks, significant concerns have emerged about their robustness to adversarial perturbations to inputs. While most attacks aim to ensure that these are imperceptible, physical perturbation attacks typically aim for being unsuspicious, even if perceptible. However, there is no universal notion of what it means for adversarial examples to be unsuspicious. We propose an approach for modeling suspiciousness by leveraging cognitive salience. Specifically, we split an image into foreground (salient region) and background (the rest), and allow significantly larger adversarial perturbations in the background. We describe how to compute the resulting dual-perturbation attacks on both deterministic and stochastic classifiers. We then experimentally demonstrate that our attacks do not significantly change perceptual salience of the background, but are highly effective against classifiers robust to conventional attacks. Furthermore, we show that adversarial training with dual-perturbation attacks yields classifiers that are more robust to these than state-of-the-art robust learning approaches, and comparable in terms of robustness to conventional attacks.