 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Validating Models of Evasion Attacks on Machine Learning, with Application to Malware Detection
Paper and Code
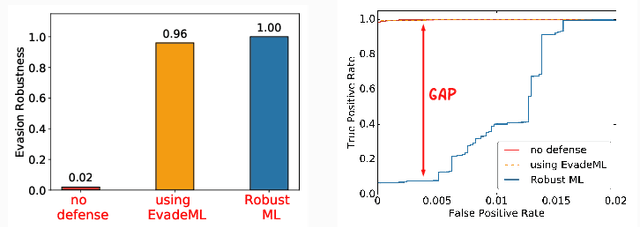
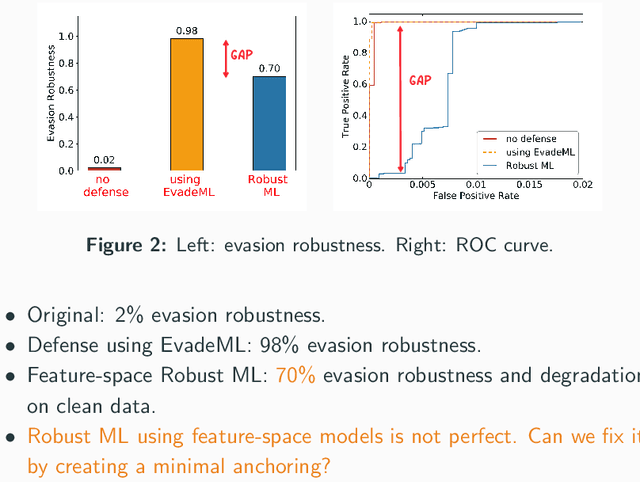
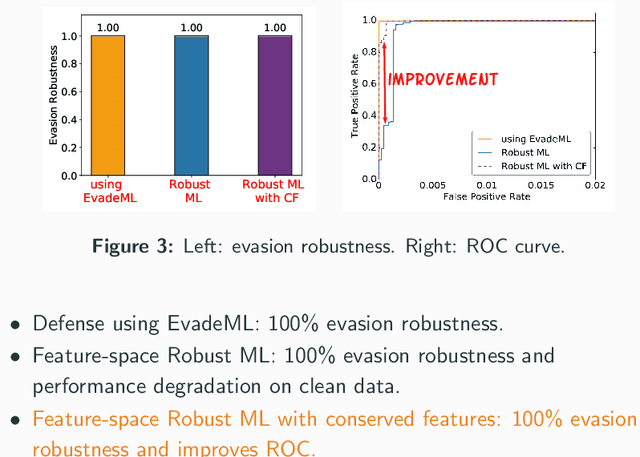
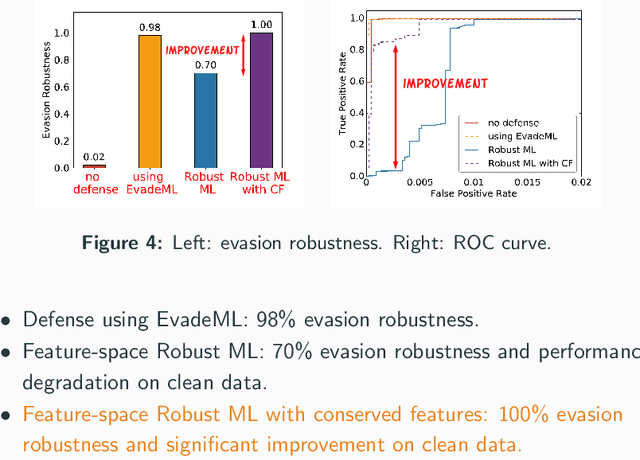
Machine learning (ML) techniques are increasingly common in security applications, such as malware and intrusion detection. However, there is increasing evidence that machine learning models are susceptible to evasion attacks, in which an adversary makes small changes to the input (such as malware) in order to cause erroneous predictions (for example, to avoid being detected). Evasion attacks on ML fall into two broad categories: 1) those which generate actual malicious instances and demonstrate both evasion of ML and efficacy of attack (we call these problem space attacks), and 2) attacks which directly manipulate features used by ML, abstracting efficacy of attack into a mathematical cost function (we call these feature space attacks). Central to our inquiry is the following fundamental question: are feature space models of attacks useful proxies for real attacks? In the process of answering this question, we make two major contributions: 1) a general methodology for evaluating validity of mathematical models of ML evasion attacks, and 2) an application of this methodology as a systematic hypothesis-driven evaluation of feature space evasion attacks on ML-based PDF malware detectors. Specific to our case study, we find that a) feature space evasion models are in general not adequate in representing real attacks, b) such models can be significantly improved by identifying conserved features (features that are invariant in real attacks) whenever these exist, and c) ML hardened using the improved feature space models remains robust to alternative attacks, in contrast to ML hardened using a very powerful class of problem space attacks, which does not.