 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Graph Neural Networks for Causal Discovery and Root Cause Localization
Feb 03, 2023



In this paper, we propose REASON, a novel framework that enables the automatic discovery of both intra-level (i.e., within-network) and inter-level (i.e., across-network) causal relationships for root cause localization. REASON consists of Topological Causal Discovery and Individual Causal Discovery. The Topological Causal Discovery component aims to model the fault propagation in order to trace back to the root causes. To achieve this, we propose novel hierarchical graph neural networks to construct interdependent causal networks by modeling both intra-level and inter-level non-linear causal relations. Based on the learned interdependent causal networks, we then leverage random walks with restarts to model the network propagation of a system fault. The Individual Causal Discovery component focuses on capturing abrupt change patterns of a single system entity. This component examines the temporal patterns of each entity's metric data (i.e., time series), and estimates its likelihood of being a root cause based on the Extreme Value theory. Combining the topological and individual causal scores, the top K system entities are identified as root causes. Extensive experiments on three real-world datasets with case studies demonstrate the effectiveness and superiority of the proposed framework.
Personalized Federated Learning via Heterogeneous Modular Networks
Oct 26, 2022Personalized Federated Learning (PFL) which collaboratively trains a federated model while considering local clients under privacy constraints has attracted much attention. Despite its popularity, it has been observed that existing PFL approaches result in sub-optimal solutions when the joint distribution among local clients diverges. To address this issue, we present Federated Modular Network (FedMN), a novel PFL approach that adaptively selects sub-modules from a module pool to assemble heterogeneous neural architectures for different clients. FedMN adopts a light-weighted routing hypernetwork to model the joint distribution on each client and produce the personalized selection of the module blocks for each client. To reduce the communication burden in existing FL, we develop an efficient way to interact between the clients and the server. We conduct extensive experiments on the real-world test beds and the results show both the effectiveness and efficiency of the proposed FedMN over the baselines.
FocusedCleaner: Sanitizing Poisoned Graphs for Robust GNN-based Node Classification
Oct 25, 2022



Recently, a lot of research attention has been devoted to exploring Web security, a most representative topic is the adversarial robustness of graph mining algorithms. Especially, a widely deployed adversarial attacks formulation is the graph manipulation attacks by modifying the relational data to mislead the Graph Neural Networks' (GNNs) predictions. Naturally, an intrinsic question one would ask is whether we can accurately identify the manipulations over graphs - we term this problem as poisoned graph sanitation. In this paper, we present FocusedCleaner, a poisoned graph sanitation framework consisting of two modules: bi-level structural learning and victim node detection. In particular, the structural learning module will reserve the attack process to steadily sanitize the graph while the detection module provides the "focus" - a narrowed and more accurate search region - to structural learning. These two modules will operate in iterations and reinforce each other to sanitize a poisoned graph step by step. Extensive experiments demonstrate that FocusedCleaner outperforms the state-of-the-art baselines both on poisoned graph sanitation and improving robustness.
FACESEC: A Fine-grained Robustness Evaluation Framework for Face Recognition Systems
Apr 08, 2021



We present FACESEC, a framework for fine-grained robustness evaluation of face recognition systems. FACESEC evaluation is performed along four dimensions of adversarial modeling: the nature of perturbation (e.g., pixel-level or face accessories), the attacker's system knowledge (about training data and learning architecture), goals (dodging or impersonation), and capability (tailored to individual inputs or across sets of these). We use FACESEC to study five face recognition systems in both closed-set and open-set settings, and to evaluate the state-of-the-art approach for defending against physically realizable attacks on these. We find that accurate knowledge of neural architecture is significantly more important than knowledge of the training data in black-box attacks. Moreover, we observe that open-set face recognition systems are more vulnerable than closed-set systems under different types of attacks. The efficacy of attacks for other threat model variations, however, appears highly dependent on both the nature of perturbation and the neural network architecture. For example, attacks that involve adversarial face masks are usually more potent, even against adversarially trained models, and the ArcFace architecture tends to be more robust than the others.
Towards Robustness against Unsuspicious Adversarial Examples
May 08, 2020
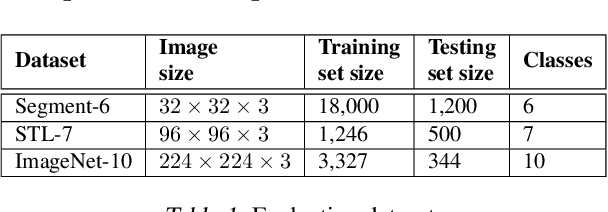


Despite the remarkable success of deep neural networks, significant concerns have emerged about their robustness to adversarial perturbations to inputs. While most attacks aim to ensure that these are imperceptible, physical perturbation attacks typically aim for being unsuspicious, even if perceptible. However, there is no universal notion of what it means for adversarial examples to be unsuspicious. We propose an approach for modeling suspiciousness by leveraging cognitive salience. Specifically, we split an image into foreground (salient region) and background (the rest), and allow significantly larger adversarial perturbations in the background. We describe how to compute the resulting dual-perturbation attacks on both deterministic and stochastic classifiers. We then experimentally demonstrate that our attacks do not significantly change perceptual salience of the background, but are highly effective against classifiers robust to conventional attacks. Furthermore, we show that adversarial training with dual-perturbation attacks yields classifiers that are more robust to these than state-of-the-art robust learning approaches, and comparable in terms of robustness to conventional attacks.
Defending Against Physically Realizable Attacks on Image Classification
Sep 20, 2019

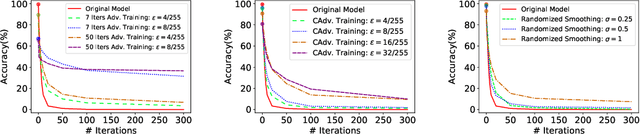

We study the problem of defending deep neural network approaches for image classification from physically realizable attacks. First, we demonstrate that the two most scalable and effective methods for learning robust models, adversarial training with PGD attacks and randomized smoothing, exhibit very limited effectiveness against three of the highest profile physical attacks. Next, we propose a new abstract adversarial model, rectangular occlusion attacks, in which an adversary places a small adversarially crafted rectangle in an image, and develop two approaches for efficiently computing the resulting adversarial examples. Finally, we demonstrate that adversarial training using our new attack yields image classification models that exhibit high robustness against the physically realizable attacks we study, offering the first effective generic defense against such attacks.
Finding Needles in a Moving Haystack: Prioritizing Alerts with Adversarial Reinforcement Learning
Jun 20, 2019


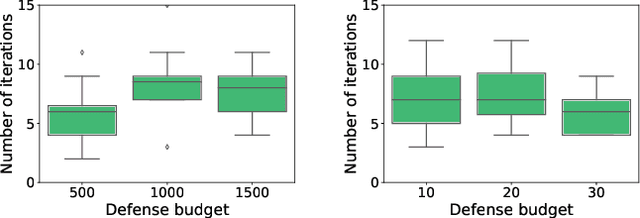
Detection of malicious behavior is a fundamental problem in security. One of the major challenges in using detection systems in practice is in dealing with an overwhelming number of alerts that are triggered by normal behavior (the so-called false positives), obscuring alerts resulting from actual malicious activity. While numerous methods for reducing the scope of this issue have been proposed, ultimately one must still decide how to prioritize which alerts to investigate, and most existing prioritization methods are heuristic, for example, based on suspiciousness or priority scores. We introduce a novel approach for computing a policy for prioritizing alerts using adversarial reinforcement learning. Our approach assumes that the attackers know the full state of the detection system and dynamically choose an optimal attack as a function of this state, as well as of the alert prioritization policy. The first step of our approach is to capture the interaction between the defender and attacker in a game theoretic model. To tackle the computational complexity of solving this game to obtain a dynamic stochastic alert prioritization policy, we propose an adversarial reinforcement learning framework. In this framework, we use neural reinforcement learning to compute best response policies for both the defender and the adversary to an arbitrary stochastic policy of the other. We then use these in a double-oracle framework to obtain an approximate equilibrium of the game, which in turn yields a robust stochastic policy for the defender. Extensive experiments using case studies in fraud and intrusion detection demonstrate that our approach is effective in creating robust alert prioritization policies.
A Framework for Validating Models of Evasion Attacks on Machine Learning, with Application to Malware Detection
Jun 13, 2018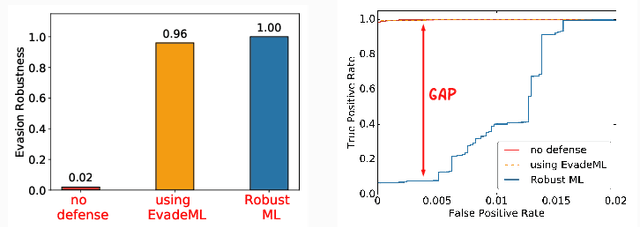
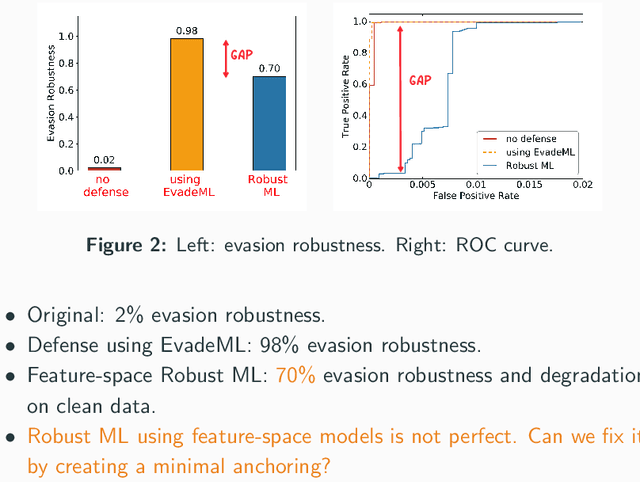
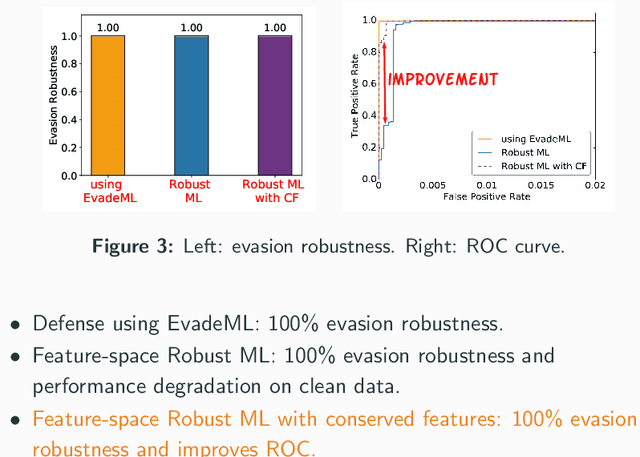
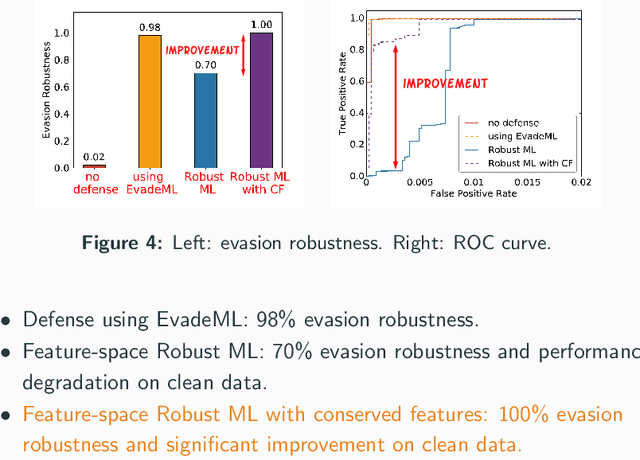
Machine learning (ML) techniques are increasingly common in security applications, such as malware and intrusion detection. However, there is increasing evidence that machine learning models are susceptible to evasion attacks, in which an adversary makes small changes to the input (such as malware) in order to cause erroneous predictions (for example, to avoid being detected). Evasion attacks on ML fall into two broad categories: 1) those which generate actual malicious instances and demonstrate both evasion of ML and efficacy of attack (we call these problem space attacks), and 2) attacks which directly manipulate features used by ML, abstracting efficacy of attack into a mathematical cost function (we call these feature space attacks). Central to our inquiry is the following fundamental question: are feature space models of attacks useful proxies for real attacks? In the process of answering this question, we make two major contributions: 1) a general methodology for evaluating validity of mathematical models of ML evasion attacks, and 2) an application of this methodology as a systematic hypothesis-driven evaluation of feature space evasion attacks on ML-based PDF malware detectors. Specific to our case study, we find that a) feature space evasion models are in general not adequate in representing real attacks, b) such models can be significantly improved by identifying conserved features (features that are invariant in real attacks) whenever these exist, and c) ML hardened using the improved feature space models remains robust to alternative attacks, in contrast to ML hardened using a very powerful class of problem space attacks, which does not.
Adversarial Regression with Multiple Learners
Jun 06, 2018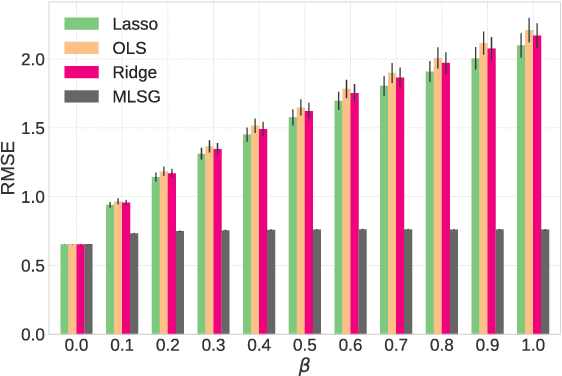
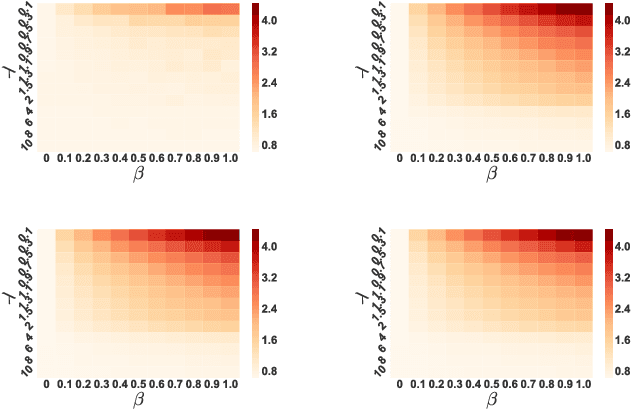
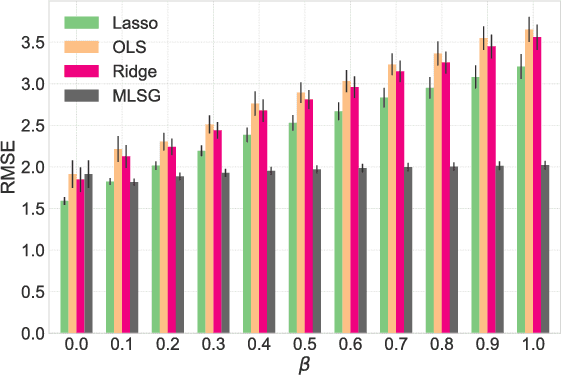
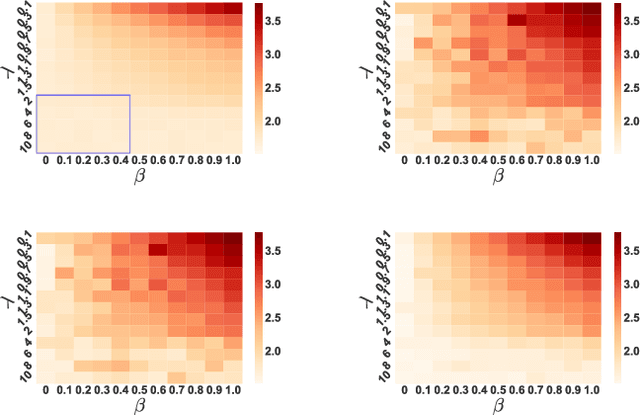
Despite the considerable success enjoyed by machine learning techniques in practice, numerous studies demonstrated that many approaches are vulnerable to attacks. An important class of such attacks involves adversaries changing features at test time to cause incorrect predictions. Previous investigations of this problem pit a single learner against an adversary. However, in many situations an adversary's decision is aimed at a collection of learners, rather than specifically targeted at each independently. We study the problem of adversarial linear regression with multiple learners. We approximate the resulting game by exhibiting an upper bound on learner loss functions, and show that the resulting game has a unique symmetric equilibrium. We present an algorithm for computing this equilibrium, and show through extensive experiments that equilibrium models are significantly more robust than conventional regularized linear regression.